The outline of the talk will be as follows:
- Introduction and problem statement [5 mins]
- Stage set up: a naive application performing gRPC streaming [2 mins - contains demo]
- Handling panics to avoid premature termination [2 mins - contains demo]
- Handling interruptions gracefully [20 mins - demo and explanations]
- Simulate errors on receiving and sending stream data [3 mins - contains demo]
- Explaining the overall strategy to avoid premature termination [5 mins]
- Resuming streaming in case of server side streaming errors or termination [3 mins - contains demo]
- Introducing graceful shutdown in the client [3 mins - contains demo]
- Resuming streaming in case of client termination or errors with the help of graceful shutdown [7 mins - contains demo]
- Recovery after forceful interruption [15 mins - contains demo]
- Explaining the problem and justifying the inevitability [2 mins]
- Simulating out-of-memory (OOM) termination as an example of forcible termination [3 mins - contains demo]
- Explaining strategy for recovery [3 mins]
- Introducing Kubernetes events receiver service [3 mins - contains demo]
- Making pods self-aware about their own name [1 mins - contains demo]
- Recovery after a forcible termination [3 mins - contains demo]
- Conclusion and recap [1 mins]
The total talk time is 45 minutes. It is noteworthy that to save time, the demos will be done by using pre-existing code snippets and pre-created containers (no live coding or deployment). The following sections explain in more detail what will be presented at each section.
We’re on a quest to make a Go application run perfectly even if operational unpredictability or misconfigurations gets in the way. This is inspired by our real-life story of dealing with an event-driven microservice architecture deployed on Kubernetes where large-volume, business-critical communications (usually synchronous) were required between services with low latency. gRPC streaming was a suitable technology for addressing the requirements in almost all aspects except for one: tolerance for failure. The inherent Kubernetes pod ephemerality made it hard to guarantee uptime for the involved pods during the long-running tasks. Additionally, operational unpredictability (such as ever-changing end-user behavior) made it difficult to have a proactive response to resource allocation settings, misconfiguration of which amplifies pods ephemerality. Our solution was to make gRPC streaming fault tolerant by building resiliency and recovery in the application, so that the system self-recovers from interruptions and the business stays happy.
This talk aims to provide a simplified version of the story, by omitting the business jargon, and focusing on the technical aspects. As such, it will be accompanied by a demo of how to evolve a simple Go application that is vulnerable to interruptions to long running tasks, to an application that can “handle” a variety of interruptions. There are two types of handling we’ll look at:
- Graceful interruption and seamless resumption
- Recovery (when graceful interruption is not possible)
In more detail, we will start by introducing two services deployed on a Kubernetes cluster that perform gRPC streaming between each other. Service A (the server) will retrieve some data from a mocked db, validate it, and send it to service B (the client) via gRPC streaming, where service B will reformat the data for its own consumption. We will simulate, in ascending order of complexity, the reasons the streaming could get interrupted, and demonstrate what strategies we can employ to address them. There are three categories of interruptions:
- Application panics/errors
- Streaming errors on sending and receiving stream data
- Abrupt termination, such as pod termination due to SIGKILL
The first reason for streaming interruption is simply applications encountering a panic or an error. This could be related to corrupt data. In our example case, when validating or reformatting the data, either client or server could encounter an error or cause panic. Regardless of server or client, if an error is detected, we are already in a good spot, because we can simply continue the streaming and perhaps just log what the issue is.
Handling a panic is not too different either, because we can typically prevent a panic by performing appropriate checks and handling them as errors. However, in a hypothetical scenario where performing checks would be tedious or not possible, or simply accounting for the possibility of development mistakes, we could also use the Go's built-in recover() function to capture the potential panics. In this case, the trick to resumption is reestablishing the streaming from right after the point of panic. Therefore having an ordering to the streaming data becomes critical so that we can reference the point of interruption and ask for data past that point. In our sample application, we will use a simple alphabetical sort on GUID userIDs as the ordering mechanism. So the server will first sort the data, and then send the data in order.
If the panic happens on the server, in the recover function, we will simply spin off a goroutine that continues the streaming from the point of failure. The spun off go routine in the recover will invoke the function responsible for sending the data recursively, and just asks for the next data from the db (skips the problematic data). In this way, the server handles panics on specific points of streaming, and the client does not need to notice the interruption. The idea is not too different for the case where the panic happens on the client. In the deferred recover function, we’d be recursively invoking the function receiving the data from the stream, effectively skipping the data that caused the panic.
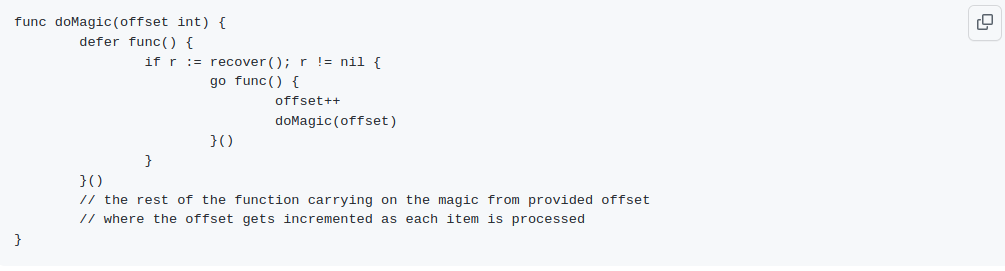
For a sample demonstration please see this playground link. In the sample demonstration, we simulate a server that encounters two panics (on indexes 0 and 2) while iterating over 5 items. Our recover function resumes the iteration after each panic from the point of failure, so that the program completes "processing" all the iterations that did not cause a panic. The code snippet below summarizes the approach. The same idea and procedure also applies to the client, where it can recover from panics at each iteration (piece of stream data received) and continue.
The second category for streaming interruption manifests itself as errors at the point of sending or receiving gRPC stream data (sendMsg and receiveMsg functions). These could occur as the result of temporary network disruptions, or termination of either client or server pods. Pods in Kubernetes are ephemeral and could get terminated for a number of reasons, including but not limited to exceeding resource thresholds assigned to the containers, problems in the node hosting the pod, or simply automatic scaling down. Any termination would constitute an error at the exit/entry points of the gRPC stream observed by the other side, causing premature termination of the process. However, our goal is to make the application resilient to these problems and make it automatically resume the streaming as soon as possible from the point of interruption, without any data loss. Therefore, upon receiving errors from sendMsg or receiveMsg, we need to reestablish the streaming to resume the process.
A key realization is that in gRPC streaming the server does not wait for the messages to be received by the client, as documented in grpc-go code. Thus the last message sent from the server is not the last message received by the client. Therefore upon reestablishing streaming, we cannot rely on the server to continue from the last message it sent, rather we need to rely on the last message that the client received and continue from that point. Another key realization is that the error that aborted the process might prevent immediate reestablishing of streaming. For example, if the only pod of the client was terminated, and there is no other client pod ready, streaming cannot immediately re-continue. So we need a mechanism to retry reestablishing the streaming and continuing it until it is successful.
Our strategy for reestablishing from the point of failure is rather simple. As part of the streaming request, the server accepts an “offset”, where the client can ask for the data past the offset. This in our example would be the last userID that was successfully received by the client. Again, a deterministic order (like sorted userIDs) from the server becomes critical to restore the stream flow. Hence, when an error is encountered by the server, it does not do anything special, and in fact the streaming will be aborted. However, the client when faced with an error that is aborting the stream, will store the offset (the last userID that was successfully received) in a database table which includes metadata for the streaming. The table can include a unique identifier for the streaming job, start time, end time, last received userID, along with other useful information. This information, in particular the unique id for the streaming job and the last userID received will be useful for continuing the streaming.
Our strategy for continually retrying streaming is assisted by a message queue. In our example we will use RabbitMQ. When the streaming is prematurely terminated, the streaming client will publish an event to the message queue containing identifying information for that process. The client service pods will also bind to receive the same event. Upon receiving the event, the container will attempt to reestablish the streaming, and if not successful or gets interrupted again, it will republish the event, possibly with updated information. Therefore, a client pod will emit the event, and a client pod will receive it and attempt to continue from the point of failure. Please see the image below as an illustration of this strategy.
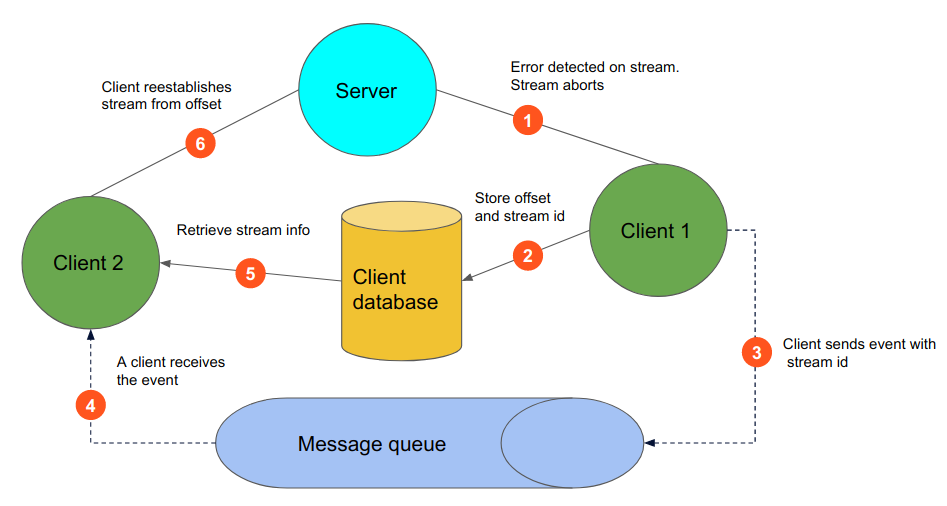
This is good and dandy when the root of the streaming interruption was a problem on the streaming server, because clients will continue retrying until all data gets streamed. This strategy also works when all streaming clients are unavailable, because the event will persist in the queue until a client becomes available. However, what if the streaming gets interrupted because the client pod gets terminated? How can we ensure we keep a reference to the last successfully received stream message, and that we emit the event to try reestablishing the streaming?
Lucky for us in Kubernetes, in most cases, a pod will be notified of termination by SIGTERM ahead of time, and after a grace period, if the container is still running the termination will be carried out by SIGKILL. So we can implement graceful termination for our client container by listening to the SIGTERM signal, and use the grace period to save the state and emit the event needed for resumption. However, we need to be careful to shutdown the components in proper order while gracefully shutting down the container. That is, upon receiving the SIGTERM, we need to first stop receiving events, complete sending the events needed for resumption out, and then close the channels used for sending the events. Otherwise, if we first emit the event and then shutdown our events broker, a terminating pod might receive the same event it had just emitted as a result of SIGTERM, which is unintended. Also, if we first shutdown events broker fully, and then attempt to gracefully interrupt the streaming, we will not be able to send the event, because the broker has already been shut down.
So far so good, but upon receiving SIGTERM, how do we actually gracefully interrupt the goroutine that is carrying out the streaming? In Go, a goroutine cannot terminate another goroutine. Therefore the goroutine listening on SIGTERM needs to communicate to the goroutines that are carrying out the streaming, and delegate the graceful interruption to them. Also, the goroutine listening to SIGTERM needs to wait for the interruptions to be carried out successfully by the streaming goroutines, and then continue the rest of the graceful shutdown, which includes tasks such as completely closing down the events broker. Time to use the much celebrated Go channels.
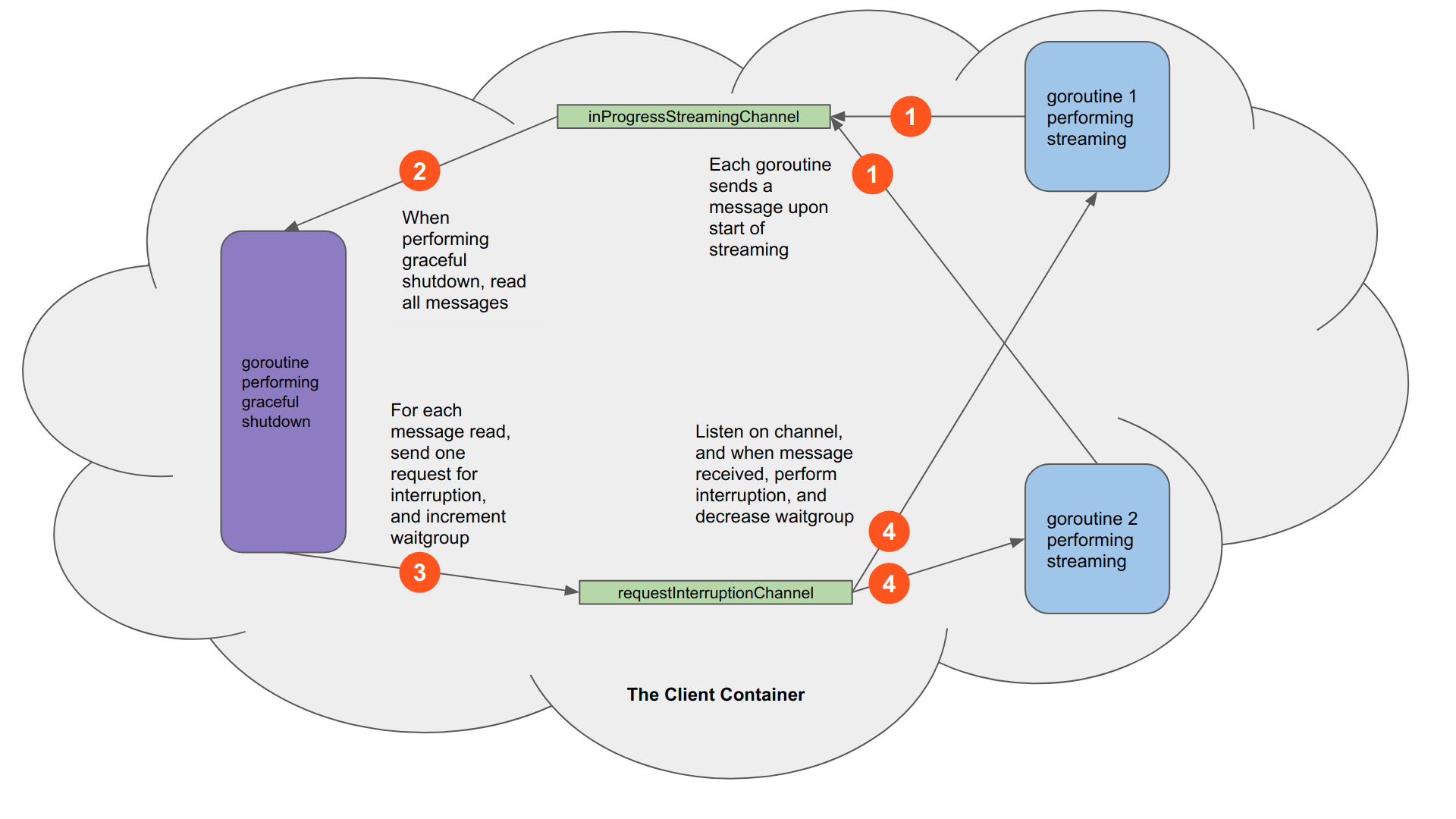
There will be two channels and a WaitGroup that is shared with all the goroutines to assist us.
- The first channel
inProgressStreamingChannelis to keep track of in-progress streaming goroutines. Each goroutine that is about to perform a streaming, sends a message to this channel. The goroutine performing the graceful shutdown reads from this channel and for each message it will request graceful interruption. If this channel is empty, the goroutine performing graceful shutdown can simply move on to shutting other components down without worrying about the need for a graceful interruption. - The second channel
requestInterruptionChannelis for communicating requesting graceful interruption to the streaming goroutines. The goroutine responsible for graceful shutdown will loop through messages in theinProgressStreamingChannel, and for each it will send a “request for an interruption” message. The streaming goroutines periodically listen to this channel, and if they receive a message, will initiate the graceful termination. - The WaitGroup is used for blocking the goroutine performing the graceful shutdown from closing all components before interruption is completed. Before sending each request for interruption message, the goroutine performing graceful shutdown will increment the WaitGroup, and then wait on the WaitGroup before continuing its other tasks. The streaming goroutines upon finishing interruption (after storing the stream id and offset, and sending the corresponding event to message broker), will decrement the WaitGroup, informing the main graceful shutdown goroutine that the interruption is done.
It is noteworthy that, each streaming goroutine, once finished the streaming completely will need to read from the first channel, effectively removing it from the in-progress streaming channel. The image below demonstrates the communication between the goroutines and the different stages of graceful interruption.
Please see this playground link for a simulation of how the goroutine performing graceful shutdown can use the aforementioned channels and the WaitGroup to perform graceful interruption. Also, the code snippet below summarizes the approach from the perspective of the goroutine performing the graceful shutdown.

At this point we can clarify the strategy for when streaming is interrupted because of a problem from the server side, and not the client. Before we mentioned the strategy is that the client upon receiving errors from the server, will keep the offset (last received user), and retry streaming. This is done simply by sending the interruption event message to the message broker (RabbitMQ), and the consumers of the message (possibly the same pod) will retry the streaming from the offset upon receiving it. So this is the graceful interruption behavior very similar to the case where SIGTERM was received by the client, with one minor difference. This time, when the interruption is completed, we do not decrement the WaitGroup. This is because the WaitGroup is used by the goroutine listening on SIGTERM for graceful shutdown on the client service, to know when to proceed to shutting down other components, and in this case the client pod is not shutting down.
Great, so far we have implemented our strategies that gracefully interrupt and resume streaming. However, is there a case where the client can get terminated without notice? If there is, our strategy is undermined, as the container will be killed immediately before we get a chance to save the offset and emit the event needed for resumption. Turns out, pod termination due to out of memory (OOM) happens by SIGKILL without time for graceful interruption. Also, in the case where graceful termination takes longer than the grace period followed by the SIGTERM, the container will get terminated by SIGKILL. We can demonstrate these with simple examples. But the conclusion is, we need a special strategy for handling termination due to SIGKILL. More specifically, graceful interruption is no longer feasible, and we need to think about recovery instead.
Stepping back for a second, we might be tempted to pursue the path of preventing these issues from happening, and thus avoiding the problems and the need for recovery. For example, we might adjust the resource thresholds appropriately to avoid OOM termination. Sounds reasonable. But practically, in an operationally unpredictable environment that changes over time or may have spiky behavior, it is hard to guarantee the correct settings are set proactively, or adjust them in a timely manner. Also, physical hardware or power failures on the nodes hosting the pods pose a risk that if we’re looking for a guarantee, make it practically impossible. Therefore for guaranteeing business requirements, having a recovery strategy seems to be a better approach than pursuing prevention. There are two parts to the recovery strategy: finding out that we need to recover, and performing the recovery.
Luckily, Kubernetes sends events when terminating pods that include the reason for the termination. We can listen to these events to identify if a pod was forcibly terminated. This will be our foundation for finding out whether we need to perform recovery. We’ll build a service that will use the Kubernetes APIs to receive pod termination events, and if a forcible termination is detected, publish an event on our message queue containing the name of the terminated pod. All running pods of the same service can listen to this queue and get notified of such an event. We will call this service “kubernetes-events-listener”. This does not have to be a separate service, but to have clear delegation of responsibilities for services, it would be better to have it as its own, which also allows for it evolving to a more generic Kubernetes events listener service in the future. The diagram below demonstrates the high-level recovery strategy.
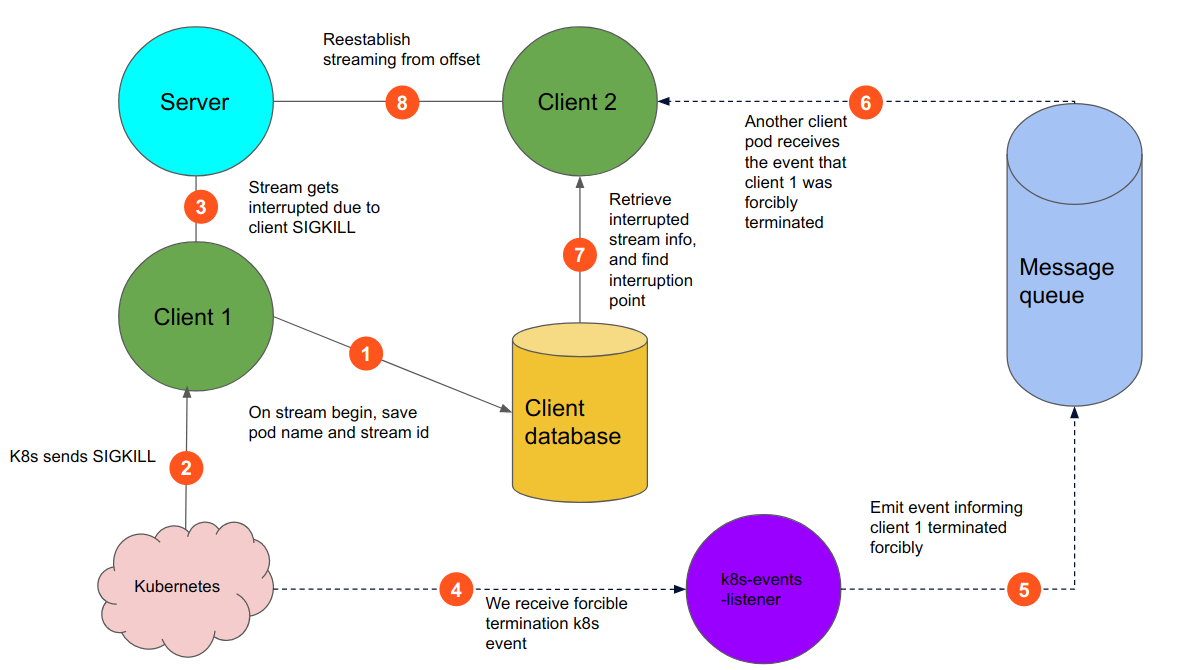
Thanks to the “kubernetes-events-listener”, a running pod can receive an event that informs it another pod was forcibly terminated. But we still need to know whether the terminated pod was performing a gRPC stream that was terminated forcibly, to perform recovery. This can be accomplished, if each pod performing streaming adds its name to the metadata table for the streaming job. A pod can become self-aware of its name through an environment variable injected on the Kubernetes manifest referencing the pod name metadata. Please see the snippet below as an example.
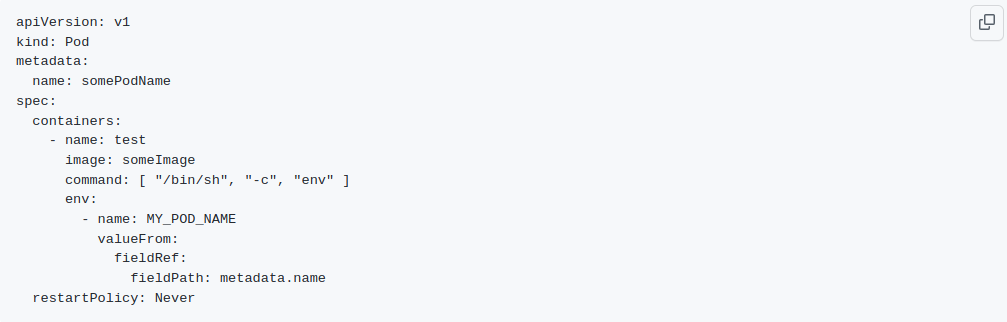
Then, a running pod receiving the forcible termination event can look up in the database to see if there are any unfinished streams for the pod with that name. If there is, it knows it should start a recovery process to restore the streaming that was previously started.
To perform the recovery, the recoverer pod needs to identify the point of interruption. If we tag each piece of data that was received by the stream with the unique identifier for the stream, and store that along the data itself in the streaming client’s database, then we can use that information to find the point of interruption. The recoverer pod can ask the database for the “biggest userID (because we used a sort as our ordering) that is tagged with the unique id of the terminated streaming job, and use that as the offset for reestablishing the streaming job. And that’s it!
When the business requires highly efficient synchronous streaming, gRPC streaming is a great choice that can outperform other popular streaming technologies such as Kafka streams. However, gRPC streaming inherently lacks tolerance for failure or recovery mechanisms. In this talk, we demonstrated these disadvantages using simulated demos, and introduced strategies that can make an application performing gRPC streaming fault tolerant and resilient to various interruptions including panics, network disruptions and termination due to SIGTERM or SIGKILL. Kubernetes pod ephemerality should no longer be a risk to completion of the gRPC streaming as we built mechanisms to restore a gracefully interrupted process, or recover from a not graceful termination. A notable advantage gained is that the resiliency allows us to retroactively adjust our resource allocation thresholds for containers, as the business will not be impacted by minor misconfigurations. So in an operationally unpredictable environment, we can have peace of mind that the business can carry on seamlessly, and we have reaction time to make adjustments if needed to the configuration, based on our observability metrics.