在单链表中,只存在一个指向后继节点的指针域,这样只能沿着一个方向去查询其它节点。即,想要获取一个节点的后继节点时间复杂度是
O(1),但是获取其前置节点,其时间复杂度为O(N)。为了消除这种缺点,引入双向链表(double_linked_list)。
由于从双链表的单个节点可以很容易获取其前置和后继节点,所以一般删除或者插入都操作,都首先获取操作的节点,然后进行指针指向变换即可。
双链表节点,每个节点的指针域包含两个,一个指向前置节点,一个指向后置节点。
typedef struct double_linked_node
{
Element *element;
struct double_linked_node *prev;
struct double_linked_node *next;
} DoubleLinkedNode;结构如下图:

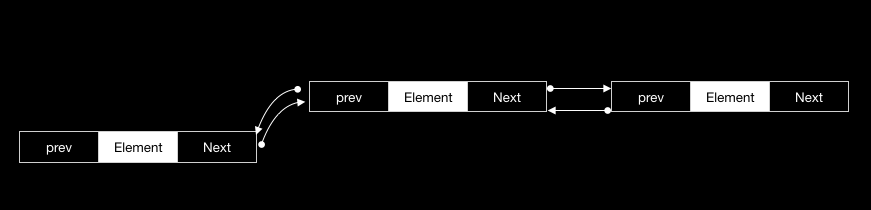
按照索引访问,由于该链表为双向链表,故可以从两个方向去遍历访问元素,因此可以简单的优化一下访问速度,使其所用时间较单链表平均提升一倍。提升的技巧,就是先判断其相对于中间元素的位置,然后决定其从左或者右开始进行访问。
DoubleLinkedNode *find_node(unsigned int index, DoubleLinkedList *list)
{
if (index > list->length)
{
return NULL;
}
if (index <= list->length / 2)
{
int i = 0;
DoubleLinkedNode *node = list->head->next;
while (i < index)
{
node = node->next;
i++;
}
return node;
}
else
{
int i = 0;
DoubleLinkedNode *node = list->tail->next;
while (i < (list->length - index))
{
node = node->prev;
i++;
}
return node;
}
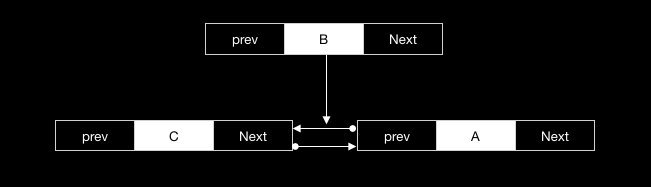
}元素的插入与单链表相比,只是多了一些指针的操作。它的插入过程如下:
- 找到待插入的位置的节点,记作:
A - 将节点
A的前置节点C指向 新插入的节点B - 将节点
A的前置节点重置为B。 - 然后,将 B的前置节点置作
C,后继节点置作A。
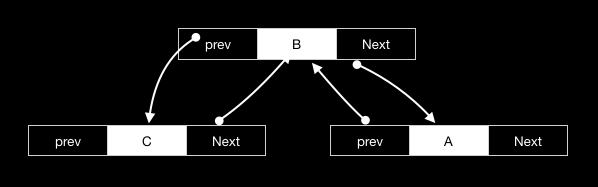
与单链表的删除类似,只是其节点的指针变更有所不同。其步骤如下:
- 获取目的节点
A。 - 将
A的前置节点B的next指针重置为A的后继节点C。 - 将
C的prev指针指向节点B。 - 回收节点
A(free(A))。
由于它高效删除和插入的特点,且无需提前分配空间等优点,因此它是实现一些其它线性结构的基础。一些常见应用: