 -
-
-
- 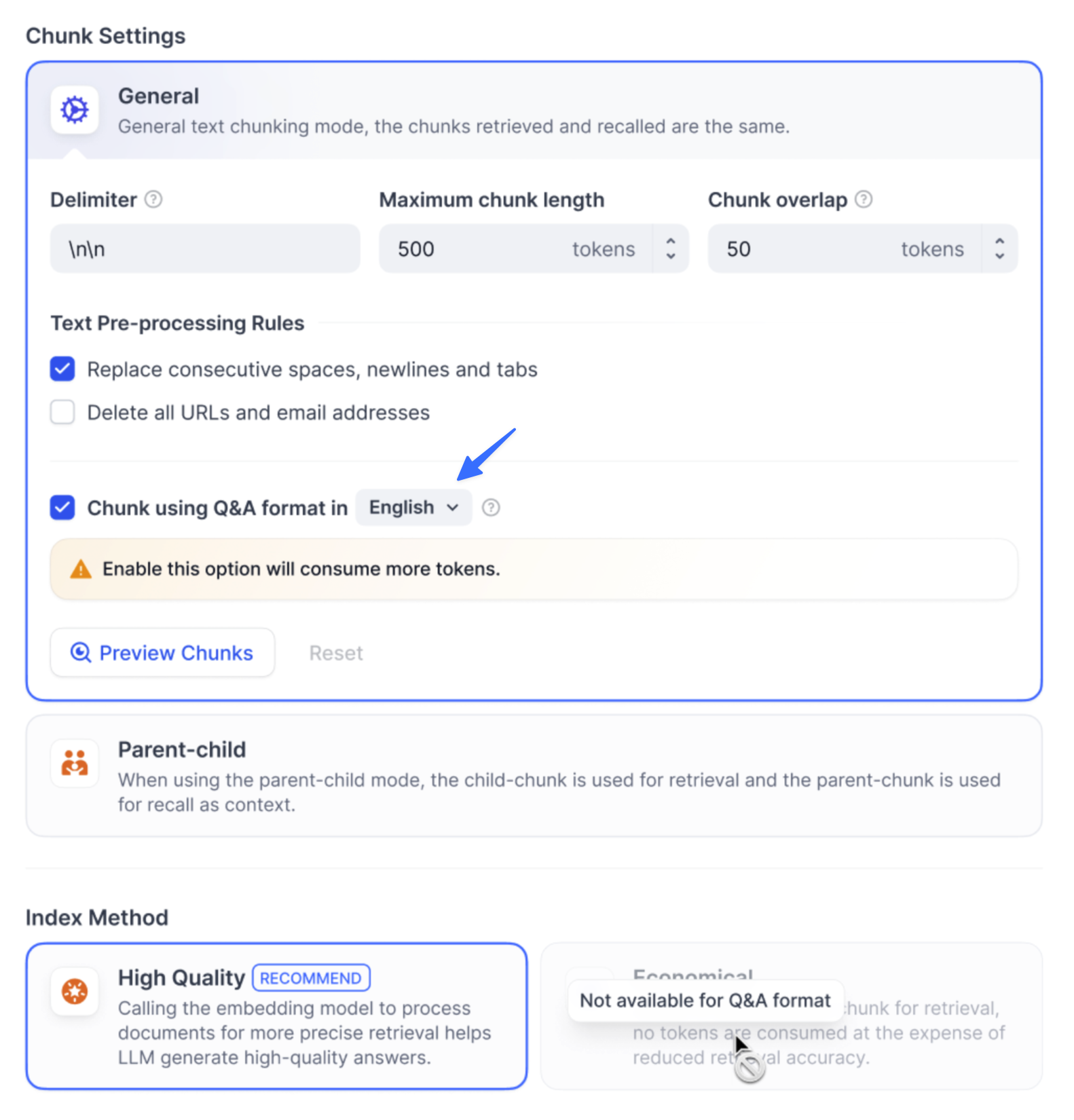 - 
-
-
- 
-
- +
+

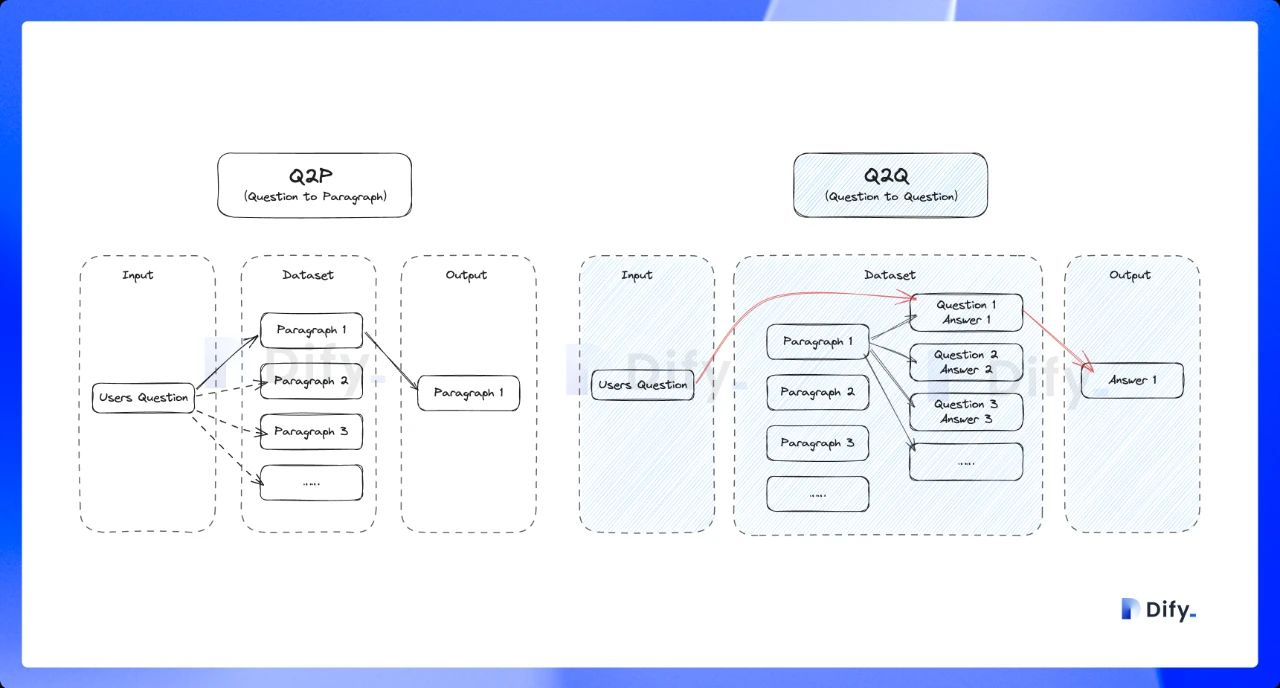
 -**ベクトル検索**
+ **ベクトル検索**
-**定義**: ユーザーの質問をベクトル化してクエリベクトルを生成し、ナレッジベース内の対応するテキストベクトルと比較して、最も近いチャンクを見つけます。
+ **定義:** ユーザーが入力した質問をベクトル化し、クエリテキストの数学ベクトルを生成し、クエリベクトルとナレッジベース内の対応するテキストベクトル間の距離を比較し、隣接する分割コンテンツを探します。
-
+
-**ベクトル検索**
+ **ベクトル検索**
-**定義**: ユーザーの質問をベクトル化してクエリベクトルを生成し、ナレッジベース内の対応するテキストベクトルと比較して、最も近いチャンクを見つけます。
+ **定義:** ユーザーが入力した質問をベクトル化し、クエリテキストの数学ベクトルを生成し、クエリベクトルとナレッジベース内の対応するテキストベクトル間の距離を比較し、隣接する分割コンテンツを探します。
-
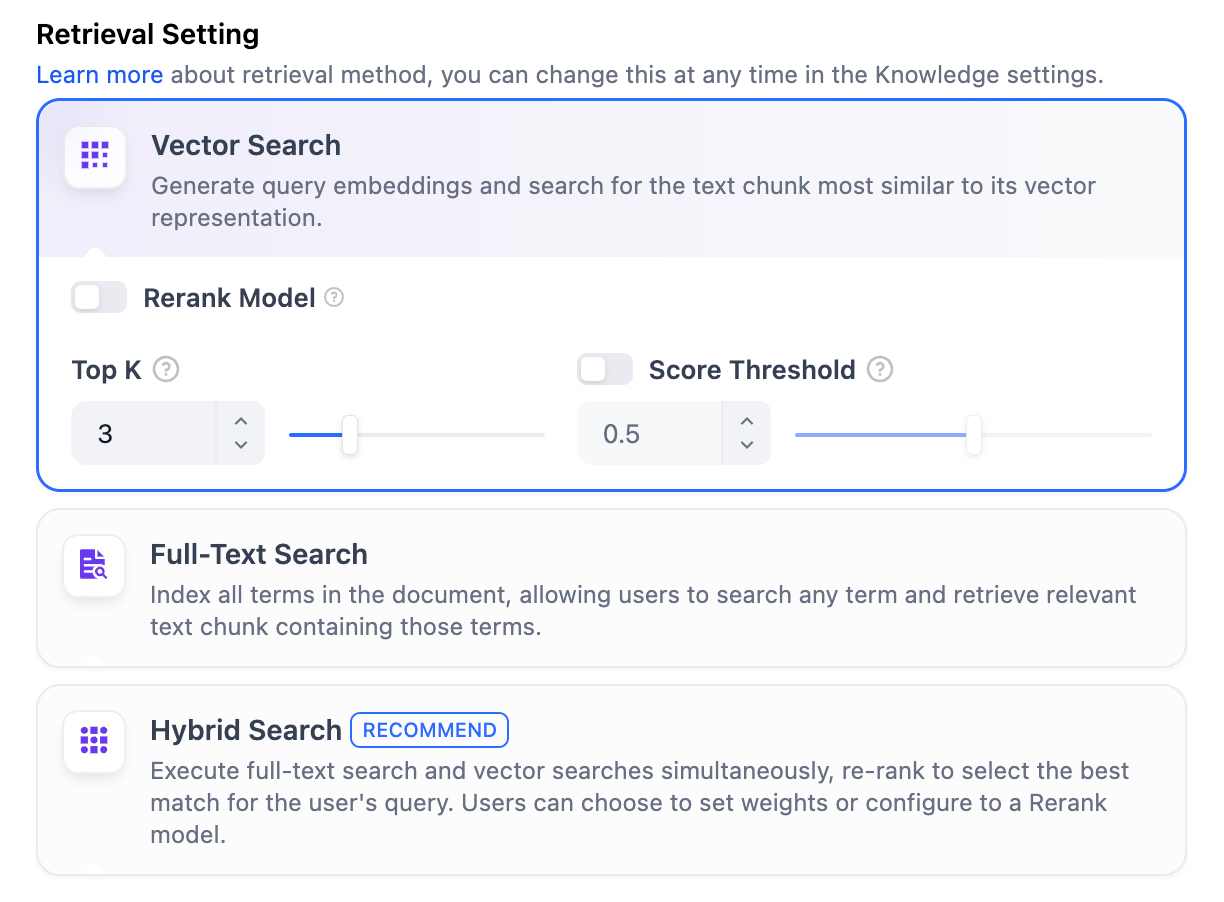
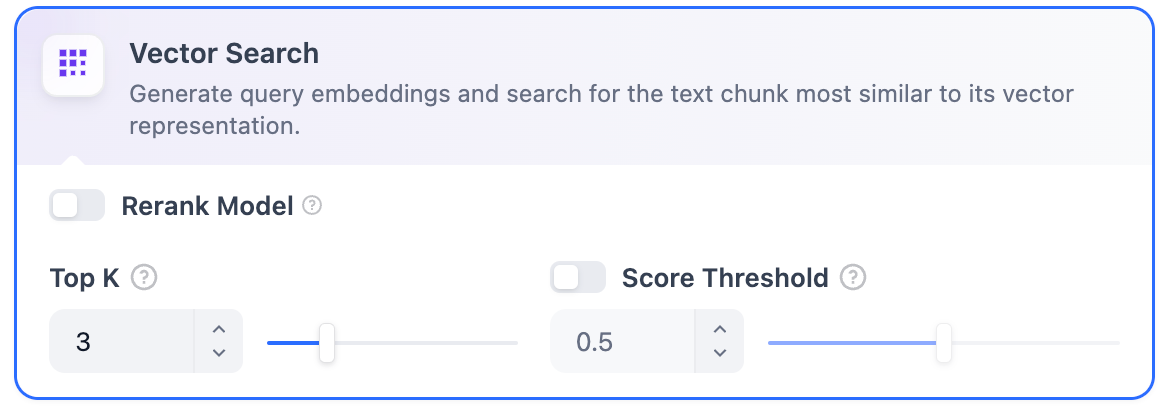
+  -**ベクトル検索設定:**
+ **ベクトル検索設定:**
-**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがベクトル検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ **Rerankモデル:** デフォルトでは無効です。有効にすると、ベクトル検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMがより正確なコンテンツを取得し、出力の品質を向上させるのを助けます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
-
-**ベクトル検索設定:**
+ **ベクトル検索設定:**
-**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがベクトル検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ **Rerankモデル:** デフォルトでは無効です。有効にすると、ベクトル検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMがより正確なコンテンツを取得し、出力の品質を向上させるのを助けます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
- -**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルが全文検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ **Rerankモデル:** デフォルトでは無効です。有効にすると、全文検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
-
-**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルが全文検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ **Rerankモデル:** デフォルトでは無効です。有効にすると、全文検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
- -
+ ハイブリッド検索設定では、**「重み付け設定」**または**「Rerankモデル」**の有効化を選択できます。
-このモードでは、RerankモデルAPIを設定せずに**「重み付け設定」**を指定するか、**Rerankモデル**を有効にして検索を行うことができます。
+ * **重み付け設定**
-* **重み付け設定**
+ ユーザーが意味的優先度とキーワード優先度にカスタム重みを付けることができます。キーワード検索はナレッジベース内での全文検索(Full Text Search)を指し、意味検索はナレッジベース内でのベクトル検索(Vector Search)を指します。
- この機能により、ユーザーは意味優先度とキーワード優先度にカスタム重みを設定できます。キーワード検索はナレッジベース内での全文検索を指し、意味検索はナレッジベース内でのベクトル検索を指します。
+ * **意味値を1にする**
- * **意味値を1にする**
+ **意味検索モードのみを有効にします**。Embeddingモデルを活用することで、クエリに含まれる正確な単語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、正確なコンテンツを返すことができます。また、多言語コンテンツを処理する必要がある場合、意味検索は異なる言語間の意味変換をキャプチャし、より正確なクロス言語検索結果を提供できます。
+ * **キーワード値を1にする**
- 意味検索モードのみを有効にします。埋め込みモデルを活用することで、クエリに含まれる正確な用語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、関連コンテンツを返すことができます。また、多言語コンテンツを処理する場合、意味検索は異なる言語間の意味をキャプチャし、より正確なクロス言語検索結果を提供できます。
- * **キーワード値を1にする**
+ **キーワード検索モードのみを有効にします**。ユーザーが入力した情報テキストをナレッジベース全体でマッチングし、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量の文書を含むナレッジベース内での迅速な検索に適しています。
+ * **キーワードと意味の重みをカスタマイズする**
- キーワード検索モードのみを有効にします。ナレッジベース内で入力テキストとの完全一致を実行し、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量のドキュメントを含むナレッジベース内での迅速な検索に適しています。
- * **キーワードと意味の重みをカスタマイズする**
+ 異なる値を1に引き上げるだけでなく、両者の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
+
+ > 意味検索とは、ユーザーの質問とナレッジベースコンテンツ内のベクトル間の距離を比較することを指します。距離が近いほど、マッチングの確率が高くなります。
- 意味検索またはキーワード検索のみを有効にするだけでなく、柔軟なカスタム重み設定を提供しています。両方の方法の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
***
- **Rerankモデル**
+ * **Rerankモデル**
- デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがハイブリッド検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ デフォルトでは無効です。有効にすると、ハイブリッド検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
-
-
+ ハイブリッド検索設定では、**「重み付け設定」**または**「Rerankモデル」**の有効化を選択できます。
-このモードでは、RerankモデルAPIを設定せずに**「重み付け設定」**を指定するか、**Rerankモデル**を有効にして検索を行うことができます。
+ * **重み付け設定**
-* **重み付け設定**
+ ユーザーが意味的優先度とキーワード優先度にカスタム重みを付けることができます。キーワード検索はナレッジベース内での全文検索(Full Text Search)を指し、意味検索はナレッジベース内でのベクトル検索(Vector Search)を指します。
- この機能により、ユーザーは意味優先度とキーワード優先度にカスタム重みを設定できます。キーワード検索はナレッジベース内での全文検索を指し、意味検索はナレッジベース内でのベクトル検索を指します。
+ * **意味値を1にする**
- * **意味値を1にする**
+ **意味検索モードのみを有効にします**。Embeddingモデルを活用することで、クエリに含まれる正確な単語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、正確なコンテンツを返すことができます。また、多言語コンテンツを処理する必要がある場合、意味検索は異なる言語間の意味変換をキャプチャし、より正確なクロス言語検索結果を提供できます。
+ * **キーワード値を1にする**
- 意味検索モードのみを有効にします。埋め込みモデルを活用することで、クエリに含まれる正確な用語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、関連コンテンツを返すことができます。また、多言語コンテンツを処理する場合、意味検索は異なる言語間の意味をキャプチャし、より正確なクロス言語検索結果を提供できます。
- * **キーワード値を1にする**
+ **キーワード検索モードのみを有効にします**。ユーザーが入力した情報テキストをナレッジベース全体でマッチングし、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量の文書を含むナレッジベース内での迅速な検索に適しています。
+ * **キーワードと意味の重みをカスタマイズする**
- キーワード検索モードのみを有効にします。ナレッジベース内で入力テキストとの完全一致を実行し、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量のドキュメントを含むナレッジベース内での迅速な検索に適しています。
- * **キーワードと意味の重みをカスタマイズする**
+ 異なる値を1に引き上げるだけでなく、両者の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
+
+ > 意味検索とは、ユーザーの質問とナレッジベースコンテンツ内のベクトル間の距離を比較することを指します。距離が近いほど、マッチングの確率が高くなります。
- 意味検索またはキーワード検索のみを有効にするだけでなく、柔軟なカスタム重み設定を提供しています。両方の方法の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
***
- **Rerankモデル**
+ * **Rerankモデル**
- デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがハイブリッド検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
+ デフォルトでは無効です。有効にすると、ハイブリッド検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
-
-  -
-
-
-
-
-
-
-
-
-**設定オプション**
-
-| 項目 | 説明 |
-|----------------|------------------------------------|
-| ファイル形式 | PDF、XLSX、DOCXなどに対応。ユーザーは選択をカスタマイズできます |
-| アップロード方法 | ドラッグ&ドロップまたはファイル選択でローカルファイルやフォルダをアップロード。バッチアップロード対応 |
+
---
@@ -94,22 +92,18 @@ title: ステップ2:ナレッジパイプラインをオーケストレーシ
Notionワークスペースと連携し、ページやデータベースをシームレスにインポート可能です。ナレッジベースは常に自動で最新状態に保たれます。
-
+
+ 
+
+
+ **設定オプション**
-**制限事項**
+ | 項目 | 説明 |
+ |----------------|------------------------------------|
+ | ファイル形式 | PDF、XLSX、DOCXなどに対応 |
+ | アップロード方法 | ドラッグ&ドロップまたは選択、バッチ対応 |
-| 項目 | 説明 |
-|--------------|-------------------------------------------------|
-| ファイル数 | 1回あたり最大50ファイルまで |
-| ファイルサイズ | 1ファイルあたり最大15MB |
-| ストレージ | SaaSサブスクリプションプランによりアップロード上限やストレージ容量が異なる場合があります |
+ **制限事項**
-**出力変数**
+ | 項目 | 説明 |
+ |--------------|-------------------------------------------------|
+ | ファイル数 | 1回あたり最大50ファイルまで |
+ | ファイルサイズ | 1ファイルあたり最大15MB |
+ | ストレージ | サブスクリプションプランによりアップロード上限が異なります |
-| 出力変数 | 形式 |
-|----------------|-----------------|
-| `{x} Document` | 単一ドキュメント |
-
-
+ **出力変数**
+ | 出力変数 | 形式 |
+ |----------------|-----------------|
+ | `{x} Document` | 単一ドキュメント |
+
-
- 对于自托管部署,可通过环境变量调整以下限制:
+ 对于自托管部署,可通过环境变量 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` 调整图片大小限制。
+
- - 最大图片尺寸:`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`
+
+ 每个分段最多支持 10 个图片附件,超出的图片不会被提取。
- - 每个分段的最大附件数量:`SINGLE_CHUNK_ATTACHMENT_LIMIT`
-
+ 对于自托管部署,可通过环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT` 调整此数量限制。
+
-若在索引设置中选择多模态嵌入模型(带有 **Vision** 图标),则提取出的图片也将被向量化并参与检索。
+若在后续的索引设置中选择多模态嵌入模型(带有 **Vision** 图标),则提取出的图片将被向量化并参与检索。
@@ -242,23 +234,21 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
-
-
-
-
-
-**設定オプション**
-
-| 項目 | オプション | 出力変数 | 説明 |
-|------------|------------|-----------------|------------------------|
-| Extractor | 有効 | `{x} Content` | 構造化・処理済み情報 |
-| | 無効 | `{x} Document` | オリジナルテキスト |
-
-
-
+
+
---
@@ -122,53 +116,45 @@ Webコンテンツを大規模言語モデルでも読みやすい形式に変
シンプルかつ使いやすいAPIを提供するオープンソースのWeb解析ツールです。Webコンテンツの高速クロールと処理に適しています。
-
+ 
+
+
+ **設定オプション**
+
+ | 項目 | オプション | 出力変数 | 説明 |
+ |------------|------------|-----------------|------------------------|
+ | Extractor | 有効 | `{x} Content` | 構造化・処理済み情報 |
+ | | 無効 | `{x} Document` | オリジナルテキスト |
+
-
----
-
### 在线网盘
连接你的在线云储存服务(例如 Google Drive、Dropbox、OneDrive),Dify 将自动检索云储存中的文件,你可以勾选并导入相应文档进行下一步处理,无需手动下载文件再进行上传。
@@ -196,24 +190,22 @@ title: "步骤二:编排知识流水线"
通过合适的文档处理工具,可将文档中的图片提取为对应分段的附件。被提取的图片可独立管理,并在检索时与分段一同返回。
-被提取图片的 URL 会保留在分段文本中,但你可以安全地删除这些 URL 以保持文本整洁——这不会影响已提取的图片。
-
-每个分段最多支持 10 个图片附件,超出的图片不会被提取。
-
若使用的工具未提取到图片,Dify 会自动提取通过以下 Markdown 语法引用、URL 可访问且小于 2 MB 的 JPG、JPEG、PNG 和 GIF 图片:
- ``
- ``
-
-
-
-
-
-**パラメータ設定**
-
-| パラメータ | 種類 | 説明 |
-|--------------------|--------|------------------------------------------------|
-| URL | 必須 | 対象Webページのアドレス |
-| サブページのクロール | 任意 | リンク先ページもクロールするか |
-| サイトマップ使用 | 任意 | サイトマップを利用してクロール |
-| 制限 | 必須 | クロールする最大ページ数 |
-| Extractor有効化 | 任意 | データ抽出方式の選択 |
-
-
-
+
+
#### Firecrawl
きめ細かなクロール制御オプションとAPIサービスを持つオープンソースのWeb解析ツールです。複雑なサイトの深層クロールやバッチ処理に適しています。
-
+ 
+
+
+ **パラメータ設定**
+
+ | パラメータ | 種類 | 説明 |
+ |--------------------|--------|------------------------------------------------|
+ | URL | 必須 | 対象Webページのアドレス |
+ | サブページのクロール | 任意 | リンク先ページもクロールするか |
+ | サイトマップ使用 | 任意 | サイトマップを利用してクロール |
+ | 制限 | 必須 | クロールする最大ページ数 |
+ | Extractor有効化 | 任意 | データ抽出方式の選択 |
+
-
-ドキュメント内の画像は、適切なドキュメントプロセッサを使用して抽出できます。抽出された画像は対応するチャンクに添付され、個別に管理でき、検索時にはそのチャンクと一緒に返されます。
-
-抽出された画像のURLはチャンクテキスト内に残りますが、テキストをクリーンに保つためにこれらのURLを安全に削除できます。これは抽出された画像には影響しません。
+ ドキュメント内の画像は、適切なドキュメントプロセッサを使用して抽出できます。抽出された画像は対応するチャンクに添付され、個別に管理でき、検索時にはそのチャンクと一緒に返されます。
-各チャンクには最大10枚まで画像を添付できます。これを超える画像は抽出されません。
+ 選択したプロセッサで画像が抽出されなかった場合、Difyは以下のMarkdown記法でアクセス可能なURLが参照されている2MB未満のJPG、PNG、GIF画像を自動的に抽出します:
-選択したプロセッサで画像が抽出されなかった場合、Difyは以下のMarkdown記法でアクセス可能なURLが参照されている2MB未満のJPG、JPEG、PNG、GIF画像を自動的に抽出します:
+ - ``
+ - ``
- - ``
- - ``
+
+ セルフホスト環境では、環境変数 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` でサイズ上限を調整できます。
+
-
- セルフホスト環境では、以下の上限を環境変数で調整できます:
+
+ 各チャンクには最大10枚まで画像を添付できます。これを超える画像は抽出されません。
- - 画像サイズの上限:`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`
-
- - 1チャンクあたりの添付画像数上限:`SINGLE_CHUNK_ATTACHMENT_LIMIT`
-
+ セルフホスト環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` でこの上限を調整できます。
+
-インデックス設定で**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択した場合、抽出された画像も埋め込み・インデックス化され、検索対象となります。
+ その後のインデックス設定で**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択した場合、抽出された画像も埋め込み・インデックス化され、検索対象となります。
#### Doc Extractor(ドキュメント抽出器)
-
+
-情報処理の中核となり、入力変数からファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
+情報処理の中核となり、入力ファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
-詳細は[ドキュメント抽出器](/ja/use-dify/nodes/doc-extractor)をご参照ください。
+詳細は[ドキュメント抽出器](/ja-jp/use-dify/nodes/doc-extractor)をご参照ください。
#### Dify Extractor
@@ -240,18 +224,15 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
#### Unstructured
-
他のツールについては[Dify Marketplace](https://marketplace.dify.ai)をご覧ください。
@@ -297,22 +278,22 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
| 設定項目 | 説明 |
|-------------------|--------------------------------------------------------------------------|
-| 区切り文字 | デフォルトは`\n`(段落区切り用改行)。正規表現によるカスタム分割ルールも利用可。テキスト内に区切り文字が出現すると自動的に分割されます。 |
-| 最大チャンク長 | 各セグメントの最大文字数。上限超過時は強制分割されます。 |
+| 区切り文字 | デフォルトは`\n`(段落区切り用改行)。正規表現も利用可。 |
+| 最大チャンク長 | 各セグメントの最大文字数(上限超過時は自動分割) |
| チャンク重複 | 分割時にセグメント間で部分重複させることで情報保持・検索精度を向上 |
#### 親子分割器(Parent-child Chunker)
-クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用し、RAGシステムにおけるコンテキストと精度の矛盾を解決します。
+クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用しています。
**親子分割器の仕組み**
-- **子チャンク(高精度マッチング用)**:ユーザーのクエリに高精度でマッチングするための小さく精密な情報セグメント(通常、1文ごと)
-- **親チャンク(豊富なコンテキスト)**:該当する子チャンクを含む広い範囲のコンテンツブロック(段落、セクション、またはドキュメント全体)で、大規模言語モデル(LLM)に包括的な背景情報を提供
+- **子チャンク(高精度マッチング用)**:通常、1文ごとの細かなセグメント
+- **親チャンク(豊富なコンテキスト)**:該当する子チャンクを含む広い範囲(段落やセクション単位)
| タイプ | 変数 | 説明 |
|------------|---------------------------|------------------------------|
-| 入力変数 | `{x} Content` | 分割対象となる文書コンテンツ |
+| 入力変数 | `{x} Content` | 原文テキスト |
| 出力変数 | `{x} Array[ParentChunk]` | 親チャンク配列 |
**分割設定**
@@ -323,7 +304,7 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
| 親チャンク最大長 | 親チャンクの最大文字数 |
| 子チャンク区切り文字 | 子チャンク分割ルール |
| 子チャンク最大長 | 子チャンクの最大文字数 |
-| 親モード | 「段落」(テキストを段落に分割)または「全文書」(ドキュメント全体を親チャンクとして直接検索に使用)いずれか選択 |
+| 親モード | 「段落」または「全文書」いずれか選択 |
#### Q&Aプロセッサ
@@ -334,14 +315,14 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
| タイプ | 変数 | 説明 |
|-----------|------------------------|---------------------------------------|
| 入力変数 | `{x} Document` | 単一ファイル |
-| 出力変数 | `{x} Array[QAChunk]` | Q&Aチャンク |
+| 出力変数 | `{x} Array[QAChunk]` | Q&Aチャンク配列 |
**変数設定**
| 設定項目 | 説明 |
|-----------------|------------------|
-| 質問用カラム番号 | 質問として設定するコンテンツ列 |
-| 回答用カラム番号 | 回答として設定する列 |
+| 質問用カラム番号 | 質問内容の列番号 |
+| 回答用カラム番号 | 回答内容の列番号 |
---
@@ -355,9 +336,9 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール

-チャンク構造は、ナレッジベースが文書コンテンツをどう整理・インデックス化するかを定めます。ドキュメントタイプ、用途、コストに適したモードを選択してください。
+チャンク構造は、ナレッジベースが文書コンテンツをどう整理・インデックス化するかを定めます。用途やコストに適したモードを選択してください。
-ナレッジベースは3つのチャンクモードをサポートします:**汎用モード**、**親子モード**、**Q&Aモード**。初めてナレッジベースを作成する場合は親子モードが推奨されます。
+ナレッジベースは3つのチャンクモードをサポートします:**汎用モード**、**親子モード**、**Q&Aモード**。初めて設定する場合は親子モードが推奨されます。
**重要:** チャンク構造は一度保存・公開すると変更できません。慎重にご選択ください。
@@ -365,157 +346,146 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
#### 汎用モード
-標準的なドキュメント処理に最適です。柔軟なインデックスオプションを提供し、品質やコストの異なる要件に応じて適切なインデックス方法を選択できます。
-
-汎用モードは高品質とコスト効率の両方のインデックス方法、および各種検索設定をサポートします。
+標準的なドキュメント処理に最適です。ニーズに応じ、柔軟なインデックスと検索設定が選択可能です。
#### 親子モード
-検索時の高精度マッチングと対応するコンテキスト情報を提供し、完全なコンテキストを維持する必要がある専門ドキュメントに適しています。
-
-親子モードはHQ(高品質)モードのみ対応で、クエリマッチング用の子チャンクと検索時のコンテキスト情報用の親チャンクを提供します。
+検索時の高精度マッチングと文脈提供が必要なエンタープライズ向け専門ドキュメントに最適です。HQ(高品質)インデックスのみ対応です。
#### Q&Aモード
-構造化された質問回答データを使用する際に、質問と回答をペアにしたドキュメントを作成します。これらのドキュメントは質問部分に基づいてインデックス化され、クエリの類似性に基づいて関連する回答を検索できます。
-
-Q&AモードはHQ(高品質)モードのみ対応です。
+構造化された質問回答データ向けです。Q&Aペアが質問部に基づいてインデックス化され、関連回答が検索できます。こちらもHQモードのみ対応です。
### 入力変数
-入力変数はデータ処理ノードからの処理結果をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ入力として接続する必要があります。
-
-ノードは選択したチャンク構造に基づいて異なるタイプの標準入力をサポートします:
+入力変数はデータ処理ノードからの出力をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ接続します。
-- **汎用モード**:x Array[Chunk] - 汎用チャンク配列
-- **親子モード**:x Array[ParentChunk] - 親チャンク配列
-- **Q&Aモード**:x Array[QAChunk] - Q&Aチャンク配列
+- **汎用モード**:`{x} Array[Chunk]`(汎用チャンク配列)
+- **親子モード**:`{x} Array[ParentChunk]`(親チャンク配列)
+- **Q&Aモード**:`{x} Array[QAChunk]`(Q&Aチャンク配列)
### インデックス方法と検索設定
-インデックス方法はナレッジベース内のコンテンツインデックスの構築方法を決定し、検索設定は選択したインデックス方法に基づいた対応する検索戦略を提供します。
-
-つまり、インデックス方法はドキュメントの整理方法を決定し、検索設定はユーザーがドキュメントを見つけるために使用できる方法を指定します。
-
-ナレッジベースでは**高品質**と**コスト効率**の2つのインデックス方法があり、それぞれ異なる検索設定オプションを提供します。
+インデックス方法はナレッジベース内のコンテンツ整理法を決定し、検索設定はそれに基づいた検索戦略を指定します。
+ナレッジベースでは**高品質**と**コスト効率**の2方式があり、それぞれ検索方法が異なります。
-**高品質モード**では、埋め込みモデルを使用してチャンクを数値ベクトルに変換し、大量の情報をより効果的に圧縮・保存できます。これにより、ユーザーの質問の言い回しがドキュメントと完全に一致しなくても、意味的に関連する正確な回答をシステムが見つけることができます。
+**高品質モード**では、埋め込みモデル(Embedding)によりテキストをベクトル化し、意味的な関連性検索が可能です(完全一致でなくても適切な回答に辿り着けます)。
- クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像も埋め込み・インデックス化され、検索対象となります。
+
+ クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像もベクトル化され、検索用にインデックス化されます。
このような埋め込みモデルを使用するナレッジベースは、カード上で**Multimodal**と表示されます。
+
-**コスト効率モード**では、各ブロックは10個のキーワードで検索用にインデックス化され、埋め込みモデルを呼び出さないためコストは発生しません。
+**コスト効率モード**では、各ブロックは10個のキーワードでインデックス化され、埋め込みモデルのコストは発生しません。
+
+
+詳細は[インデックス方法と検索設定を指定](/ja/use-dify/knowledge/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
+
-
-詳細は[インデックス方法と検索設定を指定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods)をご参照ください。
-
+#### インデックス方法と検索設定概要
-| インデックス方法 | 利用可能な検索設定 | 説明 |
+| インデックス方法 | 検索設定 | 説明 |
|----------------|----------------|-----------------------------------------------------|
-| 高品質 | ベクトル検索 | 意味的類似性に基づいてクエリの深い意味を理解 |
-| | 全文検索 | キーワードベースの包括的検索機能を提供 |
-| | ハイブリッド検索| 意味検索とキーワード検索を組み合わせ |
-| コスト効率 | 逆引きインデックス| 一般的な検索エンジン検索方式で、クエリを主要コンテンツとマッチング |
+| 高品質 | ベクトル検索 | 意味的類似性(自然言語での深い検索) |
+| | 全文検索 | キーワードベースの包括的検索 |
+| | ハイブリッド検索| 意味検索+キーワード検索の組合せ |
+| コスト効率 | 逆引きインデックス| 一般的な検索エンジン型方式 |
- 選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび検索結果から除外されます。
+ 選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
-チャンク構造、インデックス方法、パラメータ、検索設定の構成については、以下の表もご参照ください。
+詳細は以下の表をご参照ください。
| チャンク構造 | インデックス方法 | パラメータ | 検索設定 |
|-------------|----------------|-------------------|----------------------|
-| 汎用モード | 高品質
コスト効率 | 埋め込みモデル
キーワード数 | ベクトル検索
全文検索
ハイブリッド検索
逆引きインデックス | -| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 | -| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 | +| 汎用モード | 高品質
コスト効率 | 埋め込みモデル
キーワード数 | ベクトル
全文
ハイブリッド検索
逆引きインデックス | +| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル
全文
ハイブリッド検索 | +| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル
全文
ハイブリッド検索 | --- ## ステップ4:ユーザー入力フォームの作成 -ユーザー入力フォームは、パイプラインを効果的に実行するために必要な初期情報を収集するために不可欠です。ワークフローの[ユーザー入力ノード](/ja/use-dify/nodes/user-input)と同様に、このフォームはユーザーから必要な詳細情報(アップロードするファイル、ドキュメント処理の特定パラメータなど)を収集し、パイプラインが正確な結果を提供するために必要なすべての情報を確保します。 - -これにより、さまざまなユースケースシナリオに特化した入力フォームを作成でき、さまざまなデータソースやドキュメント処理ステップに対するパイプラインの柔軟性と使いやすさを向上できます。 +ユーザー入力フォームは、パイプライン実行時に必要な初期情報をユーザーから収集します。ワークフローの開始ノードと同様に、必要な设置情報(アップロードファイル、特定パラメータなど)を収集し、パイプラインの柔軟性・利便性を高めます。 ### フォームの作成方法 -ユーザー入力フィールドを作成する方法は2つあります: +1. **パイプライン構築UI** + - 「入力フィールド」をクリックして作成・設定を開始 +  -1. **パイプライン構築インターフェース**\ - **入力フィールド**をクリックして入力フォームの作成と設定を開始します。\ - -2. **ノードパラメータパネル**\
- ノードを選択します。次に、右側パネルのパラメータ入力で、新しい入力項目のために「+ ユーザー入力を作成」をクリックします。新しい入力項目は入力フィールドにも収集されます。
-2. **ノードパラメータパネル**\
- ノードを選択します。次に、右側パネルのパラメータ入力で、新しい入力項目のために「+ ユーザー入力を作成」をクリックします。新しい入力項目は入力フィールドにも収集されます。 +2. **ノードパラメータパネル**
+ - ノード選択後、パラメータ入力欄の「+ ユーザー入力を作成」をクリック
+ 
### ユーザー入力フィールドの追加
-#### 各エントランス固有の入力
-
-
+#### 各エントランス固有入力
-これらの入力は各データソースとその下流ノードに固有です。ユーザーは対応するデータソースを選択した場合にのみ、これらのフィールドに入力する必要があります(例:異なるデータソース用の異なるURL)。
+
-**作成方法**:データソースの右側にある`+`ボタンをクリックして、その特定のデータソース用のフィールドを追加します。これらのフィールドは、そのデータソースとその後続の接続ノードからのみ参照できます。
+2. **ノードパラメータパネル**
+ - ノード選択後、パラメータ入力欄の「+ ユーザー入力を作成」をクリック
+ 
### ユーザー入力フィールドの追加
-#### 各エントランス固有の入力
-
-
+#### 各エントランス固有入力
-これらの入力は各データソースとその下流ノードに固有です。ユーザーは対応するデータソースを選択した場合にのみ、これらのフィールドに入力する必要があります(例:異なるデータソース用の異なるURL)。
+
-**作成方法**:データソースの右側にある`+`ボタンをクリックして、その特定のデータソース用のフィールドを追加します。これらのフィールドは、そのデータソースとその後続の接続ノードからのみ参照できます。 +これは各データソースや下流ノードに固有です。該当データソース選択時のみ入力対象となります(例:異なるURLの指定等)。
-#### すべてのエントランス用のグローバル入力
+**作成方法**:データソース横の`+`ボタンからそのソース専用フィールドを追加できます。選択したソースからのみアクセス可能です。
-
+
-グローバル共有入力はすべてのノードから参照できます。これらの入力は、区切り文字、最大チャンク長、ドキュメント処理設定など、汎用的な処理パラメータに適しています。ユーザーはどのデータソースを選択しても、これらのフィールドに入力する必要があります。
+#### すべてのエントランス共通入力
-**作成方法**:グローバル入力の右側にある`+`ボタンをクリックして、任意のノードから参照できるフィールドを追加します。
-
-### サポートされる入力フィールドタイプ
+
-ナレッジパイプラインは7種類の入力変数をサポートします:
+全ノードから参照できるグローバル共有入力です。チャンク区切りや最大長等、汎用パラメータの入力に適します。
-
+これは各データソースや下流ノードに固有です。該当データソース選択時のみ入力対象となります(例:異なるURLの指定等)。
-#### すべてのエントランス用のグローバル入力
+**作成方法**:データソース横の`+`ボタンからそのソース専用フィールドを追加できます。選択したソースからのみアクセス可能です。
-
+
-グローバル共有入力はすべてのノードから参照できます。これらの入力は、区切り文字、最大チャンク長、ドキュメント処理設定など、汎用的な処理パラメータに適しています。ユーザーはどのデータソースを選択しても、これらのフィールドに入力する必要があります。
+#### すべてのエントランス共通入力
-**作成方法**:グローバル入力の右側にある`+`ボタンをクリックして、任意のノードから参照できるフィールドを追加します。
-
-### サポートされる入力フィールドタイプ
+
-ナレッジパイプラインは7種類の入力変数をサポートします:
+全ノードから参照できるグローバル共有入力です。チャンク区切りや最大長等、汎用パラメータの入力に適します。
-
-
-
-
-
-
-**パラメータ設定**
-
-| パラメータ | 種類 | 説明 |
-|-----------------------|--------|------------------------------------------------|
-| URL | 必須 | 対象Webページのアドレス |
-| 制限 | 必須 | クロールする最大ページ数 |
-| サブページクロール | 任意 | リンク先ページもクロールするか |
-| 最大深度 | 任意 | 開始URLからクロールする階層の深さ |
-| 除外パス | 任意 | クロール対象から除外したいURLパターン |
-| 限定パス | 任意 | 指定したパスのみクロール |
-| Extractor | 任意 | データ処理方式の選択 |
-| 主要コンテンツのみ抽出 | 任意 | ページの主要テキストやメディアのみ抽出 |
-
-
-
+
+
---
@@ -193,43 +179,41 @@ Google Drive、Dropbox、OneDriveなどのクラウドストレージサービ
### ドキュメントプロセッサ
-PDF、XLSX、DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
+PDF, XLSX, DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
Difyのドキュメント抽出器、あるいはMarketplaceから「Dify Extractor」「Unstructured」等のツールを選択できます。
+ 
+
+
+ **パラメータ設定**
+
+ | パラメータ | 種類 | 説明 |
+ |-----------------------|--------|------------------------------------------------|
+ | URL | 必須 | 対象Webページのアドレス |
+ | 制限 | 必須 | クロールする最大ページ数 |
+ | サブページクロール | 任意 | リンク先ページもクロールするか |
+ | 最大深度 | 任意 | 開始URLからクロールする階層の深さ |
+ | 除外パス | 任意 | クロール対象から除外したいURLパターン |
+ | 限定パス | 任意 | 指定したパスのみクロール |
+ | Extractor | 任意 | データ抽出方式の選択 |
+ | 主要コンテンツのみ抽出 | 任意 | ページの主要テキストやメディアのみ抽出 |
+
-
+
-
-
-
-
-
-[Unstructured](https://marketplace-staging.dify.dev/plugins/langgenius/unstructured)は、高度なカスタマイズ可能性を備えた抽出戦略でドキュメントを機械可読形式へ変換します。抽出戦略(auto、hi_res、fast、OCR-only)や分割方法(by_title、by_page、by_similarity)に柔軟に対応。要素ごとの座標や信頼度、レイアウトなどリッチなメタデータも出力し、企業のドキュメントワークフローや混合タイプファイルの精密な処理に適しています。
-
-
-
-
+
+ 
+
+
+ [Unstructured](https://marketplace.dify.ai/plugins/langgenius/unstructured)は、高度なカスタマイズ可能性を備えた抽出戦略でドキュメントを機械可読形式へ変換します。
+ 抽出戦略(auto, hi_res, fast, OCR-only)や分割方法(by_title, by_page, by_similarity)に柔軟に対応。要素ごとの座標や信頼度、レイアウトなどリッチなメタデータも出力し、企業のドキュメントワークフローや混合タイプファイルの精密な処理に適しています。
+
+
+
コスト効率 | 埋め込みモデル
キーワード数 | ベクトル検索
全文検索
ハイブリッド検索
逆引きインデックス | -| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 | -| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 | +| 汎用モード | 高品質
コスト効率 | 埋め込みモデル
キーワード数 | ベクトル
全文
ハイブリッド検索
逆引きインデックス | +| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル
全文
ハイブリッド検索 | +| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル
全文
ハイブリッド検索 | --- ## ステップ4:ユーザー入力フォームの作成 -ユーザー入力フォームは、パイプラインを効果的に実行するために必要な初期情報を収集するために不可欠です。ワークフローの[ユーザー入力ノード](/ja/use-dify/nodes/user-input)と同様に、このフォームはユーザーから必要な詳細情報(アップロードするファイル、ドキュメント処理の特定パラメータなど)を収集し、パイプラインが正確な結果を提供するために必要なすべての情報を確保します。 - -これにより、さまざまなユースケースシナリオに特化した入力フォームを作成でき、さまざまなデータソースやドキュメント処理ステップに対するパイプラインの柔軟性と使いやすさを向上できます。 +ユーザー入力フォームは、パイプライン実行時に必要な初期情報をユーザーから収集します。ワークフローの開始ノードと同様に、必要な设置情報(アップロードファイル、特定パラメータなど)を収集し、パイプラインの柔軟性・利便性を高めます。 ### フォームの作成方法 -ユーザー入力フィールドを作成する方法は2つあります: +1. **パイプライン構築UI** + - 「入力フィールド」をクリックして作成・設定を開始 +  -1. **パイプライン構築インターフェース**\ - **入力フィールド**をクリックして入力フォームの作成と設定を開始します。\ -
-2. **ノードパラメータパネル**\
- ノードを選択します。次に、右側パネルのパラメータ入力で、新しい入力項目のために「+ ユーザー入力を作成」をクリックします。新しい入力項目は入力フィールドにも収集されます。
+2. **ノードパラメータパネル**
+ - ノード選択後、パラメータ入力欄の「+ ユーザー入力を作成」をクリック
+ 
### ユーザー入力フィールドの追加
-#### 各エントランス固有の入力
-
-
+#### 各エントランス固有入力
-これらの入力は各データソースとその下流ノードに固有です。ユーザーは対応するデータソースを選択した場合にのみ、これらのフィールドに入力する必要があります(例:異なるデータソース用の異なるURL)。
+
-**作成方法**:データソースの右側にある`+`ボタンをクリックして、その特定のデータソース用のフィールドを追加します。これらのフィールドは、そのデータソースとその後続の接続ノードからのみ参照できます。
+これは各データソースや下流ノードに固有です。該当データソース選択時のみ入力対象となります(例:異なるURLの指定等)。
-#### すべてのエントランス用のグローバル入力
+**作成方法**:データソース横の`+`ボタンからそのソース専用フィールドを追加できます。選択したソースからのみアクセス可能です。
-
+
-グローバル共有入力はすべてのノードから参照できます。これらの入力は、区切り文字、最大チャンク長、ドキュメント処理設定など、汎用的な処理パラメータに適しています。ユーザーはどのデータソースを選択しても、これらのフィールドに入力する必要があります。
+#### すべてのエントランス共通入力
-**作成方法**:グローバル入力の右側にある`+`ボタンをクリックして、任意のノードから参照できるフィールドを追加します。
-
-### サポートされる入力フィールドタイプ
+
-ナレッジパイプラインは7種類の入力変数をサポートします:
+全ノードから参照できるグローバル共有入力です。チャンク区切りや最大長等、汎用パラメータの入力に適します。
-
-
-サポートされるフィールドタイプの詳細については、[ユーザー入力](/ja/use-dify/nodes/user-input)をご参照ください。
-
+
+詳細は[入力フィールドのドキュメント](/ja/use-dify/nodes/user-input)をご参照ください。
+
### フィールド設定オプション
-すべての入力フィールドタイプには、必須、任意、および追加設定があります。適切なオプションをチェックしてフィールドを必須にするかどうかを設定できます。
+全入力フィールドには必須/任意および追加設定があります。適切なチェックで必須化等を指定します。
| 設定 | 名称 | 説明 | 例 |
|-------------------|---------------|--------------------------------------------------|--------------------------|
-| 必須設定 | 変数名 | 内部システム識別子、通常は英語とアンダースコアで命名 | `user_email` |
-| | 表示名 | インターフェース表示名、通常は簡潔で読みやすいテキスト | ユーザーメール |
-| タイプ固有設定 | | 異なるフィールドタイプの特別な要件 | テキストフィールドの最大長100文字 |
-| 追加設定 | デフォルト値 | ユーザーが入力していない場合のデフォルト値 | 数値フィールドのデフォルトは0、テキストフィールドのデフォルトは空 |
-| | プレースホルダー | 入力ボックスが空のときに表示されるヒントテキスト | 「メールアドレスを入力してください」 |
-| | ツールチップ | ユーザー入力をガイドする説明テキスト、通常はマウスホバー時に表示 | 「有効なメールアドレスを入力してください」 |
-| 特殊任意設定 | | 異なるフィールドタイプに基づく追加設定オプション | メール形式のバリデーション |
+| 必須設定 | 変数名 | 内部識別用(英数字・アンダースコア推奨) | `user_email` |
+| | 表示名 | UI上に表示される名称 | ユーザーメール |
+| タイプ固有設定 | | タイプごとの条件 | テキストの最大長制限等 |
+| 追加設定 | デフォルト値 | 未入力時の既定値 | 数値は0、テキストは空文字 |
+| | プレースホルダー | 入力欄が空のときのヒント表示 | 「メールアドレス入力」 |
+| | ツールチップ | 補足説明(マウスホバー時表示) | 「有効なメールアドレスを…」 |
+| 特殊任意設定 | | タイプごとの特殊バリデーション | メール形式チェック等 |
-設定完了後、右上のプレビューボタンをクリックしてフォームプレビューインターフェースを閲覧できます。フィールドのグループ化をドラッグして調整できます。感嘆符が表示された場合は、移動後に参照が無効になっていることを示します。
+設定後、右上のプレビューボタンで実際のフォーム動作確認やフィールド並び替えが可能です。「!」マーク表示時は参照無効を示します。
-
+
---
@@ -523,50 +493,40 @@ Q&AモードはHQ(高品質)モードのみ対応です。

-デフォルトのナレッジベース名は「Untitled+番号」、権限は「自分のみ」、アイコンはオレンジ色の書籍です。DSLファイルからインポートした場合は保存されたアイコンが使用されます。
+デフォルトのナレッジベース名は「Untitled+番号」、権限は「自分のみ」、アイコンはオレンジ色の書籍です。DSLファイルからインポートした場合は元のアイコンが適用されます。
-左パネルの**設定**をクリックし、以下の情報を入力してください:
-
-- **名前とアイコン**\
- ナレッジベースの名前を決定します。\
- 絵文字を選択、画像をアップロード、または画像URLを貼り付けてこのナレッジベースのアイコンとして設定できます。
-- **ナレッジベース説明**\
- ナレッジベースの簡単な説明を入力してください。これによりAIがデータをより適切に理解し検索できるようになります。空のままにすると、Difyはデフォルトの検索戦略を適用します。
-- **権限**\
- ドロップダウンメニューから適切なアクセス権限を選択してください。
+左パネルの「設定」をクリックし、以下を設定してください。
+- **名前とアイコン**
+ ナレッジベース名を決定します。絵文字選択、画像アップロード、画像URLによるアイコン設定が可能です。
+- **ナレッジベース説明**
+ 簡単な説明を記入してください。AIがデータをより適切に理解し検索できるようになります。未入力の場合はDifyのデフォルト検索戦略が使われます。
+- **権限**
+ ドロップダウンから適切なアクセス権限を選択してください。
---
## ステップ6:テスト
-いよいよ最終工程です!これがナレッジパイプラインオーケストレーションの最終ステップです。
-
-オーケストレーションが完了したら、まずすべての設定を検証する必要があります。次に、いくつかの実行テストを行い、すべての設定を確認します。最後に、ナレッジパイプラインを公開します。
-
-### 設定完全性チェック
-
-テスト前に、設定の不備によるテスト失敗を避けるため、設定の完全性をチェックすることをお勧めします。
+いよいよ最終工程です!
-右上のチェックリストボタンをクリックすると、システムが不足している部分を表示します。
+設定が整ったら、まずは全設定の完全性チェックを行いましょう。チェックは右上のチェックリストボタンで行え、不足項目があると通知されます。
-
+
-すべての設定が完了したら、テスト実行を通じてナレッジベースパイプラインの動作をプレビューし、すべての設定が正確であることを確認してから、公開に進みます。
+全設定完了後、テスト実行でパイプライン全体の動作確認を行い、不備がないことを確認した上で公開します。
### テスト実行
-
-
-1. **テスト開始**:右上の「テスト実行」ボタンをクリック
-2. **テストファイルインポート**:右側にポップアップするデータソースウィンドウでファイルをインポート
-
-
- **重要:** デバッグと観察を容易にするため、テスト実行ごとに1ファイルのみアップロード可能です。
-
+
-3. **パラメータ入力**:インポート成功後、先に設定したユーザー入力フォームに従って対応するパラメータを入力
-4. **テスト実行開始**:次のステップをクリックしてパイプライン全体のテストを開始
+1. **テスト開始**:**テスト実行**をクリック
+2. **テストファイルインポート**:右側ウィンドウからファイル選択
+
+ **注意:** デバッグのため、1回につき1ファイルのみアップロード可能です。
+
+3. **パラメータ入力**:設定した入力フォームに従い必要なパラメータを入力
+4. **パイプライン実行**:**次へ**をクリックしテスト開始
-テスト中は、[履歴ログ](/ja/use-dify/monitor/logs)(タイムスタンプ、実行ステータス、入出力サマリーを含むすべての実行記録を追跡)と[変数インスペクタ](/ja/use-dify/debug/variable-inspect)(各ノードの入出力データを表示し、問題の特定とデータフローの検証を支援するダッシュボード)にアクセスして、効率的なトラブルシューティングとエラー修正を行えます。
+テスト時は、[履歴ログ](/ja/use-dify/monitor/logs)(実行記録の確認)や[変数インスペクタ](/ja/use-dify/debug/variable-inspect)(ノード入出力内容の可視化)が問題特定に役立ちます。

\ No newline at end of file
diff --git a/ja/use-dify/knowledge/knowledge-request-rate-limit.mdx b/ja/use-dify/knowledge/knowledge-request-rate-limit.mdx
index ae1f68e2e..3d08a1587 100644
--- a/ja/use-dify/knowledge/knowledge-request-rate-limit.mdx
+++ b/ja/use-dify/knowledge/knowledge-request-rate-limit.mdx
@@ -6,9 +6,11 @@ tag: "CLOUD"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
+Dify クラウドサービスの安定性を維持し、すべてのユーザーにより良いナレッジベース利用体験を向上させるため、**2025 年 2 月 24 日** よりナレッジリクエストレート頻度制限(Knowledge Request Rate Limit)を導入します。
+
## ナレッジベースの要求頻度制限とは?
-「Dify Cloud」では、ナレッジリクエスト頻度制限とは、ワークスペースが1分間にナレッジベース内で実行できる操作の最大回数を指します。これには、データセットの作成、ドキュメントの管理、アプリやワークフローでのクエリ実行などが含まれます。
+ナレッジリクエスト頻度制限とは、1つのワークスペースがナレッジベースに対して1分間に実行できる最大リクエスト数のことです。この操作には、データセットの作成、ドキュメントの管理、アプリケーションやワークフローにおけるナレッジベースのクエリなどが含まれます。
## サブスクリプションバージョンの制限値
diff --git a/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx b/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
index 9574965c3..ec9a20284 100644
--- a/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
+++ b/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
@@ -7,9 +7,7 @@ sidebarTitle: コンテンツの管理
## ドキュメントの管理
-ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。
-
-ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
+ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
画面上部のナレッジベース名をクリックすると、他のナレッジベースへ素早く切り替えできます。
@@ -22,31 +20,29 @@ sidebarTitle: コンテンツの管理
| 追加 | 新しいドキュメントをインポートします。|
| チャンク設定の変更 | ドキュメントのチャンク設定を変更します(チャンク構造を除く)。各ドキュメントには個別のチャンク設定を持たせることができますが、チャンク構造はナレッジベース全体で共通であり、一度設定すると変更できません。 |
| 削除 | ドキュメントを完全に削除します。**削除は元に戻せません。**|
-| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
非アクティブ期間はプランごとに異なります: |
+| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
非アクティブ期間はプランごとに異なります: |
| アーカイブ/アーカイブ解除 | 検索には不要だが保持しておきたいドキュメントをアーカイブします。アーカイブ済みドキュメントは読み取り専用で、いつでもアーカイブ解除可能です。|
| 編集 | ドキュメント内のチャンクを編集して、コンテンツを修正します。詳細は [チャンクの管理](#チャンクの管理) を参照してください。|
| 名前を変更 | ドキュメントの名前を変更します。|
## チャンクの管理
-チャンク設定に基づき、すべてのドキュメントは検索の基本単位であるコンテンツチャンクに分割されます。
-
-各ドキュメント内のチャンク一覧からそれらを閲覧・管理し、検索の効率と精度を向上させることができます。
+チャンク設定に基づき、すべてのドキュメントは検索の基本単位であるコンテンツチャンクに分割されます。各ドキュメント内のチャンク一覧からそれらを閲覧・管理し、検索の効率と精度を最適化できます。
- 左上のドキュメント名をクリックすると、別のドキュメントへ素早く切り替えられます。
+ 左上のドキュメント名をクリックして、別のドキュメントに素早く切り替えられます。

| 操作 | 説明 |
|:-------- |:---------------------|
-| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。
親子分割モードのドキュメントでは、親チャンクと子チャンクの両方を追加可能です。「チャンクを追加」は Dify Cloud の有料機能です。利用するには [Professional または Team プラン](https://dify.ai/pricing) へのアップグレードが必要です。 |
+| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。
親子分割モード(階層分割モード)のドキュメントでは、親チャンクと子チャンクの両方を追加可能です。「チャンクを追加」は有料機能です。Dify Cloud で利用するには [Professional または Team プラン](https://dify.ai/jp/pricing) へのアップグレードが必要です。 |
| 削除 | チャンクを完全に削除します。**削除は元に戻せません。**|
| 有効/無効 | 一時的にチャンクを検索対象に含める/除外します。無効化されたチャンクは編集できません。|
-| 編集 | チャンクの内容を修正します。編集されたチャンクには **Edited** マークが付きます。
親子分割モードのドキュメントでは:
1つのチャンクにつき最大10個のキーワードを設定可能です。| -| 画像添付ファイルの追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。
抽出された画像のURLはチャンクテキスト内に残りますが、テキストをきれいに保つためにこれらのURLを安全に削除できます。抽出された画像には影響しません。各チャンクには最大10枚まで画像の添付が可能で、検索時にチャンクと一緒に返されます。この制限を超える画像は抽出されません。
セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` でこの制限を調整できます。 マルチモーダル埋め込みモデル(**Vision** アイコン付き)を選択すると、抽出された画像も埋め込み・インデックス化され、検索に利用されます。 |
+| 編集 | チャンクの内容を修正します。編集されたチャンクは **「編集済み」** と表示されます。
親子分割モード(階層分割モード)のドキュメントでは:ドキュメント内の画像が添付ファイルとして抽出される場合、そのURLはチャンクテキスト内に残ります。これらのURLを削除しても、抽出された画像の添付ファイルには影響しません。 |
+| キーワードの追加/編集/削除 | 経済的インデックス方式を使用するナレッジベースでは、各チャンクに対してキーワードを追加・編集して検索精度を向上させることができます。
1つのチャンクにつき最大10個のキーワードを設定可能です。 | +| 画像の追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。
画像の添付ファイルとチャンクは独立して編集でき、互いに影響しません。 各チャンクには最大10枚まで画像の添付が可能で、検索時に一緒に返されます。これを超える画像は抽出されません。
セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` を変更してこの制限を調整できます。 クロスモーダル検索(テキストと画像の両方を意味的関連性に基づいて検索)を有効にするには、ナレッジベースに多モーダル埋め込みモデル(**Vision** アイコン付き)を選択してください。画像の添付ファイルは埋め込み・インデックス化され、検索に利用されます。 |
## ベストプラクティス
@@ -64,7 +60,7 @@ sidebarTitle: コンテンツの管理
### 子チャンクを親チャンクの検索フックとして使用
-親子分割モードで分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
+親子分割モード(階層分割モード)で分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
そのためには、子チャンクを **キーワード**・**要約**・**ユーザーの一般的な質問** のいずれかに書き換えることを推奨します。
たとえば、親チャンクが *返品ポリシー* 全体を扱う場合、子チャンクを次のように設定できます:
@@ -73,4 +69,4 @@ sidebarTitle: コンテンツの管理
- 「返金期間はどのくらいですか?」
-- 「返品時の送料はかかりますか?」
\ No newline at end of file
+- 「返品時の送料はかかりますか?」
diff --git a/ja/use-dify/monitor/logs.mdx b/ja/use-dify/monitor/logs.mdx
index cca606395..d0bf5ec81 100644
--- a/ja/use-dify/monitor/logs.mdx
+++ b/ja/use-dify/monitor/logs.mdx
@@ -53,17 +53,15 @@ AIが不適切な応答をしたり、ユーザーの意図を理解できなか
**フィードバック分析**
一般的な苦情パターン、成功したやり取りタイプ、改善が必要な分野を特定できます。
-## ログの保持期間
+## データ保持
アプリケーションが現地のデータプライバシー規制に準拠していることを確認してください。プライバシーポリシーを公開し、必要に応じ
- - **Sandbox**:ログは30日間保持されます。
-
- - **Professional & Team**:アクティブなサブスクリプション期間中はログ保持期間が無制限です。
-
- - **セルフホスト**:デフォルトで無制限ですが、環境変数 `WORKFLOW_LOG_CLEANUP_ENABLED`、`WORKFLOW_LOG_RETENTION_DAYS`、`WORKFLOW_LOG_CLEANUP_BATCH_SIZE` で設定可能です。
+**無料プラン:** ログは30日間保持されます
+**有料プラン:** プラン階層に基づく延長保持
+**セルフホスト:** 設定可能な保持ポリシー
## ログを使ったアプリケーションの改善
diff --git a/ja/use-dify/nodes/human-input.mdx b/ja/use-dify/nodes/human-input.mdx
new file mode 100644
index 000000000..a545ed556
--- /dev/null
+++ b/ja/use-dify/nodes/human-input.mdx
@@ -0,0 +1,83 @@
+---
+title: 人間の入力
+description: ワークフローを一時停止して、人間の入力、レビュー、または決定を要求します
+icon: user-magnifying-glass
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/human-input)を参照してください。
+
+人間の入力ノードは、実行が続行される前に人間の入力を要求するため、重要なポイントでワークフローを一時停止します。
+
+実行がこのノードに到達すると、カスタマイズ可能なリクエストフォームが特定のチャネルを通じて配信されます。受信者は入力を提供し、データをレビューし、ワークフローの進行方法を決定する事前定義されたアクション(`Approve`や`Regenerate`など)から選択できます。
+
+人間の入力を重要な場所に直接埋め込むことで、**自動化された効率性と人間の監視のバランス**を取ることができます。
+
+ +
+## 設定
+
+ノードが人間の入力を要求し処理する方法を定義するために、以下を設定します:
+
+- **配信方法**:リクエストフォームが受信者に届く方法。
+
+- **フォーム内容**:受信者が見る情報と入力できる内容。
+
+- **ユーザーアクション**:受信者が取れるアクションと、それに応じてワークフローがどのように進行するか。
+
+- **タイムアウト戦略**:設定された時間内に誰も応答しない場合の対応。
+
+### 配信方法
+
+リクエストフォームが配信されるチャネルを選択します。現在利用可能な方法:
+
+- **Webアプリ**:現在のユーザーが応答できるように、Webアプリインターフェースに直接リクエストフォームを表示します。
+
+- **メール**:1人以上の受信者にリクエストフォームのリンクを含むメールを直接送信します。
+
+
+
+## 設定
+
+ノードが人間の入力を要求し処理する方法を定義するために、以下を設定します:
+
+- **配信方法**:リクエストフォームが受信者に届く方法。
+
+- **フォーム内容**:受信者が見る情報と入力できる内容。
+
+- **ユーザーアクション**:受信者が取れるアクションと、それに応じてワークフローがどのように進行するか。
+
+- **タイムアウト戦略**:設定された時間内に誰も応答しない場合の対応。
+
+### 配信方法
+
+リクエストフォームが配信されるチャネルを選択します。現在利用可能な方法:
+
+- **Webアプリ**:現在のユーザーが応答できるように、Webアプリインターフェースに直接リクエストフォームを表示します。
+
+- **メール**:1人以上の受信者にリクエストフォームのリンクを含むメールを直接送信します。
+
+
+ 配信方法に関係なく、最初の応答後にリクエストは閉じられます。
+
+
+### フォーム内容
+
+リクエストフォームに表示される内容をカスタマイズします:
+
+- **Markdown**構文を使用してコンテンツをフォーマットおよび構造化します
+
+- 利用可能な**変数**を参照して動的データを表示します
+
+
+ 推論モデルの`text`出力変数を参照すると、フォームには最終的な回答とともにモデルの思考プロセスが表示されます。
+
+ 回答のみを表示するには、対応するLLMノードで**推論タグ分離を有効にする**をオンにしてください。
+
+
+- 受信者が入力や編集を行える対話型の**入力フィールド**を追加します
+
+
+ 入力フィールドは、受信者が編集できる変数または静的コンテンツで事前入力できます。
+
+ 各入力フィールドは、下流のノードで使用するための出力変数になります。
+
+
+### ユーザーアクション
+
+受信者がクリックできる決定ボタンを定義します。
+
+各ボタンは人間の入力ノードから対応する分岐を作成し、行われた決定に基づいて実行をルーティングします。
+
+例えば、`Post`分岐はコンテンツの公開をトリガーするノードにつながり、`Regenerate`分岐はコンテンツを修正するためにLLMノードにループバックする場合があります。
+
+
+ プリセットのボタンスタイルを使用して、アクションを視覚的に区別します。
+
+ 例えば、`Approve`のような主要なアクションには目立つスタイルを使用し、二次的なオプションにはより控えめなスタイルを使用します。
+
+
+### タイムアウト戦略
+
+指定された期間内に誰も応答しない場合にワークフローがどのように進行するかを決定するタイムアウト戦略を設定します。
+
+- **タイムアウト期間**:タイムアウトになるまでの待機時間(時間または日単位)。
+
+- **タイムアウトパス**:タイムアウト期間内に誰も応答しない場合に従う分岐。通知またはデフォルトの決定につながる場合があります。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/ifelse.mdx b/ja/use-dify/nodes/ifelse.mdx
index 51f7c387f..c864b4ecc 100644
--- a/ja/use-dify/nodes/ifelse.mdx
+++ b/ja/use-dify/nodes/ifelse.mdx
@@ -6,6 +6,7 @@ icon: "code-branch"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/ifelse)を参照してください。
+
If-Elseノードは、定義した条件に基づいて実行を異なるパスにルーティングすることで、ワークフローに意思決定ロジックを追加します。変数を評価し、ワークフローが従うべき分岐を決定します。
@@ -28,11 +29,11 @@ If-Elseノードは、定義した条件に基づいて実行を異なるパス
- **Contains** / **Not contains** - 値が特定の単語やフレーズを含むかチェック
+ **Contains** / **Not contains** - テキストが特定の単語やフレーズを含むかチェック
**Starts with** / **Ends with** - パターンマッチングのためにテキストの始まりや終わりをテスト
- **Is** / **Is not** - 完全値マッチング
+ **Is** / **Is not** - 正確なテキスト比較のための完全値マッチング
@@ -58,6 +59,18 @@ If-Elseノードは、定義した条件に基づいて実行を異なるパス
## 変数参照
-条件で以前のワークフローノードからの任意の変数を参照します。変数は、ユーザー入力、LLMレスポンス、API呼び出し、または他のワークフローノード出力から取得できます。
+条件で以前のワークフローノードからの任意の変数を参照します。変数は、ユーザー入力、大規模言語モデルのレスポンス、API呼び出し、または他のワークフローノード出力から取得できます。
+
+変数セレクターを使用して利か、`{{variable_name}}`構文を使用して変数名を直接入力します。
+
+## 共通パターン
+
+**コンテンツルーティング** - カテゴリ、言語、または複雑さに基づいて、異なるタイプのコンテンツを専用の処理ノードに振り分けます。
+
+**ユーザー役割管理** - ユーザー権限、サブスクリプションレベル、またはアカウントタイプに基づいて異なるワークフロー動作を実装します。
+
+**エラーハンドリング** - レスポンス状態コード、データ妥当性、または処理結果をチェックして、ワークフローを適切にルーティングします。
+
+**動的処理** - 入力特性、処理結果、または外部条件に基づいてワークフロー動作を調整します。
-変数セレクターを使用して利用可能な変数から選択するか、`{{variable_name}}`構文を使用して変数名を直接入力します。
\ No newline at end of file
+**マルチパスワークフロー** - アプリケーションのさまざまなシナリオやエッジケースを処理する洗練された分岐ロジックを作成します。
diff --git a/ja/use-dify/nodes/knowledge-retrieval.mdx b/ja/use-dify/nodes/knowledge-retrieval.mdx
index 3c73bd49d..a5730f298 100644
--- a/ja/use-dify/nodes/knowledge-retrieval.mdx
+++ b/ja/use-dify/nodes/knowledge-retrieval.mdx
@@ -7,50 +7,48 @@ icon: "database"
## はじめに
-知識検索ノードを使用すると、既存のナレッジベースをChatflowやワークフローに統合できます。このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
+知識検索ノードを使用すると、既存のナレッジベースを Chatflow や Workflow に統合できます。
-以下はChatflowにおける知識検索ノードの利用例です:
+このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
+
+以下は Chatflow における 知識検索ノード の利用例です:
1. **ユーザー入力** ノードがユーザーの質問を収集します。
-2. **知識検索** ノードが選択されたナレッジベースからユーザーの質問に関連するコンテンツを検索し、検索結果を出力します。
+2. **知識検索** ノードが選択されたナレッジベースから関連情報を検索し、結果を出力します。
-3. **LLM** ノードがユーザーの質問と検索されたナレッジの両方をもとに回答を生成します。
+3. **LLM** ノードがユーザー質問と検索結果の両方をもとに回答を生成します。
-4. **回答** ノードがLLMの応答をユーザーへ返します。
+4. **回答** ノードが LLM の出力をユーザーへ返します。

- 知識検索ノードを使用する前に、少なくとも1つのナレッジベースが利用可能であることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
-
-
-
- Dify Cloudでは、知識検索の操作は契約プランに応じたレートリミットが適用されます。詳細は[ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
-
+ 知識検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースが存在することを確認してください。
-## 設定
-
-知識検索ノードを正常に機能させるには、次の点を指定する必要があります:
+ ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成) を参照してください。
+
-- **何を**検索するか(クエリ)
+## 知識検索ノードの設定
-- **どこを**検索するか(ナレッジベース)
+知識検索ノードを正常に機能させるには、次の3点を指定する必要があります:
-- **どのように**検索結果を処理するか(ノードレベルの検索設定)
+- **何を検索するか**(クエリ)
+- **どこを検索するか**(ナレッジベース)
+- **どのように検索結果を処理するか**(ノードレベルの検索設定)
また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
### クエリの指定
-ノードが選択されたナレッジベースで検索するクエリ内容を指定します。
+ノードが選択されたナレッジベースで検索する対象を指定します。
-- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflowでは`userinput.query`を使用してユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
+- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflow では `userinput.query`(ユーザー入力ノードの入力)を指定できます。Workflow ではテキスト型のユーザー入力変数を利用します。
-- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は2 MBです。
+ **クエリ画像**:画像検索を行う場合は、ユーザー入力ノードを通じてアップロードされた画像など、画像変数を選択してください。最大サイズは 2 MB です。
- セルフホスト環境では、環境変数`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`を変更することで画像サイズ上限を調整できます。
+ 自己ホスティング環境では、環境変数 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` を変更することで画像サイズ上限を調整できます。
@@ -61,76 +59,82 @@ icon: "database"
### 検索対象ナレッジベースの選択
-ノードでクエリ内容に関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
+ノードで検索対象とするナレッジベースを1つ以上追加します。
-複数のナレッジベースを追加した場合、まずすべてのナレッジベースから同時に検索を行い、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果を統合・処理します。
+複数のナレッジベースを追加した場合、すべてのナレッジベースから同時に検索を行い、その結果を統合して[ノードレベルの検索設定](#ノードレベルの検索設定)に従って処理します。
- **Vision**アイコンが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
+ **Vision**アイコンが付いたナレッジベースは、セマンティックな関連性に基づいてテキストと画像の両方をクロスモーダルで検索できます。
- 追加したナレッジベースの横にある**編集**アイコンをクリックすると、知識検索ノード内で直接その設定を変更できます。
-
- これらの設定の詳細については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
+ ノード内で任意のナレッジベースの **編集** アイコンをクリックすると、直接その設定を変更できます。
+
+ 詳細な設定方法については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
### ノードレベルの検索設定
-ナレッジベースから取得した検索結果を、ノード内でどのように処理するかを微調整できます。
+ナレッジベースから取得した検索結果を、ノード内でどのように絞り込み・再ランク付けするかを調整できます。
- 検索設定には2つのレイヤーがあります—ナレッジベースレベルと知識検索ノードレベルです。
-
- これらは2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
+ 検索設定には2つのレイヤー(階層)があります。
+
+ ナレッジベースレベルの設定が最初の検索プールを決定し、ノードレベルの設定がその結果を再スコアリングまたは絞り込みします。
-- **Rerank設定**
+- **Rerank 設定**
- - **ウェイト設定**:再ランク付け時におけるセマンティック類似度とキーワード一致の相対的な比重です。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
+ - **ウェイト設定**: 再ランク付け時におけるセマンティック類似度(意味の近さ)とキーワード一致の比重を調整します。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
- **ウェイト設定**は、追加したナレッジベースがすべて高品質タイプである場合のみ利用できます。
+ **ウェイト設定** は、追加したナレッジベースがすべて「高品質」タイプである場合に利用できます。
- - **Rerankモデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えするRerankモデルです。
+ - **Rerank モデル**: クエリとの関連度に基づいてすべての検索結果を再スコアリング・並べ替えします。
+
+
+ 選択したナレッジベースの中にマルチモーダル対応のものが含まれている場合は、**Vision**アイコンが表示されたマルチモーダル再ランクモデルを選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
+
+
+- **トップ K**: 再ランク後に返す最大件数を指定します。 Rerank モデルを選択している場合、この値はモデルが処理可能な最大入力サイズ(トークン上限)に応じて自動的に調整されます。
- マルチモーダルナレッジベースが追加されている場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像は再ランク付けおよび最終出力から除外されます。
+ 選択したナレッジベースの中にマルチモーダル対応のものが含まれている場合は、**Vision**アイコンが表示されたマルチモーダル再ランクモデルを選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
-- **トップK**:再ランク後に返す結果の最大件数です。Rerankモデルを選択している場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
-
-- **スコア閾値**:返される結果の最低類似度スコアです。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
+- **スコア閾値**: 結果を返す際の最低スコア(類似度)を指定します。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
### メタデータフィルタの有効化
-既存のドキュメントメタデータを使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
-
-メタデータフィルタを有効にすると、知識検索ノードはナレッジベース全体を検索するのではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。これは、大規模で多様なナレッジベースでのターゲット検索に特に有用です。
+ナレッジベース内のドキュメントメタデータを利用して、特定の条件に合致するドキュメントのみを検索対象とすることができます。これにより、大規模または多様なナレッジベース内での検索精度が向上します。
- ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata)を参照してください。
+ ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata) を参照してください。
## 出力
-知識検索ノードの出力は`result`という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
+知識検索ノードの出力は `result` という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクには内容・メタデータ・タイトルなどの情報が含まれます。
-検索結果に画像添付が含まれる場合、`result`変数には画像メタデータを含む`files`というフィールドも含まれます。
+検索結果に画像が含まれる場合、`result` 変数には画像の詳細が格納された `files` フィールドも含まれます。
-## LLMノードとの連携
+## LLM ノードとの連携
-LLMノードでユーザーの質問に回答するためのコンテキストとして検索結果を使用するには:
+検索結果を活用して LLM ノードで質問応答を行うには:
-1. **コンテキスト**フィールドで、知識検索ノードの`result`変数を選択します。
+1. **コンテキスト** フィールドで、知識検索ノードの `result` 変数を選択します。
-2. プロンプトフィールドで、`Context`変数とユーザー入力変数(例:Chatflowの`userinput.query`)の両方を参照します。
+2. LLM のプロンプト入力欄では、`コンテキスト` 変数とユーザー入力変数(例:Chatflow の `userinput.query`)の両方を参照してください。
-3. (任意)LLMがVision機能に対応している場合(**Vision**アイコン付き)、**Vision**を有効にして検索された画像を解釈させることができます。
+3. (任意)LLMがVision機能に対応している場合は、**Vision**を有効にすると、`コンテキスト`変数内の画像添付を解釈できるようになります。
- **Vision**を有効にすると、LLMは検索された画像を自動的に処理します。**Vision**入力フィールドで`Context`変数を再度手動で参照する必要はありません。
+ **Vision**を有効にすると、LLMは`コンテキスト`変数内の画像を直接理解できます。別途**Vision**入力変数を設定する必要はありません。
- +
+
+
+
+
+
+ Dify Cloud では、知識検索の操作は契約プランに応じたレートリミット(リクエスト上限)が適用されます。詳細は [ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit) を参照してください。
+
\ No newline at end of file
diff --git a/ja/use-dify/nodes/list-operator.mdx b/ja/use-dify/nodes/list-operator.mdx
index e0400a3fe..a287c5554 100644
--- a/ja/use-dify/nodes/list-operator.mdx
+++ b/ja/use-dify/nodes/list-operator.mdx
@@ -6,9 +6,8 @@ icon: "filter"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/list-operator)を参照してください。
-リスト演算子ノードは、配列のフィルタリング、ソート、特定の要素の選択を行います。混合ファイルアップロード、大規模なデータセット、または下流処理の前に分離や整理が必要な配列データを扱う際に使用します。
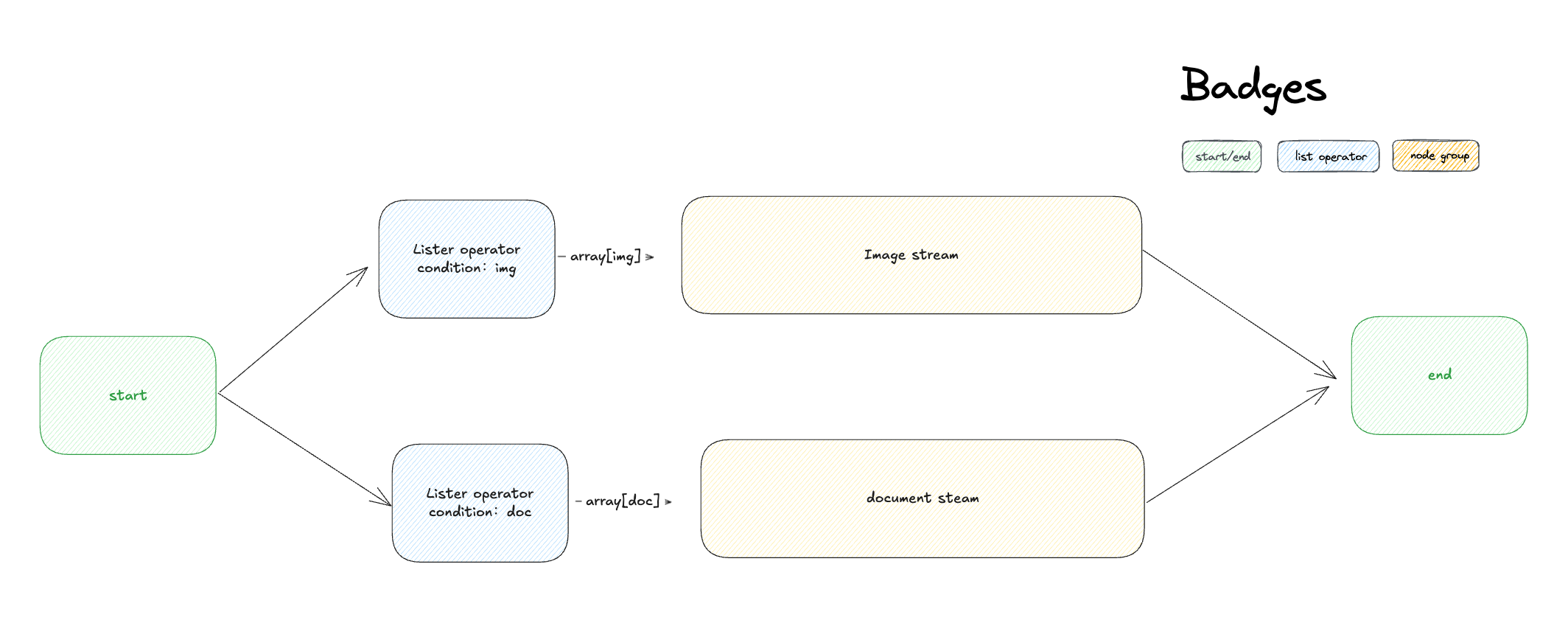
-サポートされる入力データ型には、`array[string]`、`array[number]`、`array[file]`、`array[boolean]`があります。
+リスト演算子ノードは、配列のフィルタリング、ソート、特定の要素の選択を行います。混合ファイルアップロード、大規模なデータセット、または下流処理の前に分離や整理が必要な配列データを扱う際に使用します。
 @@ -24,6 +23,16 @@ icon: "filter"
@@ -24,6 +23,16 @@ icon: "filter"
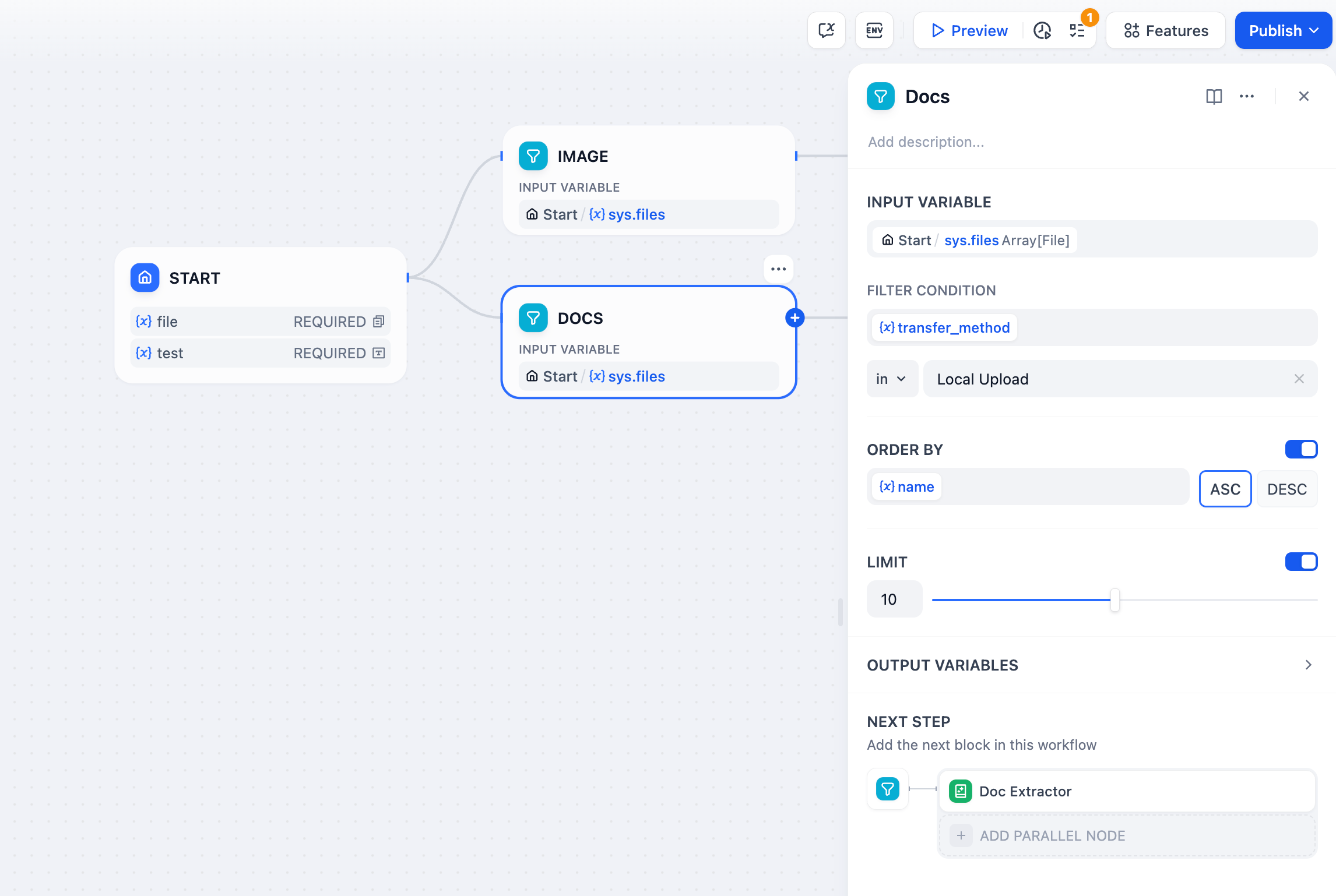 +## サポートされるデータ型
+
+ノードは適切なフィルタリングオプションを使用して、さまざまな配列タイプを処理します:
+
+**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
+
+**Array[number]** - 数値データ、スコア、測定値、または計算結果
+
+**Array[file]** - 豊富なメタデータフィルタリング機能を持つ混合ファイルアップロード
+
## 操作
### フィルタリング
@@ -70,7 +79,7 @@ icon: "filter"
**result** - バルク処理用の完全なフィルタリングおよびソート済み配列
-**first_record** - 先頭からの単一要素、「主要」または「最新」アイテム選択に最適
+**first_record** - 先頭からの単一要素、「プテム選択に最適
**last_record** - 末尾からの単一要素、「最新」または「最終」選択に有用
@@ -86,9 +95,31 @@ icon: "filter"
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効化
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリスト演算子ノードを使用:
- - `type = "image"`でフィルタリング → ビジョン機能を持つLLMにルーティング
+ - `type = "image"`でフィルタリング → ビジョン機能を持つ大規模言語モデルにルーティング
- `type = "document"`でフィルタリング → 文書抽出器にルーティング
3. **適切に処理** - 画像は直接分析され、文書はテキスト抽出が行われる
4. **結果を結合** - 処理された出力を統一されたレスポンスにマージ
-このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
\ No newline at end of file
+このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
+
+## 一般的な使用例
+
+**ファイルタイプルーティング** - 混合アップロードをコンテンツタイプに基づいて専門的な処理パイプラインに分離
+
+**データフィルタリング** - 特定の基準に基づいて大規模なデータセットから関連するサブセットを抽出
+
+**コンテンツ優先順位付け** - コレクションから最も重要または最新のアイテムをソートして選択
+
+**品質管理** - 処理前に無効、過大サイズ、またはサポートされていないコンテンツをフィルターで除外
+
+**バッチ準備** - 下流の反復処理や並列処理のためにデータを管理可能なチャンクに整理
+
+## ベストプラクティス
+
+**フィルター基準の計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義
+
+**適切な出力タイプの使用** - 下流ノードがデータをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択
+
+**空の結果の処理** - フィルターが一致しない場合の対処法を検討し、適切なフォールバックロジックを計画
+
+**実データでのテスト** - 本番環境での信頼性のある動作を保証するために、実際のユーザーアップロードでフィルタリング動作を検証
diff --git a/ja/use-dify/nodes/llm.mdx b/ja/use-dify/nodes/llm.mdx
index 5b00f5892..e5fb911fd 100644
--- a/ja/use-dify/nodes/llm.mdx
+++ b/ja/use-dify/nodes/llm.mdx
@@ -6,6 +6,7 @@ icon: "brain"
+## サポートされるデータ型
+
+ノードは適切なフィルタリングオプションを使用して、さまざまな配列タイプを処理します:
+
+**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
+
+**Array[number]** - 数値データ、スコア、測定値、または計算結果
+
+**Array[file]** - 豊富なメタデータフィルタリング機能を持つ混合ファイルアップロード
+
## 操作
### フィルタリング
@@ -70,7 +79,7 @@ icon: "filter"
**result** - バルク処理用の完全なフィルタリングおよびソート済み配列
-**first_record** - 先頭からの単一要素、「主要」または「最新」アイテム選択に最適
+**first_record** - 先頭からの単一要素、「プテム選択に最適
**last_record** - 末尾からの単一要素、「最新」または「最終」選択に有用
@@ -86,9 +95,31 @@ icon: "filter"
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効化
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリスト演算子ノードを使用:
- - `type = "image"`でフィルタリング → ビジョン機能を持つLLMにルーティング
+ - `type = "image"`でフィルタリング → ビジョン機能を持つ大規模言語モデルにルーティング
- `type = "document"`でフィルタリング → 文書抽出器にルーティング
3. **適切に処理** - 画像は直接分析され、文書はテキスト抽出が行われる
4. **結果を結合** - 処理された出力を統一されたレスポンスにマージ
-このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
\ No newline at end of file
+このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
+
+## 一般的な使用例
+
+**ファイルタイプルーティング** - 混合アップロードをコンテンツタイプに基づいて専門的な処理パイプラインに分離
+
+**データフィルタリング** - 特定の基準に基づいて大規模なデータセットから関連するサブセットを抽出
+
+**コンテンツ優先順位付け** - コレクションから最も重要または最新のアイテムをソートして選択
+
+**品質管理** - 処理前に無効、過大サイズ、またはサポートされていないコンテンツをフィルターで除外
+
+**バッチ準備** - 下流の反復処理や並列処理のためにデータを管理可能なチャンクに整理
+
+## ベストプラクティス
+
+**フィルター基準の計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義
+
+**適切な出力タイプの使用** - 下流ノードがデータをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択
+
+**空の結果の処理** - フィルターが一致しない場合の対処法を検討し、適切なフォールバックロジックを計画
+
+**実データでのテスト** - 本番環境での信頼性のある動作を保証するために、実際のユーザーアップロードでフィルタリング動作を検証
diff --git a/ja/use-dify/nodes/llm.mdx b/ja/use-dify/nodes/llm.mdx
index 5b00f5892..e5fb911fd 100644
--- a/ja/use-dify/nodes/llm.mdx
+++ b/ja/use-dify/nodes/llm.mdx
@@ -6,6 +6,7 @@ icon: "brain"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/llm)を参照してください。
+
LLMノードは大規模言語モデルを呼び出してテキスト、画像、ドキュメントを処理します。設定されたモデルにプロンプトを送信し、その応答を取得します。構造化出力、コンテキスト管理、マルチモーダル入力をサポートしています。
@@ -13,18 +14,18 @@ LLMノードは大規模言語モデルを呼び出してテキスト、画像
- LLMノードを使用する前に、**システム設定 → モデルプロバイダー**で少なくとも1つのモデルプロバイダーを設定してください。
+ LLMノードを使用する前に、**システム設定 → モデルプロバイダー**で少なくとも1つのモデルプロバイダーを設定してください。セットアップ手順については[モデル設定ガイド](/en/guides/model-configuration/readme)をご覧ください。
-## モデル選択とパラメータ
+## モデル選択とパラメーター
設定したモデルプロバイダーから任意のモデルを選択できます。異なるモデルはそれぞれ異なるタスクに適しています。GPT-4とClaude 3.5は複雑な推論を得意としますがコストが高く、GPT-3.5 Turboは機能と価格のバランスが取れています。ローカル展開には、Ollama、LocalAI、Xinferenceを使用してください。
-
+
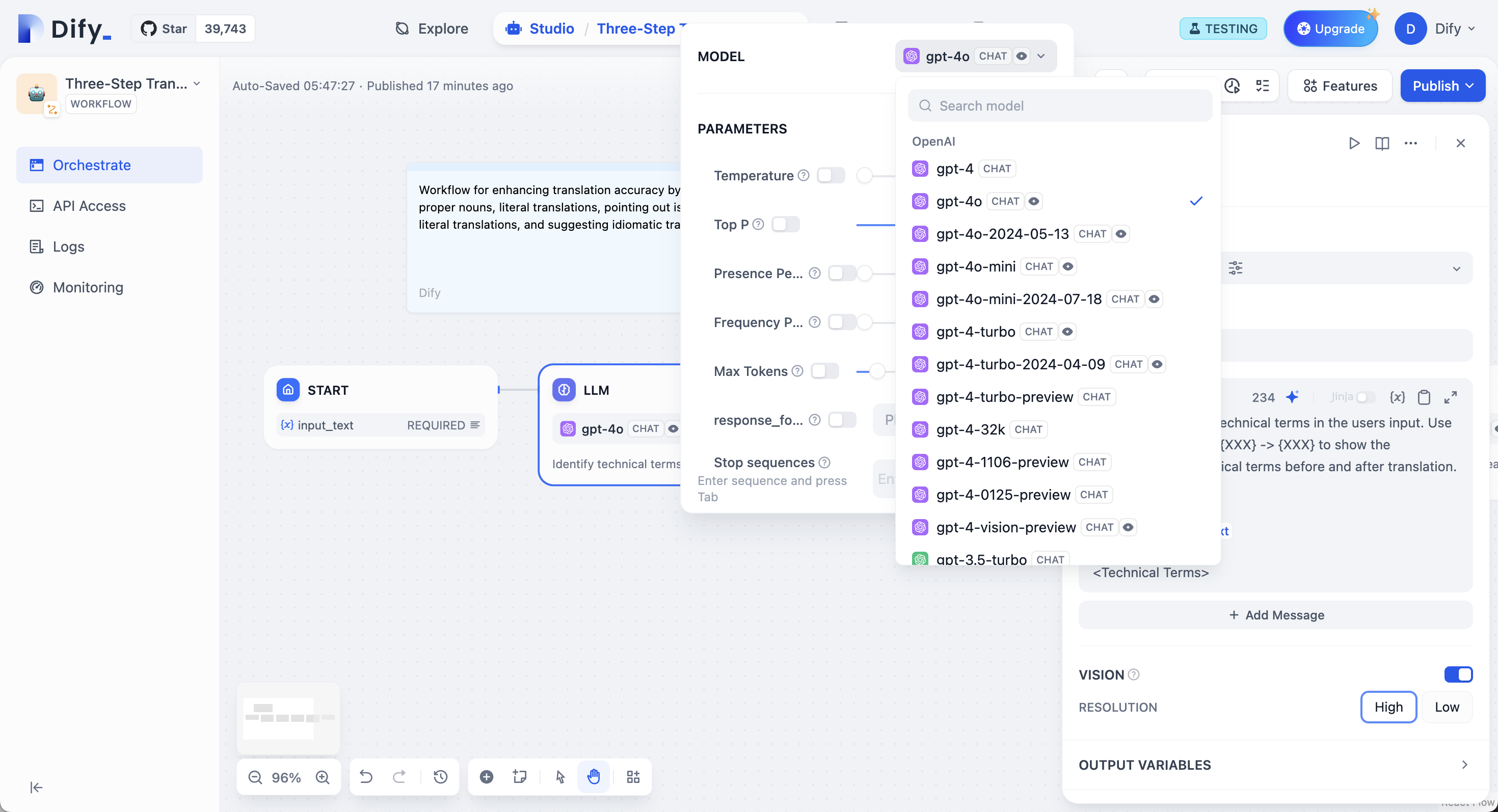 -モデルパラメータは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**Top P**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
+モデルパラメーターは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**核サンプリング**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
## プロンプト設定
@@ -39,7 +40,7 @@ User: {{user_input}}
## コンテキスト変数
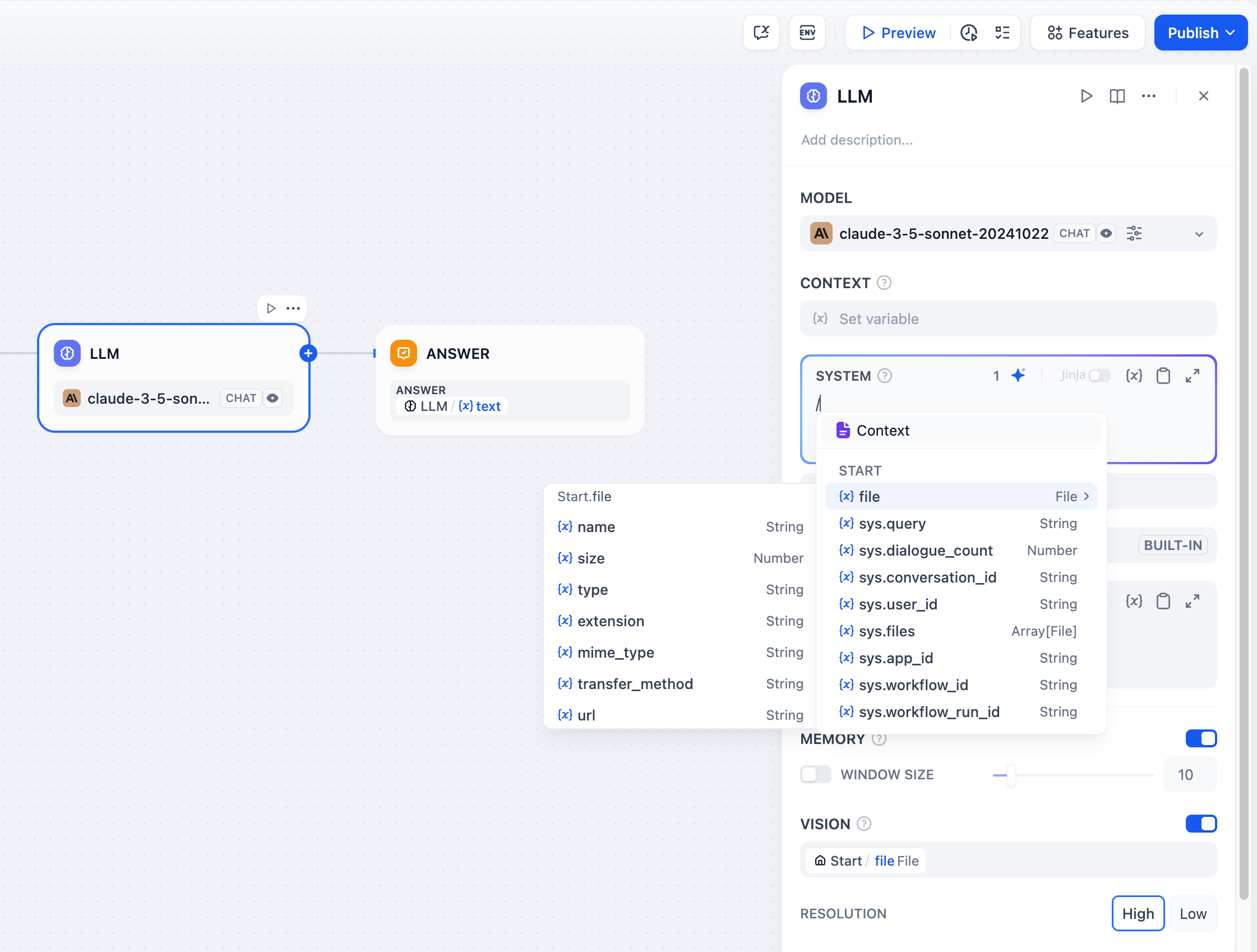
-コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
+コンース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
-モデルパラメータは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**Top P**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
+モデルパラメーターは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**核サンプリング**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
## プロンプト設定
@@ -39,7 +40,7 @@ User: {{user_input}}
## コンテキスト変数
-コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
+コンース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
 @@ -54,7 +55,7 @@ User: {{user_input}}
質問:{{user_question}}
```
-知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用を追跡するため、ユーザーは情報源を確認できます。
+知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用と帰属を追跡するため、ユーザーは情報源を確認できます。
## 構造化出力
@@ -93,10 +94,9 @@ User: {{user_input}}
## メモリとファイル処理
-
-メモリを有効にすると、チャットフロー会話内の複数のLLM呼び出しでコンテキストを維持できます。有効にすると、以前のインタラクションがフォーマットされたユーザー - アシスタント出力として後続のプロンプトに含まれます。`USER`テンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
+**メモリ**を有効にすると、ワークフロー実行内の複数のLLM呼び出しでコンテキストを維持できます。ノードは以前のインタラクションを後続のプロンプトに含めます。メモリはノード固有であり、ワークフロー実行間では持続しません。
-**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像を、ClaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
+**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像をaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
### ビジョン機能設定
@@ -104,12 +104,18 @@ User: {{user_input}}
- **高詳細** - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
- **低詳細** - シンプルな画像でより少ないトークンでより高速な処理
-ビジョン機能のデフォルト変数セレクターは`userinput.files`で、ユーザー入力ノードからファイルを自動的に取得します。
+ビジョン機能のデフォルト変数セレクターは`sys.files`で、開始ノードからファイルを自動的に取得します。
@@ -54,7 +55,7 @@ User: {{user_input}}
質問:{{user_question}}
```
-知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用を追跡するため、ユーザーは情報源を確認できます。
+知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用と帰属を追跡するため、ユーザーは情報源を確認できます。
## 構造化出力
@@ -93,10 +94,9 @@ User: {{user_input}}
## メモリとファイル処理
-
-メモリを有効にすると、チャットフロー会話内の複数のLLM呼び出しでコンテキストを維持できます。有効にすると、以前のインタラクションがフォーマットされたユーザー - アシスタント出力として後続のプロンプトに含まれます。`USER`テンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
+**メモリ**を有効にすると、ワークフロー実行内の複数のLLM呼び出しでコンテキストを維持できます。ノードは以前のインタラクションを後続のプロンプトに含めます。メモリはノード固有であり、ワークフロー実行間では持続しません。
-**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像を、ClaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
+**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像をaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
### ビジョン機能設定
@@ -104,12 +104,18 @@ User: {{user_input}}
- **高詳細** - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
- **低詳細** - シンプルな画像でより少ないトークンでより高速な処理
-ビジョン機能のデフォルト変数セレクターは`userinput.files`で、ユーザー入力ノードからファイルを自動的に取得します。
+ビジョン機能のデフォルト変数セレクターは`sys.files`で、開始ノードからファイルを自動的に取得します。
 +補完モデルでの会話履歴については、マルチターンコンテキストを維持するために会話変数を挿入します:
+
+
+
+補完モデルでの会話履歴については、マルチターンコンテキストを維持するために会話変数を挿入します:
+
+
+ 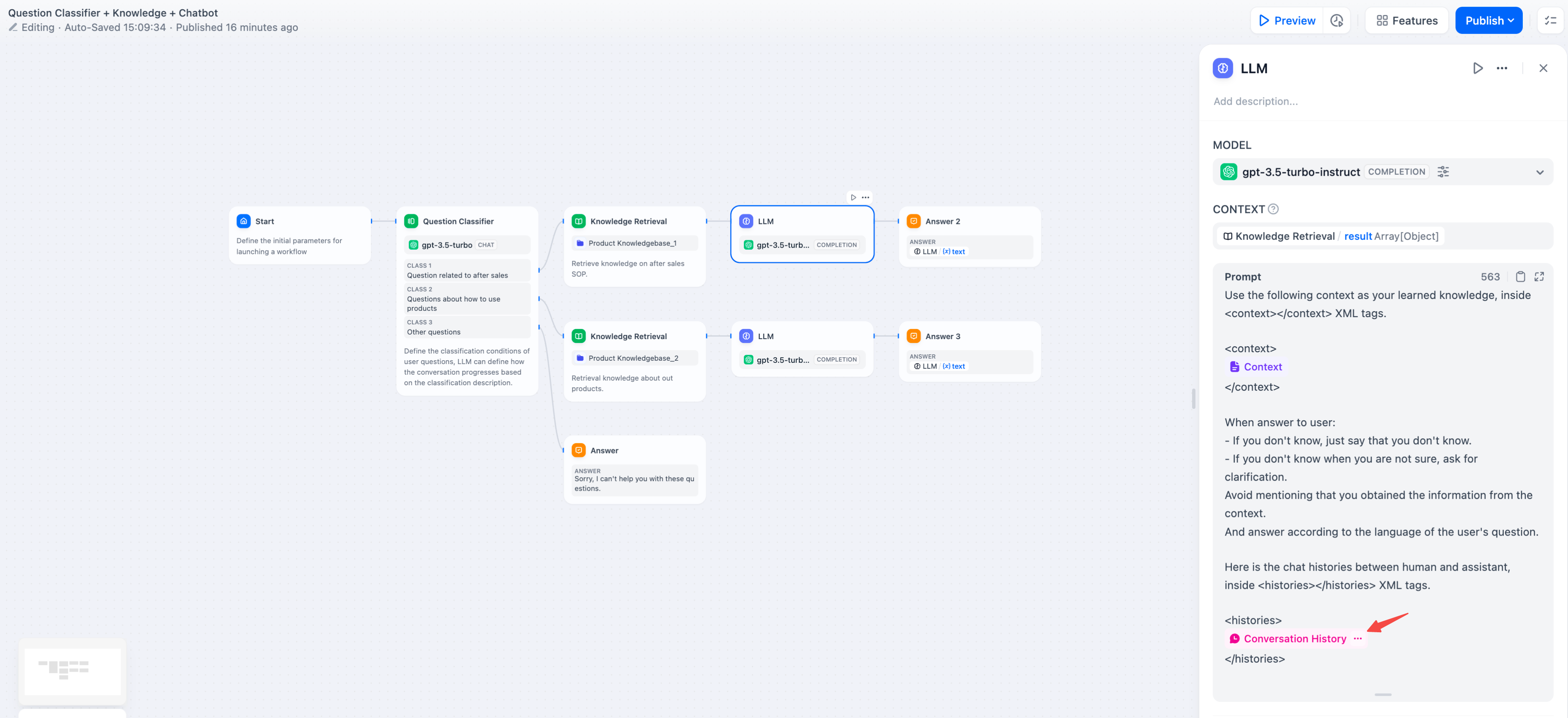 +
+
## Jinja2テンプレートサポート
LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(`edition_type: "jinja2"`)を使用すると、次のことができます:
@@ -122,9 +128,9 @@ LLMプロンプトは高度な変数処理のためにJinja2テンプレート
Jinja2変数は通常の変数置換とは別に処理され、プロンプト内でループ、条件文、複雑なデータ変換が可能になります。
-## ストリーミング出力
+## ストリーミングレスポンス
-LLMノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
+LLMノードはデフォルトでストリーミングレスポンスをサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
## エラーハンドリング
diff --git a/ja/use-dify/nodes/trigger/overview.mdx b/ja/use-dify/nodes/trigger/overview.mdx
index 87f4edf08..e250ce9aa 100644
--- a/ja/use-dify/nodes/trigger/overview.mdx
+++ b/ja/use-dify/nodes/trigger/overview.mdx
@@ -3,28 +3,26 @@ title: トリガー
sidebarTitle: "概要"
---
-
+
+
## Jinja2テンプレートサポート
LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(`edition_type: "jinja2"`)を使用すると、次のことができます:
@@ -122,9 +128,9 @@ LLMプロンプトは高度な変数処理のためにJinja2テンプレート
Jinja2変数は通常の変数置換とは別に処理され、プロンプト内でループ、条件文、複雑なデータ変換が可能になります。
-## ストリーミング出力
+## ストリーミングレスポンス
-LLMノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
+LLMノードはデフォルトでストリーミングレスポンスをサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
## エラーハンドリング
diff --git a/ja/use-dify/nodes/trigger/overview.mdx b/ja/use-dify/nodes/trigger/overview.mdx
index 87f4edf08..e250ce9aa 100644
--- a/ja/use-dify/nodes/trigger/overview.mdx
+++ b/ja/use-dify/nodes/trigger/overview.mdx
@@ -3,28 +3,26 @@ title: トリガー
sidebarTitle: "概要"
---
- ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/trigger/overview)を参照してください。
-
## はじめに
- トリガーはワークフローアプリケーションでのみ利用可能です。
+ トリガーは workflow アプリケーションでのみ利用可能です。
-トリガーは開始ノードの一種で、ユーザーや API 呼び出しによる能動的な開始を待つのではなく、スケジュールに従って、または外部システム(例:GitHub、Gmail、または独自の内部システム)からのイベントに応じて、ワークフローを自動的に実行できるようにします。
+トリガーは開始ノードの一種で、ユーザーや API 呼び出しによる能動的な開始を待つのではなく、スケジュールに従って、または外部システム(例:GitHub、Gmail、または独自の内部システム)からのイベントに応じて、workflow を自動的に実行できるようにします。
-トリガーは、反復タスクの自動化や、ワークフローをサードパーティアプリケーションと統合して自動的なデータ同期と処理を実現するのに最適です。
+トリガーは、反復タスクの自動化や、workflow をサードパーティアプリケーションと統合して自動的なデータ同期と処理を実現するのに最適です。
-1 つのワークフローは、並行して実行される複数のトリガーを持つことができます。また、同じキャンバス上に複数の独立したワークフローを構築し、それぞれが独自のトリガーで開始することもできます。
+1 つの workflow は、並行して実行される複数のトリガーを持つことができます。また、同じキャンバス上に複数の独立した workflow を構築し、それぞれが独自のトリガーで開始することもできます。
- Sandbox プランでは、ワークフローあたり 2 つのトリガーのみがサポートされています。追加するには[アップグレード](https://dify.ai/pricing)してください。
+ Sandbox プランでは、workflow あたり 2 つのトリガーのみがサポートされています。追加するには[アップグレード](https://dify.ai/jp/pricing)してください。
-各ワークフロー実行のトリガーソースは、**ログ**セクションに表示されます。
+各 workflow 実行のトリガーソースは、**ログ**セクションに表示されます。
- Dify Cloud では、トリガーイベント(トリガーによって開始されるワークフロー実行)はプランごとに異なる上限が設定されています。詳細は[プラン比較](https://dify.ai/pricing)をご覧ください。
+ Dify Cloud では、トリガーイベント(トリガーによって開始される workflow 実行)はプランごとに異なる上限が設定されています。詳細は[プラン比較](https://dify.ai/jp/pricing)をご覧ください。
ワークスペースのオーナーおよび管理者は、**設定** > **請求**で残りのクォータを確認できます。
@@ -33,28 +31,24 @@ sidebarTitle: "概要"
- [スケジュールトリガー](/ja/use-dify/nodes/trigger/schedule-trigger)
- - 指定された時刻または間隔でワークフローを実行します。
+ - 指定された時刻または間隔で workflow を実行します。
- 例:毎朝 9 時に日次売上レポートを自動生成し、チームにメールで送信します。
-
- 各ワークフローには最大 1 つのスケジュールトリガーを設定できます。
-
-
- [プラグイントリガー](/ja/use-dify/nodes/trigger/plugin-trigger)
- - トリガープラグインを通じたイベントサブスクリプションにより、外部システムで特定のイベントが発生したときにワークフローを実行します。
+ - トリガープラグインを通じたイベントサブスクリプションにより、外部システムで特定のイベントが発生したときに workflow を実行します。
- 例:Slack トリガープラグインを通じて`チャンネル内の新規メッセージ`イベントをサブスクライブすることで、特定の Slack チャンネル内の新規メッセージを自動的に分析およびアーカイブします。
- [Webhook トリガー](/ja/use-dify/nodes/trigger/webhook-trigger)
- - カスタム webhook を介して外部システムで特定のイベントが発生したときにワークフローを実行します。
+ - カスタム webhook を介して外部システムで特定のイベントが発生したときに workflow を実行します。
- 例:e コマースプラットフォームから注文詳細を含む HTTP リクエストに応答して、新規注文を自動的に処理します。
- プラグイントリガーと webhook トリガーは、どちらもワークフローを*イベント駆動型*にします。選択方法は次のとおりです:
+ プラグイントリガーと webhook トリガーは、どちらも workflow を*イベント駆動型*にします。選択方法は次のとおりです:
1. 対象の外部システムにトリガープラグインが利用可能な場合は、**プラグイントリガー**を使用してください。サポートされているイベントを簡単にサブスクライブできます。
@@ -63,7 +57,7 @@ sidebarTitle: "概要"
## トリガーの有効化または無効化
-**クイック設定**サイドメニューでは、公開済みのトリガーを有効化または無効化できます。無効化されたトリガーはワークフローの実行を開始しません。
+**クイック設定**サイドメニューでは、公開済みのトリガーを有効化または無効化できます。無効化されたトリガーは workflow の実行を開始しません。
**クイック設定**には、公開済みのトリガーのみが表示されます。トリガーがリストに表示されない場合は、まず公開されていることを確認してください。
@@ -73,7 +67,7 @@ sidebarTitle: "概要"
## 複数のトリガーをテストする
-ワークフローに複数のトリガーがある場合、**テスト実行** > **すべてのトリガーを実行**をクリックして一度にテストできます。最初にアクティブ化されたトリガーがワークフローを開始し、他のトリガーは無視されます。
+workflow に複数のトリガーがある場合、**テスト実行** > **すべてのトリガーを実行**をクリックして一度にテストできます。最初にアクティブ化されたトリガーが workflow を開始し、他のトリガーは無視されます。
**すべてのトリガーを実行**をクリックすると:
@@ -81,4 +75,4 @@ sidebarTitle: "概要"
- プラグイントリガーはサブスクライブされたイベントをリッスンします。
-- Webhook トリガーは外部 HTTP リクエストをリッスンします。
\ No newline at end of file
+- Webhook トリガーは受信 HTTP リクエストをリッスンします。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/trigger/plugin-trigger.mdx b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
index 5d912d3b8..3026c746e 100644
--- a/ja/use-dify/nodes/trigger/plugin-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/plugin-trigger.mdx
@@ -2,32 +2,30 @@
title: プラグイントリガー
---
- ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/trigger/plugin-trigger)を参照してください。
-
## はじめに
- トリガーはワークフローアプリケーションでのみ利用可能です。
+ トリガーは workflow アプリケーションでのみ利用可能です。
-プラグイントリガーは、外部システムで特定のイベントが発生したときに自動的にワークフローを開始します。必要なのは、トリガープラグインを通じてこれらのイベントをサブスクライブし、対応するプラグイントリガーをワークフローに追加することだけです。
+プラグイントリガーは、外部システムで特定のイベントが発生したときに自動的に workflow を開始します。必要なのは、トリガープラグインを通じてこれらのイベントをサブスクライブし、対応するプラグイントリガーを workflow に追加することだけです。
-例えば、GitHub トリガープラグインをインストールしたとします。これは、`Pull Request`、`Push`、`Issue` を含む、サブスクライブできる GitHub イベントのリストを提供します。`Pull Request` イベントをサブスクライブし、`Pull Request` プラグイントリガーをワークフローに追加すると、指定されたリポジトリで誰かがプルリクエストを開くたびに自動的に実行されます。
+例えば、GitHub トリガープラグインをインストールしたとします。これは、`Pull Request`、`Push`、`Issue` を含む、サブスクライブできる GitHub イベントのリストを提供します。`Pull Request` イベントをサブスクライブし、`Pull Request` プラグイントリガーを workflow に追加すると、指定されたリポジトリで誰かがプルリクエストを開くたびに自動的に実行されます。
## プラグイントリガーの追加と設定
-1. ワークフローキャンバスで右クリックし、**ブロックを追加** > **始める** を選択してから、利用可能なプラグイントリガーの中から選択するか、[Dify Marketplace](https://marketplace.dify.ai/?language=jp-ja&category=trigger) でさらに検索します。
+workflow キャンバスで右クリックし、**ブロックを追加** > **始める** を選択してから、利用可能なプラグイントリガーの中から選択するか、[Dify Marketplace](https://marketplace.dify.ai/?language=jp-ja&category=trigger) でさらに検索します。
- 対象の外部システムに適切なトリガープラグインがない場合は、[コミュニティにリクエスト](https://github.com/langgenius/dify-plugins/issues/new?template=plugin_request.yaml)したり、[自分で開発](/ja/develop-plugin/dev-guides-and-walkthroughs/trigger-plugin)したり、代わりに [Webhook トリガー](/ja/use-dify/nodes/trigger/webhook-trigger)を使用したりできます。
- - 1 つのワークフローは、並行して実行される複数のプラグイントリガーで開始できます。並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+ - 1 つの workflow は、並行して実行される複数のプラグイントリガーで開始できます。並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
2. 既存のサブスクリプションを選択するか、[新しいサブスクリプションを作成](#新しいサブスクリプションを作成)します。
- **プラグイン**配下のプラグイン詳細パネルから、特定のサブスクリプションを使用しているワークフローの数を確認できます。
+ **プラグイン**配下のプラグイン詳細パネルから、特定のサブスクリプションを使用している workflow の数を確認できます。
3. その他の必要な設定を行います。
@@ -38,6 +36,10 @@ title: プラグイントリガー
## 新しいサブスクリプションを作成
+
+ サブスクリプションは一度作成すると変更できません。変更するには、既存のサブスクリプションを削除して新しいサブスクリプションを作成してください。
+
+
トリガープラグインは、ワークスペースごとに最大 10 個のサブスクリプションをサポートします。
@@ -61,7 +63,7 @@ Dify は以下の 2 つの方法でサブスクリプション(Webhook)を
サブスクリプションを作成する際は、利用可能なすべてのイベントを選択することをお勧めします。
- プラグイントリガーは、対応するイベントがリンクされたサブスクリプションに含まれている場合にのみ機能します。利用可能なすべてのイベントを選択すると、後でワークフローに追加するプラグイントリガーが同じサブスクリプションを使用でき、サブスクリプションを更新したり新しく作成したりする必要がなくなります。
+ プラグイントリガーは、対応するイベントがリンクされたサブスクリプションに含まれている場合にのみ機能します。利用可能なすべてのイベントを選択すると、後で workflow に追加するプラグイントリガーが同じサブスクリプションを使用でき、別のサブスクリプションを作成する必要がなくなります。
@@ -90,7 +92,7 @@ Dify は以下の 2 つの方法でサブスクリプション(Webhook)を
3. サブスクリプション名を指定し、サブスクライブするイベントを選択し、その他の必要な設定を行います。
- 利用可能なすべてのイベントを選択することをお勧めしますが、後から**プラグイン**配下のプラグイン詳細パネルでいつでも選択を変更できます。
+ 利用可能なすべてのイベントを選択することをお勧めします。
4. **作成**をクリックします。
@@ -111,7 +113,7 @@ Dify は以下の 2 つの方法でサブスクリプション(Webhook)を
4. サブスクリプション名を指定し、サブスクライブするイベントを選択し、その他の必要な設定を行います。
- 利用可能なすべてのイベントを選択することをお勧めしますが、後から**プラグイン**配下のプラグイン詳細パネルでいつでも選択を変更できます。
+ 利用可能なすべてのイベントを選択することをお勧めします。
5. **作成**をクリックします。
@@ -136,7 +138,7 @@ Dify は以下の 2 つの方法でサブスクリプション(Webhook)を
3. サブスクリプション名を指定し、サブスクライブするイベントを選択し、その他の必要な設定を行います。
- 利用可能なすべてのイベントを選択することをお勧めしますが、後から**プラグイン**配下のプラグイン詳細パネルでいつでも選択を変更できます。
+ 利用可能なすべてのイベントを選択することをお勧めします。
4. **作成**をクリックします。
@@ -181,4 +183,4 @@ Dify は以下の 2 つの方法でサブスクリプション(Webhook)を
## プラグイントリガーをテストする
-未公開のプラグイントリガーをテストするには、まず**このステップ実行**をクリックするか、ワークフロー全体をテスト実行する必要があります。これによりトリガーがリスニング状態になり、外部イベントを監視できるようになります。そうしないと、イベントが発生してもトリガーはサブスクライブしたイベントをキャプチャしません。
\ No newline at end of file
+未公開のプラグイントリガーをテストするには、まず**このステップ実行**をクリックするか、workflow 全体をテスト実行する必要があります。これによりトリガーがリスニング状態になり、外部イベントを監視できるようになります。そうしないと、イベントが発生してもトリガーはサブスクライブしたイベントをキャプチャしません。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/trigger/schedule-trigger.mdx b/ja/use-dify/nodes/trigger/schedule-trigger.mdx
index 83ea1ad94..a46f13914 100644
--- a/ja/use-dify/nodes/trigger/schedule-trigger.mdx
+++ b/ja/use-dify/nodes/trigger/schedule-trigger.mdx
@@ -2,21 +2,21 @@
title: スケジュールトリガー
---
- ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/trigger/schedule-trigger)を参照してください。
-
## はじめに
- - トリガーはワークフローアプリケーションでのみ利用可能です。
-
- - 各ワークフローには最大1つのスケジュールトリガーを設定できます。
+ トリガーは workflow アプリケーションでのみ利用可能です。
-スケジュールトリガーを使用すると、指定した時刻または間隔でワークフローを実行できます。これは、日次レポートの生成やスケジュールされた通知の送信など、繰り返し発生するタスクに最適です。
+スケジュールトリガーを使用すると、指定した時刻または間隔で workflow を実行できます。これは、日次レポートの生成やスケジュールされた通知の送信など、繰り返し発生するタスクに最適です。
## スケジュールトリガーの追加
-ワークフローキャンバスで右クリックし、**ブロックを追加** > **始める** > **スケジュールトリガー** を選択します。
+workflow キャンバスで右クリックし、**ブロックを追加** > **始める** > **スケジュールトリガー** を選択します。
+
+
+ 1 つの workflow は、並行して実行される複数のスケジュールトリガーで開始できます。並行分岐に同一の連続したノードが含まれている場合、共通セクションの前に[変数集約](/ja/use-dify/nodes/variable-aggregator)ノードを追加して分岐をマージできます。これにより、各分岐で同じノードを個別に重複して追加することを回避できます。
+
## スケジュールトリガーの設定
@@ -25,7 +25,7 @@ title: スケジュールトリガー
設定後、次の 5 回のスケジュール実行時刻を確認できます。
- スケジュールトリガーは出力変数を生成しませんが、ワークフローをトリガーするたびにシステム変数 `sys.timestamp`(各ワークフロー実行の開始時刻)を更新します。
+ スケジュールトリガーは出力変数を生成しませんが、workflow をトリガーするたびにシステム変数 `sys.timestamp`(各 workflow 実行の開始時刻)を更新します。
### ビジュアル設定を使用
@@ -42,7 +42,7 @@ title: スケジュールトリガー
#### 標準フォーマット
-Cron 式は、ワークフローの実行スケジュールを定義する文字列です。スペースで区切られた 5 つのフィールドで構成され、それぞれが異なる時間単位を表します。
+Cron 式は、workflow の実行スケジュールを定義する文字列です。スペースで区切られた 5 つのフィールドで構成され、それぞれが異なる時間単位を表します。
各フィールド間に 1 つのスペースがあることを確認してください。
@@ -59,14 +59,15 @@ Cron 式は、ワークフローの実行スケジュールを定義する文字
```
+
**日**と**曜日**の両方のフィールドが指定されている場合、トリガーは*どちらか*のフィールドに一致する日付でアクティブになります。
-
- 例えば、`1 2 3 4 4` は、4 月 3 日*および* 4 月の毎週木曜日にワークフローをトリガーします。4 月 3 日が木曜日である場合に限定されません。
+
+ 例えば、`1 2 3 4 4` は、4 月 3 日*および* 4 月の毎週木曜日に workflow をトリガーします。4 月 3 日が木曜日である場合に限定されません。
#### 特殊文字
-| 文字 | 説明 | 例 |
+| ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
+ ⚠️ このドキュメントは AI によって自動翻訳されています。不正確な点がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
## はじめに
-ユーザー入力ノードでは、アプリケーションへの入力としてエンドユーザーから収集する内容を定義できます。
+ユーザー入力ノードは、アプリケーションの実行時にエンドユーザーから収集する情報を定義できる開始ノードの一種です。
-このノードで開始するアプリケーションは*オンデマンド*で実行され、直接的なユーザー操作または API 呼び出しによって開始できます。
-
-これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
+このノードで開始するアプリケーションは、直接的なユーザー操作または API 呼び出しによって開始される*オンデマンド*で実行されます。これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
各アプリケーションキャンバスには、ユーザー入力ノードを 1 つだけ含めることができます。
@@ -36,16 +34,16 @@ icon: "input-text"
### カスタム
-ユーザー入力ノードでカスタム入力フィールドを設定して、さまざまな種類のユーザー入力を収集できます。各フィールドは、下流のノードから参照できる変数になります。
+ユーザー入力ノードでカスタム入力フィールドを構成して、エンドユーザーから情報を収集できます。各フィールドは、ダウンストリームノードが参照できる変数になります。たとえば、変数名 `user_name` の入力フィールドを追加すると、ワークフロー全体で `{{user_name}}` として参照できます。
+
+さまざまな種類のユーザー入力を処理するために、7 種類の入力フィールドから選択できます。
**ラベル名**はエンドユーザーに表示されます。
- チャットフローアプリケーションでは、任意のユーザー入力フィールドを**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
-
- **必須**フィールドは非表示にできないことに注意してください。
+ チャットフローアプリケーションでは、任意の入力変数を**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
#### テキスト入力
@@ -53,11 +51,11 @@ icon: "input-text"
- 最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
+ 短いテキストフィールドは最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
- 長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
+ 段落フィールドは長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
@@ -66,21 +64,15 @@ icon: "input-text"
- 事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
+ 選択フィールドは、事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
- 数値のみに入力を制限します。数量、評価、ID、または数学的処理を必要とするデータに最適です。
+ 数値フィールドは数値のみに入力を制限します—数量、評価、ID、または数学的処理を必要とするデータに最適です。
- シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になり、それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
-
-
-
- JSON オブジェクト形式のデータを受け付けます。複雑でネストされたデータ構造をアプリケーションに渡すのに最適です。
-
- オプションで JSON スキーマを定義して、入力を検証し、ユーザーに期待されるデータ構造と検証要件を示すことができます。スキーマを定義すると、他のノードでオブジェクトの個々のプロパティを参照することもできます。
+ チェックボックスフィールドは、シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になります。それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
@@ -88,12 +80,11 @@ icon: "input-text"
- ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
+ 単一ファイルフィールドを使用すると、ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
- 一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
-
+ ファイルリストフィールドは単一ファイルと同様に機能しますが、一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
リスト演算子ノードを使用して、アップロードされたファイルリストから特定のファイルをフィルタリング、並べ替え、または抽出して、さらに処理することができます。
@@ -102,16 +93,16 @@ icon: "input-text"
**ファイル処理**
-ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしないため、アップロードされたファイルは後続のノードによって適切に処理される必要があります。例えば:
+ユーザー入力ノードを介してアップロードされたファイルは、後続のノードによって適切に処理される必要があります。ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしません。
-- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出のためにドキュメント抽出器ノードにルーティングできます。
+したがって、ファイルコンテンツを抽出して処理するために特定のノードを接続する必要があります。例えば:
+- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出のためにドキュメント抽出器ノードにルーティングできます。
- 画像は、ビジョン機能を持つ LLM ノードまたは専用の画像処理ツールノードに送信できます。
-
- CSV や JSON などの構造化データファイルは、コードノードを使用して解析および変換できます。
- ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、異なる処理ブランチにルーティングできます。
+ ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、適切な処理ブランチにルーティングできます。
## 次のステップ
@@ -119,7 +110,5 @@ icon: "input-text"
ユーザー入力ノードを設定したら、収集したデータを処理する他のノードに接続できます。一般的なパターンには次のものがあります:
- 入力を LLM ノードに送信して処理する。
-
-- ナレッジ検索ノードを使用して、入力に関連する情報を検索する。
-
-- If/Else ノードを使用して、入力に基づいて条件分岐を作成する。
\ No newline at end of file
+- ナレッジ検索ノードを使用して、入力に基づいて関連情報を検索する。
+- 入力に基づいて条件ロジックを使用して実行パスを異なるブランチにルーティングする。
diff --git a/ja/use-dify/nodes/variable-aggregator.mdx b/ja/use-dify/nodes/variable-aggregator.mdx
index 7efce6a75..0c7db92c0 100644
--- a/ja/use-dify/nodes/variable-aggregator.mdx
+++ b/ja/use-dify/nodes/variable-aggregator.mdx
@@ -6,6 +6,7 @@ icon: "merge"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-aggregator)を参照してください。
+
変数アグリゲーターノードは、異なる実行パスからの変数を単一の統一された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一つの一貫した変数参照を作成することで、下流での重複処理の必要性を排除します。
## 分岐の問題
@@ -51,10 +52,9 @@ icon: "merge"
**同一型ルール** - すべての集約された変数は同じデータ型である必要があります。最初の変数(例:文字列)を接続すると、ノードは他のブランチから同じ型の変数のみを受け入れます。
**サポートされる型:**
-- **文字列** - 異なる処理ブランチからのテキスト出力
+- **文字列** - 異なる処理力
- **数値** - 数値計算、スコア、または測定値
- **オブジェクト** - 類似のスキーマを持つ構造化データオブジェクト
-- **ブール値** - True/false値
- **配列** - リスト、コレクション、または複数の結果
### 出力動作
@@ -67,4 +67,24 @@ icon: "merge"
高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同一ノード内で異なるデータ型を並行して集約することができます。
-これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
\ No newline at end of file
+これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
+
+## 一般的な使用例
+
+**マルチカテゴリ処理** - 異なるコンテンツタイプには専用の処理が必要ですが、共通の下流ロジックに供給される類似の出力を生成します。
+
+**条件付きデータソース** - 異なる条件が異なる知識検索やAPI呼び出しをトリガーしますが、すべての結果には同じ最終処理が必要です。
+
+**ブランチ結果の統合** - 複雑な分岐ロジックがさまざまな出力を生成しますが、最終的には統一された処理が必要です。
+
+**エラー処理** - メイン処理とフォールバックブランチが異なるが互換性のある結果を生成し、下流ノードが一貫して処理できます。
+
+## ベストプラクティス
+
+**データ型の計画** - 変数アグリゲーターに接続する前に、すべてのブランチが互換性のあるデータ型を生成することを確認します。
+
+**一貫した出力構造** - オブジェクトや配列を集約する際は、予測可能な下流処理のためにすべてのブランチで一貫した構造を維持します。
+
+**説明的な名前を使用** - 集約された変数には、複数の可能なソースからの結果を含むことを明確に示す名前を付けます。
+
+**すべてのブランチをテスト** - 各可能な実行パスが、集約時に正しく動作する有効な出力を生成することを確認します。
diff --git a/ja/use-dify/nodes/variable-assigner.mdx b/ja/use-dify/nodes/variable-assigner.mdx
index c05106c60..8f8e58e4f 100644
--- a/ja/use-dify/nodes/variable-assigner.mdx
+++ b/ja/use-dify/nodes/variable-assigner.mdx
@@ -6,7 +6,8 @@ icon: "pen-to-square"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-assigner)を参照してください。
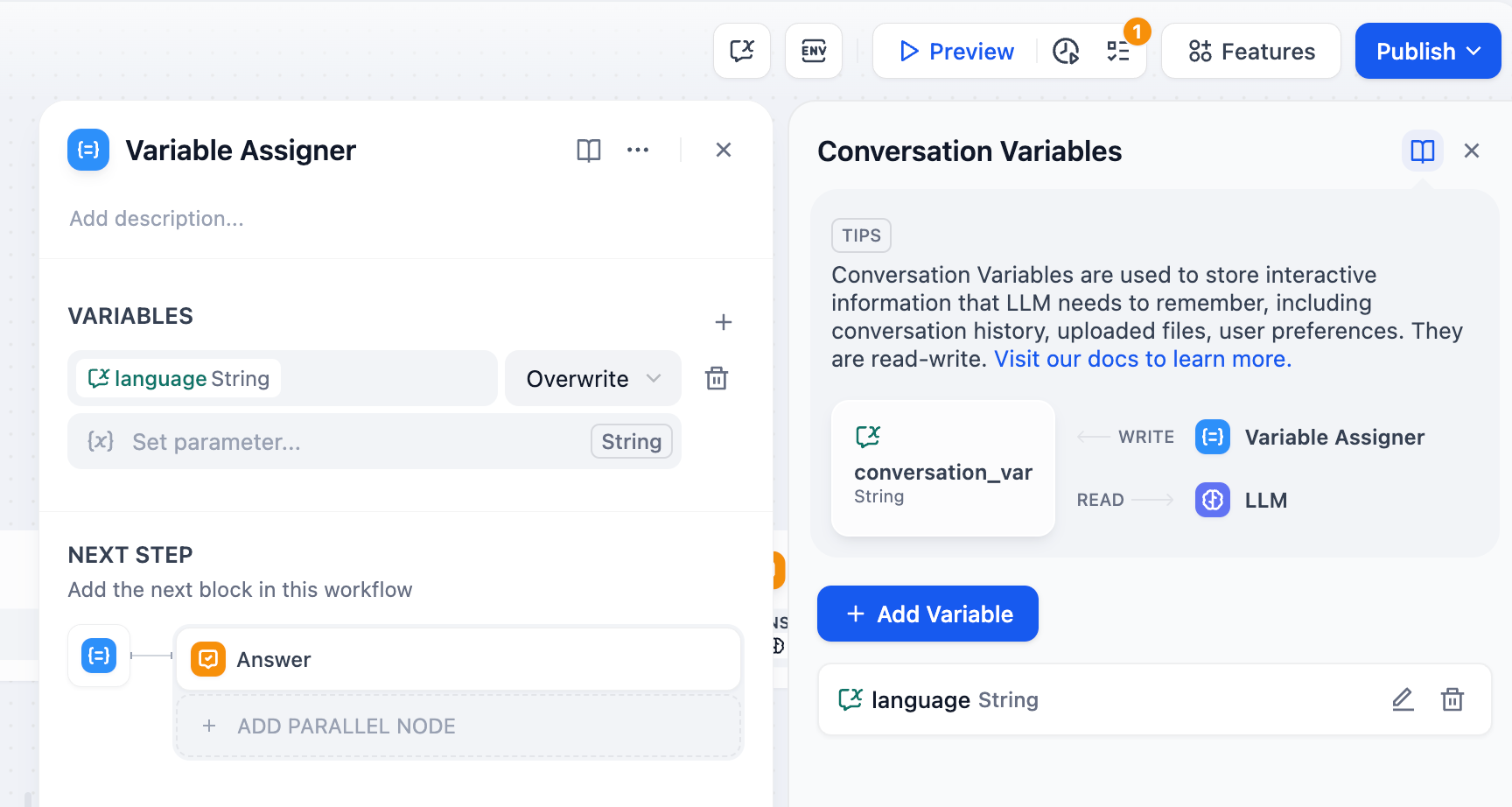
-変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](/ja/use-dify/getting-started/key-concepts#変数)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
+
+変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](jp/use-dify/getting-started/key-concepts#variables)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
 @@ -39,64 +40,52 @@ icon: "pen-to-square"
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
@@ -39,64 +40,52 @@ icon: "pen-to-square"
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
-
- - **上書き** - 別の文字列変数で置き換える
+
+ **上書き** - 文字列値全体を新しいコンテンツで置き換える
- - **クリア** - 現在の値を削除する
+ **クリア** - 変数を空にし、nullまたは空白に設定する
- - **設定** - 固定値を手動で割り当てる
+ **設定** - 固定値を手動で入力する
-
- - **上書き** - 別の数値変数で置き換える
+
+ **上書き** - 数値を完全に置き換える
- - **クリア** - 現在の値を削除する
+ **クリア** - nullまたは空の状態に設定する
- - **設定** - 固定値を手動で割り当てる
+ **設定** - 特定の数値を手動で入力する
- - **算術演算** - 現在の値に対して別の数値で加算、減算、乗算、除算を行う
-
-
-
- - **上書き** - 別のブール変数で置き換える
-
- - **クリア** - 現在の値を削除する
-
- - **設定** - 固定値を手動で割り当てる
+ **算術演算** - 現在の値に対して加算、減算、乗算、除算を行う
-
- - **上書き** - 別のオブジェクト変数で置き換える
+
+ **上書き** - オブジェクト全体を新しいデータで置き換える
- - **クリア** - 現在の値を削除する
+ **クリア** - オブジェクトを空にし、すべてのプロパティを削除する
- - **設定** - オブジェクトの構造と値を手動で定義する
+ **設定** - オブジェクトの構造と値を手動で定義する
-
- - **上書き** - 同じタイプの別の配列変数で置き換える
+
+ **上書き** - 配列全体を新しいデータで置き換える
- - **クリア** - 配列からすべての要素を削除する
+ **クリア** - 配列を空にし、すべての要素を削除する
- - **追加** - 配列の最後に1つの要素を追加する
+ **追加** - 配列の最後に1つの項目を追加する
- - **拡張** - 同じタイプの別の配列からすべての要素を追加する
+ **拡張** - 他の配列から複数の項目を追加する
- - **最初/最後を削除** - 配列から最初または最後の要素を削除する
-
-
- 配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
-
-
+ **削除** - 最初または最後の位置から項目を削除する
+配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
## 一般的な実装パターン
### スマートメモリシステム
-会話から重要な情報を自動的に検出・保存するチャットボットを構築:
+会話から重要な情報を自動的に検出・
 @@ -112,7 +101,7 @@ icon: "pen-to-square"
@@ -112,7 +101,7 @@ icon: "pen-to-square"
 -**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべてのLLMレスポンスでそれらを参照します。
+**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべての大規模言語モデルレスポンスでそれらを参照します。
### 段階的チェックリスト
@@ -122,4 +111,16 @@ icon: "pen-to-square"
-**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべてのLLMレスポンスでそれらを参照します。
+**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべての大規模言語モデルレスポンスでそれらを参照します。
### 段階的チェックリスト
@@ -122,4 +111,16 @@ icon: "pen-to-square"
 -配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、LLMはそれを参照してユーザーを残りのタスクを通じてガイドします。
+配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、大規模言語モデルはそれを参照してユーザーを残りのタスクを通じてガイドします。
+
+## ベストプラクティス
+
+**適切なデータタイプを選択** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用する。
+
+**説明的な変数名を使用** - 会話変数の目的と内容を示すように明確に命名する。
+
+**データの成長を処理** - 長い会話での過度なメモリ使用を防ぐため、配列とオブジェクトのサイズを監視する。
+
+**変数を初期化** - 未定義の動作を防ぐため、会話変数に初期値を設定する。
+
+**適切な場合にクリア** - 新しいプロセスやセッションを開始する際に変数をリセットするためにクリア操作を使用する。
diff --git a/ja/use-dify/workspace/api-extension/api-extension.mdx b/ja/use-dify/workspace/api-extension/api-extension.mdx
deleted file mode 100644
index d1aba75ce..000000000
--- a/ja/use-dify/workspace/api-extension/api-extension.mdx
+++ /dev/null
@@ -1,262 +0,0 @@
----
-title: API 拡張
-sidebarTitle: 概要
----
-
-開発者は API 拡張モジュール機能を使用してモジュール機能を拡張できます。現在、以下のモジュール拡張がサポートされています:
-
-* `moderation` センシティブコンテンツ審査
-* `external_data_tool` 外部データツール
-
-モジュール機能を拡張する前に、API と認証用の API Key を準備する必要があります。
-
-対応するモジュール機能を開発する必要があるだけでなく、Dify が API を正しく呼び出せるように、以下の仕様に従う必要があります。
-
-## API 仕様
-
-Dify は以下の仕様でインターフェースを呼び出します:
-
-```
-POST {Your-API-Endpoint}
-```
-
-### Header
-
-| Header | Value | Desc |
-| --------------- | ----------------- | --------------------------------------------------------------------- |
-| `Content-Type` | application/json | リクエストコンテンツは JSON 形式です。 |
-| `Authorization` | Bearer {api_key} | API Key はトークン形式で送信されます。この `api_key` を解析し、提供された API Key と一致することを確認して、インターフェースのセキュリティを確保する必要があります。 |
-
-### Request Body
-
-```
-{
- "point": string, // 拡張ポイント、異なるモジュールには複数の拡張ポイントが含まれる場合があります
- "params": {
- ... // 各モジュール拡張ポイントに渡されるパラメータ
- }
-}
-```
-
-### API レスポンス
-
-```
-{
- ... // API が返すコンテンツ、異なる拡張ポイントのレスポンスについては各モジュールの仕様設計を参照してください
-}
-```
-
-## 検証
-
-Dify で API-based Extension を設定する際、Dify は API の可用性を確認するために API Endpoint にリクエストを送信します。
-
-API Endpoint が `point=ping` を受信したとき、インターフェースは `result=pong` を返す必要があります。具体的には以下の通りです:
-
-### Header
-
-```
-Content-Type: application/json
-Authorization: Bearer {api_key}
-```
-
-### Request Body
-
-```
-{
- "point": "ping"
-}
-```
-
-### API 期待レスポンス
-
-```
-{
- "result": "pong"
-}
-```
-
-## サンプル
-
-ここでは外部データツールを例として、地域に基づいて外部の天気情報をコンテキストとして取得するシナリオを示します。
-
-### API サンプル
-
-```
-POST https://fake-domain.com/api/dify/receive
-```
-
-**Header**
-
-```
-Content-Type: application/json
-Authorization: Bearer 123456
-```
-
-**Request Body**
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-**API レスポンス**
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-### コードサンプル
-
-コードは Python FastAPI フレームワークに基づいています。
-
-1. 依存関係をインストール
-
- ```
- pip install fastapi[all] uvicorn
- ```
-2. インターフェース仕様に従ってコードを記述
-
- ```
- from fastapi import FastAPI, Body, HTTPException, Header
- from pydantic import BaseModel
-
- app = FastAPI()
-
-
- class InputData(BaseModel):
- point: str
- params: dict = {}
-
-
- @app.post("/api/dify/receive")
- async def dify_receive(data: InputData = Body(...), authorization: str = Header(None)):
- """
- Receive API query data from Dify.
- """
- expected_api_key = "123456" # TODO Your API key of this API
- auth_scheme, _, api_key = authorization.partition(' ')
-
- if auth_scheme.lower() != "bearer" or api_key != expected_api_key:
- raise HTTPException(status_code=401, detail="Unauthorized")
-
- point = data.point
-
- # for debug
- print(f"point: {point}")
-
- if point == "ping":
- return {
- "result": "pong"
- }
- if point == "app.external_data_tool.query":
- return handle_app_external_data_tool_query(params=data.params)
- # elif point == "{point name}":
- # TODO other point implementation here
-
- raise HTTPException(status_code=400, detail="Not implemented")
-
-
- def handle_app_external_data_tool_query(params: dict):
- app_id = params.get("app_id")
- tool_variable = params.get("tool_variable")
- inputs = params.get("inputs")
- query = params.get("query")
-
- # for debug
- print(f"app_id: {app_id}")
- print(f"tool_variable: {tool_variable}")
- print(f"inputs: {inputs}")
- print(f"query: {query}")
-
- # TODO your external data tool query implementation here,
- # return must be a dict with key "result", and the value is the query result
- if inputs.get("location") == "London":
- return {
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind "
- "Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
- }
- else:
- return {"result": "Unknown city"}
- ```
-3. API サービスを起動します。デフォルトポートは 8000 で、完全な API アドレスは `http://127.0.0.1:8000/api/dify/receive`、設定された API Key は `123456` です。
-
- ```
- uvicorn main:app --reload --host 0.0.0.0
- ```
-4. Dify でこの API を設定します。
-
-5. App でこの API 拡張を選択します。
-
-App のデバッグ時、Dify は設定された API にリクエストを送信し、以下の内容を送信します(サンプル):
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-API レスポンスは:
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-## ローカルデバッグ
-
-Dify クラウド版では内部ネットワークの API サービスにアクセスできないため、ローカルで API サービスをデバッグするために、[Ngrok](https://ngrok.com) を使用して API サービスのエンドポイントを公開ネットワークに公開し、クラウドでローカルコードをデバッグできるようにします。操作手順:
-
-1. [https://ngrok.com](https://ngrok.com) の公式サイトにアクセスし、登録して Ngrok ファイルをダウンロードします。
-
- 
-
-2. ダウンロード完了後、ダウンロードディレクトリに移動し、以下の説明に従って圧縮ファイルを解凍し、説明の初期化スクリプトを実行します。
- ```Shell
- unzip /path/to/ngrok.zip
- ./ngrok config add-authtoken あなたのToken
- ```
-3. ローカル API サービスのポートを確認します:
-
- 
-
- そして、以下のコマンドを実行して起動します:
-
- ```Shell
- ./ngrok http ポート番号
- ```
-
- 起動成功のサンプルは以下の通りです:
-
- 
-
-4. Forwarding の中から、上図のように `https://177e-159-223-41-52.ngrok-free.app`(これはサンプルドメインです、自分のものに置き換えてください)が公開ネットワークドメインです。
-
-上記のサンプルに従って、ローカルで既に起動されているサービスエンドポイントを公開し、コードサンプルのインターフェース `http://127.0.0.1:8000/api/dify/receive` を `https://177e-159-223-41-52.ngrok-free.app/api/dify/receive` に置き換えます。
-
-この API エンドポイントは公開ネットワークでアクセス可能になります。これで、Dify でこの API エンドポイントを設定してローカルコードをデバッグできます。設定手順については、[外部データツール](/ja/use-dify/workspace/api-extension/external-data-tool-api-extension) を参照してください。
-
-## Cloudflare Workers を使用した API 拡張のデプロイ
-
-API 拡張をデプロイするには Cloudflare Workers の使用をお勧めします。Cloudflare Workers は簡単に公開ネットワークアドレスを提供でき、無料で使用できます。
-
-詳細な説明については、[Cloudflare Workers を使用した API 拡張のデプロイ](/ja/use-dify/workspace/api-extension/cloudflare-worker) を参照してください。
diff --git a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx b/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
deleted file mode 100644
index decc1237f..000000000
--- a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
+++ /dev/null
@@ -1,131 +0,0 @@
----
-title: Cloudflare Workers を使用した API 拡張のデプロイ
----
-
-## はじめに
-
-Dify API 拡張は API Endpoint としてアクセス可能な公開ネットワークアドレスを使用する必要があるため、API 拡張を公開ネットワークアドレスにデプロイする必要があります。
-
-ここでは Cloudflare Workers を使用して API 拡張をデプロイします。
-
-[Example GitHub Repository](https://github.com/crazywoola/dify-extension-workers) をクローンします。このリポジトリには簡単な API 拡張が含まれており、これをベースに変更できます。
-
-```bash
-git clone https://github.com/crazywoola/dify-extension-workers.git
-cp wrangler.toml.example wrangler.toml
-```
-
-`wrangler.toml` ファイルを開き、`name` と `compatibility_date` をアプリケーション名と互換性日付に変更します。
-
-ここで注意が必要な設定は、`vars` 内の `TOKEN` です。Dify で API 拡張を追加する際に、この Token を入力する必要があります。セキュリティ上の理由から、Token としてランダムな文字列を使用することをお勧めします。ソースコードに直接 Token を書き込むのではなく、環境変数を使用して Token を渡すべきです。そのため、wrangler.toml をコードリポジトリにコミットしないでください。
-
-```toml
-name = "dify-extension-example"
-compatibility_date = "2023-01-01"
-
-[vars]
-TOKEN = "bananaiscool"
-```
-
-この API 拡張はランダムな Breaking Bad の名言を返します。`src/index.ts` でこの API 拡張のロジックを変更できます。この例は、サードパーティ API とのやり取り方法を示しています。
-
-```typescript
-// ⬇️ implement your logic here ⬇️
-// point === "app.external_data_tool.query"
-// https://api.breakingbadquotes.xyz/v1/quotes
-const count = params?.inputs?.count ?? 1;
-const url = `https://api.breakingbadquotes.xyz/v1/quotes/${count}`;
-const result = await fetch(url).then(res => res.text())
-// ⬆️ implement your logic here ⬆️
-```
-
-このリポジトリはビジネスロジック以外のすべての設定を簡略化しています。`npm` コマンドを直接使用して API 拡張をデプロイできます。
-
-```bash
-npm install
-npm run deploy
-```
-
-デプロイが成功すると、公開ネットワークアドレスが取得できます。このアドレスを Dify の API Endpoint として追加できます。`endpoint` パスを忘れないでください。このパスの具体的な定義は `src/index.ts` で確認できます。
-
-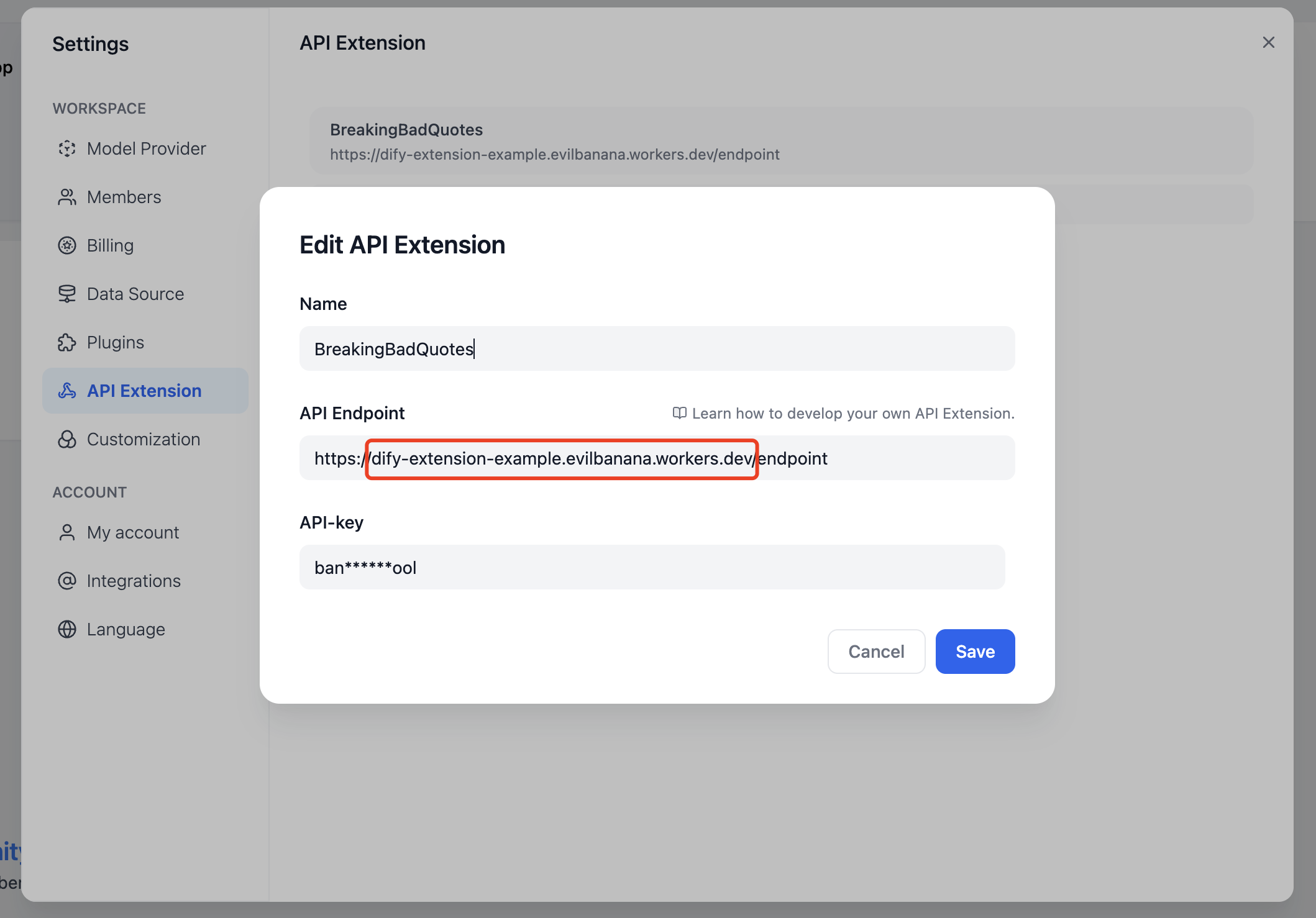
-
-また、`npm run dev` コマンドを使用してローカルにデプロイしてテストすることもできます。
-
-```bash
-npm install
-npm run dev
-```
-
-関連する出力:
-
-```bash
-$ npm run dev
-> dev
-> wrangler dev src/index.ts
-
- ⛅️ wrangler 3.99.0
--------------------
-
-Your worker has access to the following bindings:
-- Vars:
- - TOKEN: "ban****ool"
-⎔ Starting local server...
-[wrangler:inf] Ready on http://localhost:58445
-```
-
-その後、Postman などのツールを使用してローカルインターフェースをデバッグできます。
-
-## Bearer Auth について
-
-```typescript
-import { bearerAuth } from "hono/bearer-auth";
-
-(c, next) => {
- const auth = bearerAuth({ token: c.env.TOKEN });
- return auth(c, next);
-},
-```
-
-Bearer 検証ロジックは上記のコードにあります。`hono/bearer-auth` パッケージを使用して Bearer 検証を実装しています。`src/index.ts` で `c.env.TOKEN` を使用して Token を取得できます。
-
-## パラメータ検証について
-
-```typescript
-import { z } from "zod";
-import { zValidator } from "@hono/zod-validator";
-
-const schema = z.object({
- point: z.union([
- z.literal("ping"),
- z.literal("app.external_data_tool.query"),
- ]), // Restricts 'point' to two specific values
- params: z
- .object({
- app_id: z.string().optional(),
- tool_variable: z.string().optional(),
- inputs: z.record(z.any()).optional(),
- query: z.any().optional(), // string or null
- })
- .optional(),
-});
-
-```
-
-ここでは `zod` を使用してパラメータの型を定義しています。`src/index.ts` で `zValidator` を使用してパラメータを検証できます。`const { point, params } = c.req.valid("json");` で検証済みパラメータを取得します。
-
-ここでの `point` は 2 つの値しかないため、`z.union` を使用して定義しています。`params` はオプションのパラメータなので、`z.optional` を使用して定義しています。その中には `inputs` パラメータがあり、これは `Record
-配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、LLMはそれを参照してユーザーを残りのタスクを通じてガイドします。
+配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、大規模言語モデルはそれを参照してユーザーを残りのタスクを通じてガイドします。
+
+## ベストプラクティス
+
+**適切なデータタイプを選択** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用する。
+
+**説明的な変数名を使用** - 会話変数の目的と内容を示すように明確に命名する。
+
+**データの成長を処理** - 長い会話での過度なメモリ使用を防ぐため、配列とオブジェクトのサイズを監視する。
+
+**変数を初期化** - 未定義の動作を防ぐため、会話変数に初期値を設定する。
+
+**適切な場合にクリア** - 新しいプロセスやセッションを開始する際に変数をリセットするためにクリア操作を使用する。
diff --git a/ja/use-dify/workspace/api-extension/api-extension.mdx b/ja/use-dify/workspace/api-extension/api-extension.mdx
deleted file mode 100644
index d1aba75ce..000000000
--- a/ja/use-dify/workspace/api-extension/api-extension.mdx
+++ /dev/null
@@ -1,262 +0,0 @@
----
-title: API 拡張
-sidebarTitle: 概要
----
-
-開発者は API 拡張モジュール機能を使用してモジュール機能を拡張できます。現在、以下のモジュール拡張がサポートされています:
-
-* `moderation` センシティブコンテンツ審査
-* `external_data_tool` 外部データツール
-
-モジュール機能を拡張する前に、API と認証用の API Key を準備する必要があります。
-
-対応するモジュール機能を開発する必要があるだけでなく、Dify が API を正しく呼び出せるように、以下の仕様に従う必要があります。
-
-## API 仕様
-
-Dify は以下の仕様でインターフェースを呼び出します:
-
-```
-POST {Your-API-Endpoint}
-```
-
-### Header
-
-| Header | Value | Desc |
-| --------------- | ----------------- | --------------------------------------------------------------------- |
-| `Content-Type` | application/json | リクエストコンテンツは JSON 形式です。 |
-| `Authorization` | Bearer {api_key} | API Key はトークン形式で送信されます。この `api_key` を解析し、提供された API Key と一致することを確認して、インターフェースのセキュリティを確保する必要があります。 |
-
-### Request Body
-
-```
-{
- "point": string, // 拡張ポイント、異なるモジュールには複数の拡張ポイントが含まれる場合があります
- "params": {
- ... // 各モジュール拡張ポイントに渡されるパラメータ
- }
-}
-```
-
-### API レスポンス
-
-```
-{
- ... // API が返すコンテンツ、異なる拡張ポイントのレスポンスについては各モジュールの仕様設計を参照してください
-}
-```
-
-## 検証
-
-Dify で API-based Extension を設定する際、Dify は API の可用性を確認するために API Endpoint にリクエストを送信します。
-
-API Endpoint が `point=ping` を受信したとき、インターフェースは `result=pong` を返す必要があります。具体的には以下の通りです:
-
-### Header
-
-```
-Content-Type: application/json
-Authorization: Bearer {api_key}
-```
-
-### Request Body
-
-```
-{
- "point": "ping"
-}
-```
-
-### API 期待レスポンス
-
-```
-{
- "result": "pong"
-}
-```
-
-## サンプル
-
-ここでは外部データツールを例として、地域に基づいて外部の天気情報をコンテキストとして取得するシナリオを示します。
-
-### API サンプル
-
-```
-POST https://fake-domain.com/api/dify/receive
-```
-
-**Header**
-
-```
-Content-Type: application/json
-Authorization: Bearer 123456
-```
-
-**Request Body**
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-**API レスポンス**
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-### コードサンプル
-
-コードは Python FastAPI フレームワークに基づいています。
-
-1. 依存関係をインストール
-
- ```
- pip install fastapi[all] uvicorn
- ```
-2. インターフェース仕様に従ってコードを記述
-
- ```
- from fastapi import FastAPI, Body, HTTPException, Header
- from pydantic import BaseModel
-
- app = FastAPI()
-
-
- class InputData(BaseModel):
- point: str
- params: dict = {}
-
-
- @app.post("/api/dify/receive")
- async def dify_receive(data: InputData = Body(...), authorization: str = Header(None)):
- """
- Receive API query data from Dify.
- """
- expected_api_key = "123456" # TODO Your API key of this API
- auth_scheme, _, api_key = authorization.partition(' ')
-
- if auth_scheme.lower() != "bearer" or api_key != expected_api_key:
- raise HTTPException(status_code=401, detail="Unauthorized")
-
- point = data.point
-
- # for debug
- print(f"point: {point}")
-
- if point == "ping":
- return {
- "result": "pong"
- }
- if point == "app.external_data_tool.query":
- return handle_app_external_data_tool_query(params=data.params)
- # elif point == "{point name}":
- # TODO other point implementation here
-
- raise HTTPException(status_code=400, detail="Not implemented")
-
-
- def handle_app_external_data_tool_query(params: dict):
- app_id = params.get("app_id")
- tool_variable = params.get("tool_variable")
- inputs = params.get("inputs")
- query = params.get("query")
-
- # for debug
- print(f"app_id: {app_id}")
- print(f"tool_variable: {tool_variable}")
- print(f"inputs: {inputs}")
- print(f"query: {query}")
-
- # TODO your external data tool query implementation here,
- # return must be a dict with key "result", and the value is the query result
- if inputs.get("location") == "London":
- return {
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind "
- "Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
- }
- else:
- return {"result": "Unknown city"}
- ```
-3. API サービスを起動します。デフォルトポートは 8000 で、完全な API アドレスは `http://127.0.0.1:8000/api/dify/receive`、設定された API Key は `123456` です。
-
- ```
- uvicorn main:app --reload --host 0.0.0.0
- ```
-4. Dify でこの API を設定します。
-
-5. App でこの API 拡張を選択します。
-
-App のデバッグ時、Dify は設定された API にリクエストを送信し、以下の内容を送信します(サンプル):
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-API レスポンスは:
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-## ローカルデバッグ
-
-Dify クラウド版では内部ネットワークの API サービスにアクセスできないため、ローカルで API サービスをデバッグするために、[Ngrok](https://ngrok.com) を使用して API サービスのエンドポイントを公開ネットワークに公開し、クラウドでローカルコードをデバッグできるようにします。操作手順:
-
-1. [https://ngrok.com](https://ngrok.com) の公式サイトにアクセスし、登録して Ngrok ファイルをダウンロードします。
-
- 
-
-2. ダウンロード完了後、ダウンロードディレクトリに移動し、以下の説明に従って圧縮ファイルを解凍し、説明の初期化スクリプトを実行します。
- ```Shell
- unzip /path/to/ngrok.zip
- ./ngrok config add-authtoken あなたのToken
- ```
-3. ローカル API サービスのポートを確認します:
-
- 
-
- そして、以下のコマンドを実行して起動します:
-
- ```Shell
- ./ngrok http ポート番号
- ```
-
- 起動成功のサンプルは以下の通りです:
-
- 
-
-4. Forwarding の中から、上図のように `https://177e-159-223-41-52.ngrok-free.app`(これはサンプルドメインです、自分のものに置き換えてください)が公開ネットワークドメインです。
-
-上記のサンプルに従って、ローカルで既に起動されているサービスエンドポイントを公開し、コードサンプルのインターフェース `http://127.0.0.1:8000/api/dify/receive` を `https://177e-159-223-41-52.ngrok-free.app/api/dify/receive` に置き換えます。
-
-この API エンドポイントは公開ネットワークでアクセス可能になります。これで、Dify でこの API エンドポイントを設定してローカルコードをデバッグできます。設定手順については、[外部データツール](/ja/use-dify/workspace/api-extension/external-data-tool-api-extension) を参照してください。
-
-## Cloudflare Workers を使用した API 拡張のデプロイ
-
-API 拡張をデプロイするには Cloudflare Workers の使用をお勧めします。Cloudflare Workers は簡単に公開ネットワークアドレスを提供でき、無料で使用できます。
-
-詳細な説明については、[Cloudflare Workers を使用した API 拡張のデプロイ](/ja/use-dify/workspace/api-extension/cloudflare-worker) を参照してください。
diff --git a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx b/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
deleted file mode 100644
index decc1237f..000000000
--- a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
+++ /dev/null
@@ -1,131 +0,0 @@
----
-title: Cloudflare Workers を使用した API 拡張のデプロイ
----
-
-## はじめに
-
-Dify API 拡張は API Endpoint としてアクセス可能な公開ネットワークアドレスを使用する必要があるため、API 拡張を公開ネットワークアドレスにデプロイする必要があります。
-
-ここでは Cloudflare Workers を使用して API 拡張をデプロイします。
-
-[Example GitHub Repository](https://github.com/crazywoola/dify-extension-workers) をクローンします。このリポジトリには簡単な API 拡張が含まれており、これをベースに変更できます。
-
-```bash
-git clone https://github.com/crazywoola/dify-extension-workers.git
-cp wrangler.toml.example wrangler.toml
-```
-
-`wrangler.toml` ファイルを開き、`name` と `compatibility_date` をアプリケーション名と互換性日付に変更します。
-
-ここで注意が必要な設定は、`vars` 内の `TOKEN` です。Dify で API 拡張を追加する際に、この Token を入力する必要があります。セキュリティ上の理由から、Token としてランダムな文字列を使用することをお勧めします。ソースコードに直接 Token を書き込むのではなく、環境変数を使用して Token を渡すべきです。そのため、wrangler.toml をコードリポジトリにコミットしないでください。
-
-```toml
-name = "dify-extension-example"
-compatibility_date = "2023-01-01"
-
-[vars]
-TOKEN = "bananaiscool"
-```
-
-この API 拡張はランダムな Breaking Bad の名言を返します。`src/index.ts` でこの API 拡張のロジックを変更できます。この例は、サードパーティ API とのやり取り方法を示しています。
-
-```typescript
-// ⬇️ implement your logic here ⬇️
-// point === "app.external_data_tool.query"
-// https://api.breakingbadquotes.xyz/v1/quotes
-const count = params?.inputs?.count ?? 1;
-const url = `https://api.breakingbadquotes.xyz/v1/quotes/${count}`;
-const result = await fetch(url).then(res => res.text())
-// ⬆️ implement your logic here ⬆️
-```
-
-このリポジトリはビジネスロジック以外のすべての設定を簡略化しています。`npm` コマンドを直接使用して API 拡張をデプロイできます。
-
-```bash
-npm install
-npm run deploy
-```
-
-デプロイが成功すると、公開ネットワークアドレスが取得できます。このアドレスを Dify の API Endpoint として追加できます。`endpoint` パスを忘れないでください。このパスの具体的な定義は `src/index.ts` で確認できます。
-
-
-
-また、`npm run dev` コマンドを使用してローカルにデプロイしてテストすることもできます。
-
-```bash
-npm install
-npm run dev
-```
-
-関連する出力:
-
-```bash
-$ npm run dev
-> dev
-> wrangler dev src/index.ts
-
- ⛅️ wrangler 3.99.0
--------------------
-
-Your worker has access to the following bindings:
-- Vars:
- - TOKEN: "ban****ool"
-⎔ Starting local server...
-[wrangler:inf] Ready on http://localhost:58445
-```
-
-その後、Postman などのツールを使用してローカルインターフェースをデバッグできます。
-
-## Bearer Auth について
-
-```typescript
-import { bearerAuth } from "hono/bearer-auth";
-
-(c, next) => {
- const auth = bearerAuth({ token: c.env.TOKEN });
- return auth(c, next);
-},
-```
-
-Bearer 検証ロジックは上記のコードにあります。`hono/bearer-auth` パッケージを使用して Bearer 検証を実装しています。`src/index.ts` で `c.env.TOKEN` を使用して Token を取得できます。
-
-## パラメータ検証について
-
-```typescript
-import { z } from "zod";
-import { zValidator } from "@hono/zod-validator";
-
-const schema = z.object({
- point: z.union([
- z.literal("ping"),
- z.literal("app.external_data_tool.query"),
- ]), // Restricts 'point' to two specific values
- params: z
- .object({
- app_id: z.string().optional(),
- tool_variable: z.string().optional(),
- inputs: z.record(z.any()).optional(),
- query: z.any().optional(), // string or null
- })
- .optional(),
-});
-
-```
-
-ここでは `zod` を使用してパラメータの型を定義しています。`src/index.ts` で `zValidator` を使用してパラメータを検証できます。`const { point, params } = c.req.valid("json");` で検証済みパラメータを取得します。
-
-ここでの `point` は 2 つの値しかないため、`z.union` を使用して定義しています。`params` はオプションのパラメータなので、`z.optional` を使用して定義しています。その中には `inputs` パラメータがあり、これは `Record` 型です。この型は、キーが string で値が any のオブジェクトを表します。この型は任意のオブジェクトを表すことができます。`src/index.ts` で `params?.inputs?.count` を使用して `count` パラメータを取得できます。
-
-## Cloudflare Workers のログを取得
-
-```bash
-wrangler tail
-```
-
----
-
-**参考資料**
-
-* [Cloudflare Workers](https://workers.cloudflare.com/)
-* [Cloudflare Workers CLI](https://developers.cloudflare.com/workers/cli-wrangler/install-update)
-* [Example GitHub Repository](https://github.com/crazywoola/dify-extension-workers)
diff --git a/ja/use-dify/workspace/api-extension/external-data-tool-api-extension.mdx b/ja/use-dify/workspace/api-extension/external-data-tool-api-extension.mdx
deleted file mode 100644
index c9ab60812..000000000
--- a/ja/use-dify/workspace/api-extension/external-data-tool-api-extension.mdx
+++ /dev/null
@@ -1,63 +0,0 @@
----
-title: 外部データツール
----
-
-AI アプリケーションを作成する際、開発者は [API 拡張](/ja/use-dify/workspace/api-extension/api-extension) を通じて外部ツールを使用して追加データを取得し、それを Prompt に組み込んで LLM の追加情報として使用できます。
-
-## 拡張ポイント
-
-`app.external_data_tool.query`:アプリケーション外部データツールクエリ拡張ポイント。
-
-この拡張ポイントは、エンドユーザーが入力したアプリケーション変数の内容と会話入力内容(会話型アプリケーションの固定パラメータ)をパラメータとして API に渡します。
-
-開発者は対応するツールのクエリロジックを実装し、文字列型のクエリ結果を返す必要があります。
-
-### Request Body
-
-```
-{
- "point": "app.external_data_tool.query", // 拡張ポイントタイプ、ここでは app.external_data_tool.query に固定
- "params": {
- "app_id": string, // アプリケーション ID
- "tool_variable": string, // 外部データツール変数名、対応する変数ツール呼び出しのソースを示す
- "inputs": { // エンドユーザーが渡した変数値、key は変数名、value は変数値
- "var_1": "value_1",
- "var_2": "value_2",
- ...
- },
- "query": string | null // エンドユーザーの現在の会話入力内容、会話型アプリケーションの固定パラメータ。
- }
-}
-```
-
-**例**:
-
- ```
- {
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
- }
- ```
-
-### API レスポンス
-
-```
-{
- "result": string
-}
-```
-
-**例**:
-
- ```
- {
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
- }
- ```
diff --git a/ja/use-dify/workspace/api-extension/moderation-api-extension.mdx b/ja/use-dify/workspace/api-extension/moderation-api-extension.mdx
deleted file mode 100644
index 9cbb09549..000000000
--- a/ja/use-dify/workspace/api-extension/moderation-api-extension.mdx
+++ /dev/null
@@ -1,254 +0,0 @@
----
-title: センシティブコンテンツ審査
----
-
-このモジュールは、アプリケーション内でエンドユーザーが入力したコンテンツと LLM が出力したコンテンツを審査するために使用され、2 つの拡張ポイントタイプに分かれています。
-
-## 拡張ポイント
-
-* `app.moderation.input`:エンドユーザー入力コンテンツ審査拡張ポイント
- * エンドユーザーが渡した変数内容と会話型アプリケーションの会話入力内容を審査するために使用されます。
-* `app.moderation.output`:LLM 出力コンテンツ審査拡張ポイント
- * LLM が出力したコンテンツを審査するために使用されます。
- * LLM の出力がストリーミングの場合、出力内容は 100 文字を 1 セグメントとして API にリクエストされ、出力内容が長い場合の審査の遅延を可能な限り回避します。
-
-### app.moderation.input
-
-Chatflow、Agent、チャットアシスタントなどのアプリケーションで**コンテンツ審査 > 入力コンテンツを審査**が有効になっている場合、Dify は対応する API 拡張に以下の HTTP POST リクエストを送信します:
-
-#### Request Body
-
-```
-{
- "point": "app.moderation.input", // 拡張ポイントタイプ、ここでは app.moderation.input に固定
- "params": {
- "app_id": string, // アプリケーション ID
- "inputs": { // エンドユーザーが渡した変数値、key は変数名、value は変数値
- "var_1": "value_1",
- "var_2": "value_2",
- ...
- },
- "query": string | null // エンドユーザーの現在の会話入力内容、会話型アプリケーションの固定パラメータ。
- }
-}
-```
-
-**例**:
-
- ```
- {
- "point": "app.moderation.input",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "inputs": {
- "var_1": "I will kill you.",
- "var_2": "I will fuck you."
- },
- "query": "Happy everydays."
- }
- }
- ```
-
-#### API レスポンス仕様
-
-```
-{
- "flagged": bool, // 検証ルールに違反しているかどうか
- "action": string, // アクション、direct_output は事前設定された回答を直接出力; overridden は入力変数値を上書き
- "preset_response": string, // 事前設定された回答(action=direct_output の場合にのみ返される)
- "inputs": { // エンドユーザーが渡した変数値、key は変数名、value は変数値(action=overridden の場合にのみ返される)
- "var_1": "value_1",
- "var_2": "value_2",
- ...
- },
- "query": string | null // 上書きされたエンドユーザーの現在の会話入力内容、会話型アプリケーションの固定パラメータ。(action=overridden の場合にのみ返される)
-}
-```
-
-**例**:
-
- * `action=direct_output`
- ```
- {
- "flagged": true,
- "action": "direct_output",
- "preset_response": "Your content violates our usage policy."
- }
- ```
- * `action=overridden`
- ```
- {
- "flagged": true,
- "action": "overridden",
- "inputs": {
- "var_1": "I will *** you.",
- "var_2": "I will *** you."
- },
- "query": "Happy everydays."
- }
- ```
-
-### app.moderation.output
-
-Chatflow、Agent、チャットアシスタントなどのアプリケーションで**コンテンツ審査 > 出力コンテンツを審査**が有効になっている場合、Dify は対応する API 拡張に以下の HTTP POST リクエストを送信します:
-
-#### Request Body
-
-```
-{
- "point": "app.moderation.output", // 拡張ポイントタイプ、ここでは app.moderation.output に固定
- "params": {
- "app_id": string, // アプリケーション ID
- "text": string // LLM 応答内容。LLM の出力がストリーミングの場合、ここでは 100 文字を 1 セグメントとした内容。
- }
-}
-```
-
-**例**:
- ```
- {
- "point": "app.moderation.output",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "text": "I will kill you."
- }
- }
- ```
-
-#### API レスポンス
-
-```
-{
- "flagged": bool, // 検証ルールに違反しているかどうか
- "action": string, // アクション、direct_output は事前設定された回答を直接出力; overridden は入力変数値を上書き
- "preset_response": string, // 事前設定された回答(action=direct_output の場合にのみ返される)
- "text": string // 上書きされた LLM 応答内容。(action=overridden の場合にのみ返される)
-}
-```
-
-**例**:
-
- * `action=direct_output`
- ```
- {
- "flagged": true,
- "action": "direct_output",
- "preset_response": "Your content violates our usage policy."
- }
- ```
- * `action=overridden`
- ```
- {
- "flagged": true,
- "action": "overridden",
- "text": "I will *** you."
- }
- ```
-
-## コードサンプル
-以下は、Cloudflare にデプロイ可能な `src/index.ts` コードの一部です。(Cloudflare の完全な使用方法については [このドキュメント](/ja/use-dify/workspace/api-extension/cloudflare-worker) を参照してください)
-
-コードの動作原理はキーワードマッチングを行い、Input(ユーザーが入力したコンテンツ)および Output(大規模モデルが返したコンテンツ)をフィルタリングすることです。ユーザーは必要に応じてマッチングロジックを変更できます。
-```
-import { Hono } from "hono";
-import { bearerAuth } from "hono/bearer-auth";
-import { z } from "zod";
-import { zValidator } from "@hono/zod-validator";
-import { generateSchema } from '@anatine/zod-openapi';
-
-type Bindings = {
- TOKEN: string;
-};
-
-const app = new Hono<{ Bindings: Bindings }>();
-
-// API フォーマット検証 ⬇️
-const schema = z.object({
- point: z.union([
- z.literal("ping"),
- z.literal("app.external_data_tool.query"),
- z.literal("app.moderation.input"),
- z.literal("app.moderation.output"),
- ]), // Restricts 'point' to two specific values
- params: z
- .object({
- app_id: z.string().optional(),
- tool_variable: z.string().optional(),
- inputs: z.record(z.any()).optional(),
- query: z.any(),
- text: z.any()
- })
- .optional(),
-});
-
-
-// Generate OpenAPI schema
-app.get("/", (c) => {
- return c.json(generateSchema(schema));
-});
-
-app.post(
- "/",
- (c, next) => {
- const auth = bearerAuth({ token: c.env.TOKEN });
- return auth(c, next);
- },
- zValidator("json", schema),
- async (c) => {
- const { point, params } = c.req.valid("json");
- if (point === "ping") {
- return c.json({
- result: "pong",
- });
- }
- // ⬇️ impliment your logic here ⬇️
- // point === "app.external_data_tool.query"
- else if (point === "app.moderation.input"){
- // 入力チェック ⬇️
- const inputkeywords = ["入力フィルターテスト1", "入力フィルターテスト2", "入力フィルターテスト3"];
-
- if (inputkeywords.some(keyword => params.query.includes(keyword)))
- {
- return c.json({
- "flagged": true,
- "action": "direct_output",
- "preset_response": "入力に違法コンテンツが含まれています。別の質問で試してください!"
- });
- } else {
- return c.json({
- "flagged": false,
- "action": "direct_output",
- "preset_response": "入力は正常です"
- });
- }
- // 入力チェック完了
- }
-
- else {
- // 出力チェック ⬇️
- const outputkeywords = ["出力フィルターテスト1", "出力フィルターテスト2", "出力フィルターテスト3"];
-
- if (outputkeywords.some(keyword => params.text.includes(keyword)))
- {
- return c.json({
- "flagged": true,
- "action": "direct_output",
- "preset_response": "出力にセンシティブコンテンツが含まれており、システムによってフィルタリングされました。別の質問で試してください!"
- });
- }
-
- else {
- return c.json({
- "flagged": false,
- "action": "direct_output",
- "preset_response": "出力は正常です"
- });
- };
- }
- // 出力チェック完了
- }
-);
-
-export default app;
-
-```
diff --git a/ja/use-dify/workspace/model-providers.mdx b/ja/use-dify/workspace/model-providers.mdx
index 4b45461c5..a23b047a6 100644
--- a/ja/use-dify/workspace/model-providers.mdx
+++ b/ja/use-dify/workspace/model-providers.mdx
@@ -1,11 +1,12 @@
---
title: "モデルプロバイダー"
-description: "ワークスペースのAIモデルアクセスを設定—すべてのアプリケーションを支える基盤"
+description: "Configure AI model access for your workspace—the foundation that powers all your applications"
icon: "brain-arrow-curved-right"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/workspace/model-providers)を参照してください。
+
モデルプロバイダーは、ワークスペースにAIモデルへのアクセスを提供します。構築するすべてのアプリケーションには動作するためのモデルが必要であり、ワークスペースレベルでプロバイダーを設定することで、すべてのチームメンバーがすべてのプロジェクトでモデルを使用できます。
## システムプロバイダー vs カスタムプロバイダー
@@ -45,9 +46,9 @@ icon: "brain-arrow-curved-right"
- Anthropic (Claude)
- Google (Gemini)
- Cohere
-- Ollama経由のローカルモデル
+- Ollama経由のローカルモデル推論
-**埋め込みモデル:**
+**テキスト埋め込みモデル:**
- OpenAI Embeddings
- Cohere Embeddings
- Azure OpenAI
@@ -66,7 +67,7 @@ icon: "brain-arrow-curved-right"
**オプション:** Azure OpenAIまたはプロキシ用のカスタムベースURL、組織スコープ使用のための組織ID
- **利用可能なモデル:** GPT-4, GPT-3.5-turbo, DALL-E, Whisper, テキスト埋め込み
+ **利用可能なモデル:** GPT-4, GPT, テキスト埋め込み
@@ -84,6 +85,7 @@ icon: "brain-arrow-curved-right"
+
## モデルの認証情報を管理
モデルプロバイダーの定義済みモデルやカスタムモデルに対して、複数の認証情報を追加し、それらの認証情報の切り替え、削除、変更を簡単に行うことができます。
@@ -158,10 +160,10 @@ icon: "brain-arrow-curved-right"
-## モデルのロードバランシングを設定
+## 負荷分散の構成
-ロードバランシングは有料機能です。[SaaS有料プランのサブスクリプションまたはエンタープライズ版の購入](https://dify.ai/pricing)によって有効化できます。
+ロードバランシングは有料機能です。[SaaS有料プランのサブスクリプションまたはエンタープライズ版の購入](https://dify.ai/jp/pricing)によって有効化できます。
モデルプロバイダーは通常、安定性と公平な利用を確保するため、特定の時間枠内でのAPIアクセスにレート制限を設けています。エンタープライズアプリケーションでは、単一の認証情報に対して大量の同時リクエストが発生すると、この制限に容易に達してしまい、ユーザーアクセスが中断される可能性があります。
@@ -176,19 +178,19 @@ Difyはロードバランシングにラウンドロビン方式を採用して
2. ロードバランシングプールで **認証情報を追加する** をクリックし、既存の認証情報を選択するか、新しい認証情報を追加します。
-
- **デフォルトの設定** は、そのモデルに現在指定されているデフォルトの認証情報を指します。
-
+
+**デフォルトの設定** は、そのモデルに現在指定されているデフォルトの認証情報を指します。
+
-
- 特定の認証情報がより高いクォータを持つ、またはより優れたパフォーマンスを示す場合は、その認証情報を複数回追加することでロードバランシングにおける重みを増し、より多くのリクエストを処理させることができます。
-
+
+特定の認証情報がより高いクォータを持つ、またはより優れたパフォーマンスを示す場合は、その認証情報を複数回追加することでロードバランシングにおける重みを増し、より多くのリクエストを処理させることができます。
+
-  +
3. 負荷分散プールで少なくとも2つの認証情報を有効にし、**保存** をクリックします。負荷分散が有効になったモデルには、特別なアイコンが表示されます。
- 
+
+
3. 負荷分散プールで少なくとも2つの認証情報を有効にし、**保存** をクリックします。負荷分散が有効になったモデルには、特別なアイコンが表示されます。
- 
+
ロード バランシング モードからデフォルトの単一認証情報モードに戻しても、ロード バランシングの設定は将来の使用のために保持されます。
diff --git a/zh/api-reference/openapi_knowledge.json b/zh/api-reference/openapi_knowledge.json
index 0efeb4cfd..e9fa919a0 100644
--- a/zh/api-reference/openapi_knowledge.json
+++ b/zh/api-reference/openapi_knowledge.json
@@ -1770,15 +1770,6 @@
"description": "是否启用重新排序模型以改善搜索结果。"
},
"reranking_mode": {
- "type": "string",
- "description": "重新排序模式。",
- "default": "reranking_model",
- "enum": [
- "reranking_model",
- "weighted_score"
- ]
- },
- "reranking_model": {
"type": "object",
"description": "重新排序模型的配置。",
"properties": {
@@ -2330,18 +2321,9 @@
},
"partial_member_list": {
"type": "array",
- "description": "'partial_members' 权限可访问的成员列表。",
+ "description": "'partial_members' 权限的成员 ID 列表。",
"items": {
- "type": "object",
- "required": [
- "user_id"
- ],
- "properties": {
- "user_id": {
- "type": "string",
- "description": "成员的用户 ID。"
- }
- }
+ "type": "string"
}
}
}
@@ -2954,4 +2936,4 @@
}
}
}
-}
+}
\ No newline at end of file
diff --git a/zh/self-host/troubleshooting/storage-and-migration.mdx b/zh/self-host/troubleshooting/storage-and-migration.mdx
index 9505a7548..68c40619c 100644
--- a/zh/self-host/troubleshooting/storage-and-migration.mdx
+++ b/zh/self-host/troubleshooting/storage-and-migration.mdx
@@ -93,8 +93,7 @@ title: 存储与迁移
```
2. **从存储中删除孤立文件**
- ```bash
- docker exec -it docker-api-1 flask remove-orphaned-files-on-storage
+ ```bashd-files-on-storage
# 使用 -f 标志跳过确认
```
diff --git a/zh/self-host/troubleshooting/weaviate-v4-migration.mdx b/zh/self-host/troubleshooting/weaviate-v4-migration.mdx
index af991f75d..c88d7c22f 100644
--- a/zh/self-host/troubleshooting/weaviate-v4-migration.mdx
+++ b/zh/self-host/troubleshooting/weaviate-v4-migration.mdx
@@ -11,19 +11,17 @@ title: Weaviate 迁移指南:升级到客户端 v4 和服务器 1.27+
从 **Dify v1.9.2** 开始,weaviate-client 已从 v3 升级到 v4.17.0。此升级带来了显著的性能改进和更好的稳定性,但需要 **Weaviate 服务器版本 1.27.0 或更高版本**。
- **破坏性变更**:新的 weaviate-client v4 与 1.27.0 以下的 Weaviate 服务器版本不向后兼容。如果你正在运行 1.19.0 或更旧版本的自托管 Weaviate 实例,则必须在升级 Dify 之前升级 Weaviate 服务器。
+**破坏性变更**:新的 weaviate-client v4 与 1.27.0 以下的 Weaviate 服务器版本不向后兼容。如果你正在运行 1.19.0 或更旧版本的自托管 Weaviate 实例,则必须在升级 Dify 之前升级 Weaviate 服务器。
### 谁会受到影响?
此迁移影响:
-
- 运行低于 1.27.0 版本的自托管 Weaviate 实例的自托管 Dify 用户
- 当前使用 Weaviate 服务器版本 1.19.0-1.26.x 的用户
- 升级到包含 weaviate-client v4 的 Dify 版本的用户
**不受影响**:
-
- 云托管 Weaviate 用户(Weaviate Cloud 管理服务器版本)
- 已经使用 Weaviate 1.27.0+ 的用户可以直接升级 Dify,无需额外步骤
- 运行 Dify 默认 Docker Compose 设置的用户(Weaviate 版本会自动更新)
@@ -49,16 +47,16 @@ weaviate-client v4 引入了几个破坏性变更:
## 版本兼容性矩阵
| Dify 版本 | Weaviate-client 版本 | 兼容的 Weaviate 服务器版本 |
-| ------------ | ----------------------- | ----------------------------------- |
+|-------------|---------------------|--------------------------------|
| ≤ 1.9.1 | v3.x | 1.19.0 - 1.26.x |
| ≥ 1.9.2 | v4.17.0 | 1.27.0+(已测试至 1.33.1) |
- 此迁移适用于任何使用 weaviate-client v4.17.0 或更高版本的 Dify 版本。
+ 此迁移适用于任何使用 weaviate-client v4.17.0 或更高版本的 Dify 版本。
- Weaviate 服务器版本 1.19.0 在一年多前发布,现已过时。升级到 1.27.0+ 可访问性能、稳定性和功能方面的众多改进。
+Weaviate 服务器版本 1.19.0 在一年多前发布,现已过时。升级到 1.27.0+ 可访问性能、稳定性和功能方面的众多改进。
## 前提条件
@@ -66,21 +64,17 @@ weaviate-client v4 引入了几个破坏性变更:
在开始迁移之前,请完成以下步骤:
1. **检查当前的 Weaviate 版本**
-
```bash
curl http://localhost:8080/v1/meta
```
-
在响应中查找 `version` 字段。
2. **备份数据**
-
- 创建 Weaviate 数据的完整备份
- 如果使用 Docker Compose,请备份 Docker 卷
- 记录当前的配置设置
3. **检查系统要求**
-
- 确保有足够的磁盘空间用于数据库迁移
- 验证 Dify 和 Weaviate 之间的网络连接
- 如果使用外部 Weaviate,确认 gRPC 端口 (50051) 可访问
@@ -100,13 +94,13 @@ weaviate-client v4 引入了几个破坏性变更:
- **路径 B – 直接恢复(已在 1.27+)**:如果你已经升级到 1.27+ 且知识库停止工作,请使用此路径。此路径专注于修复数据布局并运行 schema 迁移。
- **不要**尝试降级回 1.19。schema 格式不兼容,会导致数据丢失。
+**不要**尝试降级回 1.19。schema 格式不兼容,会导致数据丢失。
### 路径 A:带备份的迁移(从 1.19)
- 最安全的路径。在升级前创建备份,如果出现问题可以恢复。
+最安全的路径。在升级前创建备份,如果出现问题可以恢复。
#### 前提条件
@@ -120,18 +114,18 @@ weaviate-client v4 引入了几个破坏性变更:
编辑 `docker/docker-compose.yaml`,使 `weaviate` 服务包含备份配置:
```yaml
-weaviate:
- image: semitechnologies/weaviate:1.19.0
- volumes:
- - ./volumes/weaviate:/var/lib/weaviate
- - ./volumes/weaviate_backups:/var/lib/weaviate/backups
- ports:
- - "8080:8080"
- - "50051:50051"
- environment:
- ENABLE_MODULES: backup-filesystem
- BACKUP_FILESYSTEM_PATH: /var/lib/weaviate/backups
- # ... 其余环境变量
+ weaviate:
+ image: semitechnologies/weaviate:1.19.0
+ volumes:
+ - ./volumes/weaviate:/var/lib/weaviate
+ - ./volumes/weaviate_backups:/var/lib/weaviate/backups
+ ports:
+ - "8080:8080"
+ - "50051:50051"
+ environment:
+ ENABLE_MODULES: backup-filesystem
+ BACKUP_FILESYSTEM_PATH: /var/lib/weaviate/backups
+ # ... 其余环境变量
```
重启 Weaviate 以应用更改:
@@ -214,10 +208,6 @@ sleep 10
#### 步骤 A4:修复孤立的 LSM 数据(如果存在)
-你可以从主机或在容器内部修复孤立的 LSM 数据:
-
-**选项 A:从主机(如果卷已挂载)**:
-
```bash
cd docker/volumes/weaviate
@@ -238,32 +228,6 @@ docker compose restart weaviate
sleep 15
```
-**选项 B:在 Weaviate 容器内部(推荐)**:
-
-```bash
-cd /path/to/dify/docker
-docker compose exec -it weaviate /bin/sh
-
-# 在容器内部
-cd /var/lib/weaviate
-for dir in vector_index_*_node_*_lsm; do
- [ -d "$dir" ] || continue
-
- index_id=$(echo "$dir" | sed -n 's/vector_index_\([^_]*_[^_]*_[^_]*_[^_]*_[^_]*\)_node_.*/\1/p')
- shard_id=$(echo "$dir" | sed -n 's/.*_node_\([^_]*\)_lsm/\1/p')
-
- mkdir -p "vector_index_${index_id}_node/$shard_id/lsm"
- cp -a "$dir/"* "vector_index_${index_id}_node/$shard_id/lsm/"
-
- echo "✓ Copied $dir"
-done
-exit
-
-# 重启 Weaviate
-docker compose restart weaviate
-sleep 15
-```
-
#### 步骤 A5:迁移 Schema
1. **安装依赖**(在临时 virtualenv 中即可):
@@ -275,34 +239,12 @@ sleep 15
pip install weaviate-client requests
```
-2. **运行[迁移脚本](https://github.com/langgenius/dify-docs/blob/main/assets/migrate_weaviate_collections.py)**,可以在本地运行或在 Worker 容器内运行。\
- **选项 A:在本地运行(如果你已安装 Python 3.11+ 和依赖项)**:
+2. **运行[迁移脚本](https://github.com/langgenius/dify-docs/blob/main/assets/migrate_weaviate_collections.py)**:
```bash
python3 migrate_weaviate_collections.py
```
- **选项 B:在 Worker 容器内运行(推荐用于 Docker 设置)**:
-
- ```bash
- # 将脚本复制到存储目录
- cp migrate_weaviate_collections.py /path/to/dify/docker/volumes/app/storage/
-
- # 进入 worker 容器
- cd /path/to/dify/docker
- docker compose exec -it worker /bin/bash
-
- # 运行迁移脚本(Dify 1.11.0+ 请使用 --no-cache)
- uv run --no-cache /app/api/storage/migrate_weaviate_collections.py
-
- # 退出容器
- exit
- ```
-
-
- 迁移脚本使用环境变量进行配置,适合在 Docker 容器内运行。对于 Dify 1.11.0+,如果遇到 `uv` 的权限错误,请使用 `uv run --no-cache`。
-
-
3. **重启 Dify 服务**:
```bash
@@ -313,18 +255,14 @@ sleep 15
4. **在 UI 中验证**:打开 Dify,针对迁移后的知识库测试检索功能。
-
- 对于大型集合(超过 10,000 个对象),请验证新旧集合之间的对象计数是否匹配。迁移脚本会自动显示验证计数。
-
-
- 确认迁移成功后,你可以删除 `weaviate_migration_env` 和备份文件以回收磁盘空间。
+确认迁移成功后,你可以删除 `weaviate_migration_env` 和备份文件以回收磁盘空间。
### 路径 B:直接恢复(已在 1.27+)
- 仅当你已经升级到 1.27+ 且知识库停止工作时才使用此路径。你已无法创建 1.19 备份,因此必须就地修复数据。
+仅当你已经升级到 1.27+ 且知识库停止工作时才使用此路径。你已无法创建 1.19 备份,因此必须就地修复数据。
#### 前提条件
@@ -335,13 +273,10 @@ sleep 15
#### 步骤 B1:修复孤立的 LSM 数据
-停止 Weaviate 并修复孤立的 LSM 数据:
-
```bash
-cd /path/to/dify/docker
+cd docker
docker compose stop weaviate
-# 选项 A:从主机(如果卷已挂载)
cd volumes/weaviate
for dir in vector_index_*_node_*_lsm; do
@@ -355,24 +290,12 @@ for dir in vector_index_*_node_*_lsm; do
echo "✓ Copied $dir"
done
-
-# 选项 B:在容器内部(推荐)
-docker compose run --rm --entrypoint /bin/sh weaviate -c "
-cd /var/lib/weaviate
-for dir in vector_index_*_node_*_lsm; do
- [ -d \"\$dir\" ] || continue
- index_id=\$(echo \"\$dir\" | sed -n 's/vector_index_\([^_]*_[^_]*_[^_]*_[^_]*_[^_]*\)_node_.*/\1/p')
- shard_id=\$(echo \"\$dir\" | sed -n 's/.*_node_\([^_]*\)_lsm/\1/p')
- mkdir -p \"vector_index_\${index_id}_node/\$shard_id/lsm\"
- cp -a \"\$dir/\"* \"vector_index_\${index_id}_node/\$shard_id/lsm/\"
- echo \"✓ Copied \$dir\"
-done
-"
```
重启 Weaviate:
```bash
+cd ../..
docker compose start weaviate
sleep 15
```
@@ -395,57 +318,33 @@ curl -s -H "Authorization: Bearer " \
#### 步骤 B2:运行 Schema 迁移
-按照步骤 A5 中的相同命令操作。你可以在本地或在 Worker 容器内运行脚本:
-
-**在 Worker 容器内运行**:
-
-```bash
-# 将脚本复制到存储目录
-cp migrate_weaviate_collections.py /path/to/dify/docker/volumes/app/storage/
-
-# 进入 worker 容器
-cd /path/to/dify/docker
-docker compose exec -it worker /bin/bash
-
-# 运行迁移脚本
-uv run --no-cache /app/api/storage/migrate_weaviate_collections.py
-
-# 退出并重启服务
-exit
-docker compose restart api worker worker_beat
-```
-
-
- 迁移脚本使用基于游标的分页来安全处理大型集合。迁移完成后请验证对象计数是否匹配。
-
+按照[步骤 A5](#步骤-a5:迁移-schema)中的相同命令操作。如果需要,创建 virtualenv,安装 `weaviate-client` 4.x,运行 `migrate_weaviate_collections.py`,然后重启 `api`、`worker` 和 `worker_beat`。
#### 步骤 B3:在 Dify 中验证
- 打开 Dify 的知识库 UI。
- 使用检索测试确认查询返回结果。
-- 如果错误持续存在,检查 `docker compose logs weaviate` 以获取额外的修复步骤(参见[故障排除](#troubleshooting))。
+- 如果错误持续存在,检查 `docker compose logs weaviate` 以获取额外的修复步骤(参见[故障排除](#故障排除))。
## 旧版本的数据迁移
-**重要:需要数据迁移**
+### 重要:需要数据迁移
**升级后如果不进行迁移,你现有的知识库将无法工作!**
-**为什么需要迁移**:
-
+### 为什么需要迁移:
- 旧数据:使用 Weaviate v3 客户端创建(简单 schema)
- 新代码:需要 Weaviate v4 格式(扩展 schema)
- **不兼容**:旧数据缺少必需的属性
-**迁移选项**:
+### 迁移选项:
-- 选项 A:使用 Weaviate 备份/恢复
+##### 选项 A:使用 Weaviate 备份/恢复
-- 选项 B:从原始文档重新索引
-
-- 选项 C:保留旧 Weaviate(暂不升级)如果你无法承受停机或数据丢失。
+##### 选项 B:从原始文档重新索引
+##### 选项 C:保留旧 Weaviate(暂不升级)如果你无法承受停机或数据丢失。
### 自动迁移
@@ -482,7 +381,7 @@ curl -X POST "http://localhost:8080/v1/backups/filesystem/pre-migration-backup/r
```
- 有关全面的迁移指导,特别是对于复杂架构或大型数据集,请参阅官方 [Weaviate 迁移指南](https://weaviate.io/developers/weaviate/installation/migration)。
+有关全面的迁移指导,特别是对于复杂架构或大型数据集,请参阅官方 [Weaviate 迁移指南](https://weaviate.io/developers/weaviate/installation/migration)。
## 配置变更
@@ -498,12 +397,10 @@ curl -X POST "http://localhost:8080/v1/backups/filesystem/pre-migration-backup/r
**格式**:`hostname:port`(无协议前缀)
**默认端口**:
-
- 不安全:50051
- 安全 (TLS):443
**示例**:
-
```bash
# Docker Compose(内部网络)
WEAVIATE_GRPC_ENDPOINT=weaviate:50051
@@ -519,7 +416,7 @@ WEAVIATE_GRPC_ENDPOINT=your-instance.weaviate.cloud:443
```
- 不要在 WEAVIATE_GRPC_ENDPOINT 值中包含协议前缀,如 `grpc://` 或 `http://`。仅使用 `hostname:port`。
+不要在 WEAVIATE_GRPC_ENDPOINT 值中包含协议前缀,如 `grpc://` 或 `http://`。仅使用 `hostname:port`。
### 更新的环境变量
@@ -551,6 +448,8 @@ WEAVIATE_GRPC_ENDPOINT=weaviate:50051
WEAVIATE_BATCH_SIZE=100
```
+
+
## 验证步骤
完成迁移后,验证一切是否正常工作:
@@ -586,7 +485,7 @@ docker compose logs api | grep -i weaviate
6. 检查状态是否从"QUEUING"→"INDEXING"→"AVAILABLE"
- 如果文档卡在"QUEUING"状态,请检查 Celery worker 是否正在运行:`docker compose logs worker`。
+如果文档卡在"QUEUING"状态,请检查 Celery worker 是否正在运行:`docker compose logs worker`
### 4. 测试向量搜索
@@ -609,7 +508,7 @@ docker compose logs -f api | grep -i "query_time\|duration"
```
- 正确配置 gRPC 后,与仅使用 HTTP 的连接相比,向量搜索查询应快 2-5 倍。
+正确配置 gRPC 后,与仅使用 HTTP 的连接相比,向量搜索查询应快 2-5 倍。
## 故障排除
@@ -619,7 +518,6 @@ docker compose logs -f api | grep -i "query_time\|duration"
**原因**:未安装 weaviate-client v4,或仍在使用 v3。
**解决方案**:
-
```bash
# 对于 Docker 安装,请确保运行正确的 Dify 版本
docker compose pull
@@ -641,7 +539,6 @@ pip install weaviate-client==4.17.0
端口在容器之间内部可用。除非从 Docker 外部连接,否则无需操作。
2. **对于外部 Weaviate**:
-
```bash
# 检查 Weaviate 是否在 50051 上监听
docker ps | grep weaviate
@@ -652,7 +549,6 @@ pip install weaviate-client==4.17.0
```
3. **检查防火墙规则**:
-
```bash
# Linux
sudo ufw allow 50051/tcp
@@ -668,7 +564,6 @@ pip install weaviate-client==4.17.0
**解决方案**:
1. 验证 Weaviate 和 Dify 中的 API 密钥匹配:
-
```bash
# 检查 Weaviate 身份验证
curl http://localhost:8080/v1/meta | jq '.authentication'
@@ -678,13 +573,12 @@ pip install weaviate-client==4.17.0
```
2. 如果使用匿名访问:
-
```yaml
# Weaviate docker-compose.yaml
weaviate:
environment:
- AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: "true"
- AUTHENTICATION_APIKEY_ENABLED: "false"
+ AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
+ AUTHENTICATION_APIKEY_ENABLED: 'false'
```
然后从 Dify 配置中删除 `WEAVIATE_API_KEY`。
@@ -717,20 +611,17 @@ docker compose restart worker
**解决方案**:
1. 验证 gRPC 配置:
-
```bash
docker compose exec api env | grep WEAVIATE_GRPC
```
应显示:
-
```
WEAVIATE_GRPC_ENABLED=true
WEAVIATE_GRPC_ENDPOINT=weaviate:50051
```
2. 测试 gRPC 连接:
-
```bash
docker exec -it dify-api-1 nc -zv weaviate 50051
# 应返回"succeeded"
@@ -745,19 +636,16 @@ docker compose restart worker
**解决方案**:
1. 检查 Weaviate 日志以获取特定错误消息:
-
```bash
docker compose logs weaviate | tail -100
```
2. 列出当前 schema:
-
```bash
curl http://localhost:8080/v1/schema
```
3. 如有必要,删除损坏的集合(⚠️ 这会删除所有数据):
-
```bash
# 先备份!
curl -X DELETE http://localhost:8080/v1/schema/YourCollectionName
@@ -769,7 +657,7 @@ docker compose restart worker
```
- 删除集合会删除所有数据。只有在有备份并准备重新索引所有内容时才这样做。
+删除集合会删除所有数据。只有在有备份并准备重新索引所有内容时才这样做。
### 问题:Docker 卷权限错误
@@ -777,7 +665,6 @@ docker compose restart worker
**原因**:Docker 容器中的用户 ID 不匹配。
**解决方案**:
-
```bash
# 检查 Weaviate 数据目录的所有权
ls -la docker/volumes/weaviate/
@@ -789,21 +676,6 @@ sudo chown -R 1000:1000 docker/volumes/weaviate/
docker compose restart weaviate
```
-### 问题:运行迁移脚本时权限被拒绝(Dify 1.11.0+)
-
-**原因**:在较新的 Dify 版本中 `/home/dify` 目录可能不存在,导致 `uv` 缓存创建失败。
-
-**解决方案**:
-
-```bash
-# 选项 1:使用 --no-cache 标志(推荐)
-uv run --no-cache migrate_weaviate_collections.py
-
-# 选项 2:以 root 用户运行
-docker compose exec -u root worker /bin/bash
-uv run migrate_weaviate_collections.py
-```
-
## 回滚计划
如果迁移失败并且你需要回滚:
@@ -854,7 +726,7 @@ docker compose logs | grep -i error
```
- 如果可能,请始终先在暂存环境中测试回滚过程。在尝试重大迁移之前保留多个备份副本。
+如果可能,请始终先在暂存环境中测试回滚过程。在尝试重大迁移之前保留多个备份副本。
## 其他资源
@@ -883,16 +755,16 @@ docker compose logs | grep -i error
此迁移为 Dify 的向量存储功能带来了重要改进:
-- **更好的性能**:gRPC 支持显著提高查询和导入速度(快 2-5 倍)
+✓ **更好的性能**:gRPC 支持显著提高查询和导入速度(快 2-5 倍)
-- **改进的稳定性**:增强的连接处理和错误恢复
+✓ **改进的稳定性**:增强的连接处理和错误恢复
-- **安全性**:访问 Weaviate 1.19.0 中不可用的安全更新和补丁
+✓ **安全性**:访问 Weaviate 1.19.0 中不可用的安全更新和补丁
-- **面向未来**:访问最新的 Weaviate 功能和持续支持
+✓ **面向未来**:访问最新的 Weaviate 功能和持续支持
虽然这是一个破坏性变更,需要旧版本用户升级服务器,但其好处远远超过了迁移工作。大多数 Docker Compose 用户可以在 15 分钟内通过自动更新完成迁移。
- 如果你遇到本指南未涵盖的任何问题,请在 [Dify GitHub Issues 页面](https://github.com/langgenius/dify/issues)上报告,并添加"weaviate"和"migration"标签。
+如果你遇到本指南未涵盖的任何问题,请在 [Dify GitHub Issues 页面](https://github.com/langgenius/dify/issues)上报告,并添加"weaviate"和"migration"标签。
diff --git a/zh/use-dify/debug/variable-inspect.mdx b/zh/use-dify/debug/variable-inspect.mdx
index 48272221d..296bc7dbc 100644
--- a/zh/use-dify/debug/variable-inspect.mdx
+++ b/zh/use-dify/debug/variable-inspect.mdx
@@ -1,10 +1,11 @@
---
-title: "变量检查器"
+title: "工作流"
icon: "arrow-progress"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/debug/variable-inspect)。
+
变量检查器显示所有流经你工作流的数据。它会在每个节点运行后捕获输入和输出,因此你可以查看正在发生的情况并测试不同的场景。
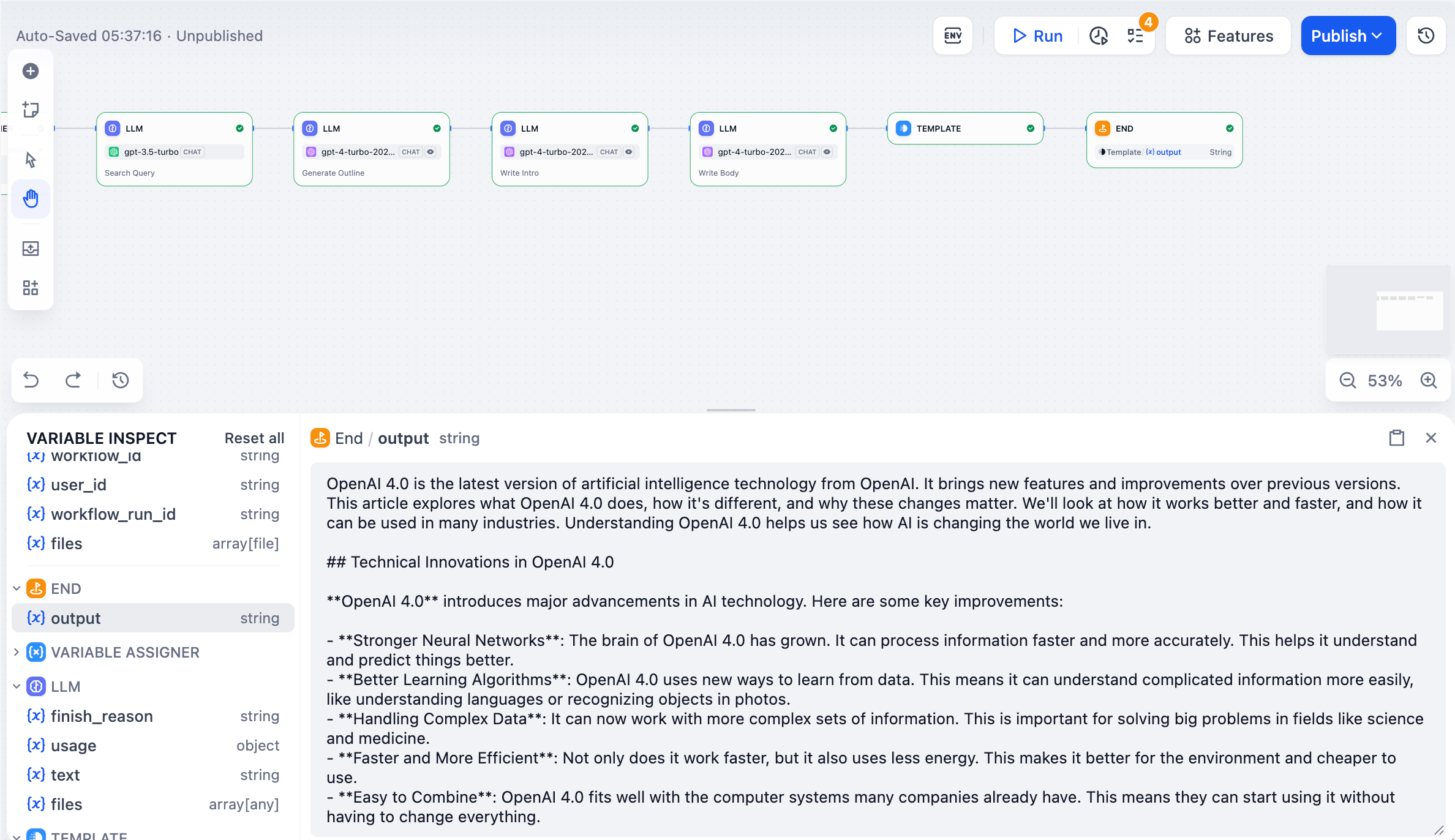
@@ -31,4 +32,4 @@ icon: "arrow-progress"
点击任何变量旁边的还原图标以恢复其原始值,或点击"全部重置"以一次性清除所有缓存变量。
-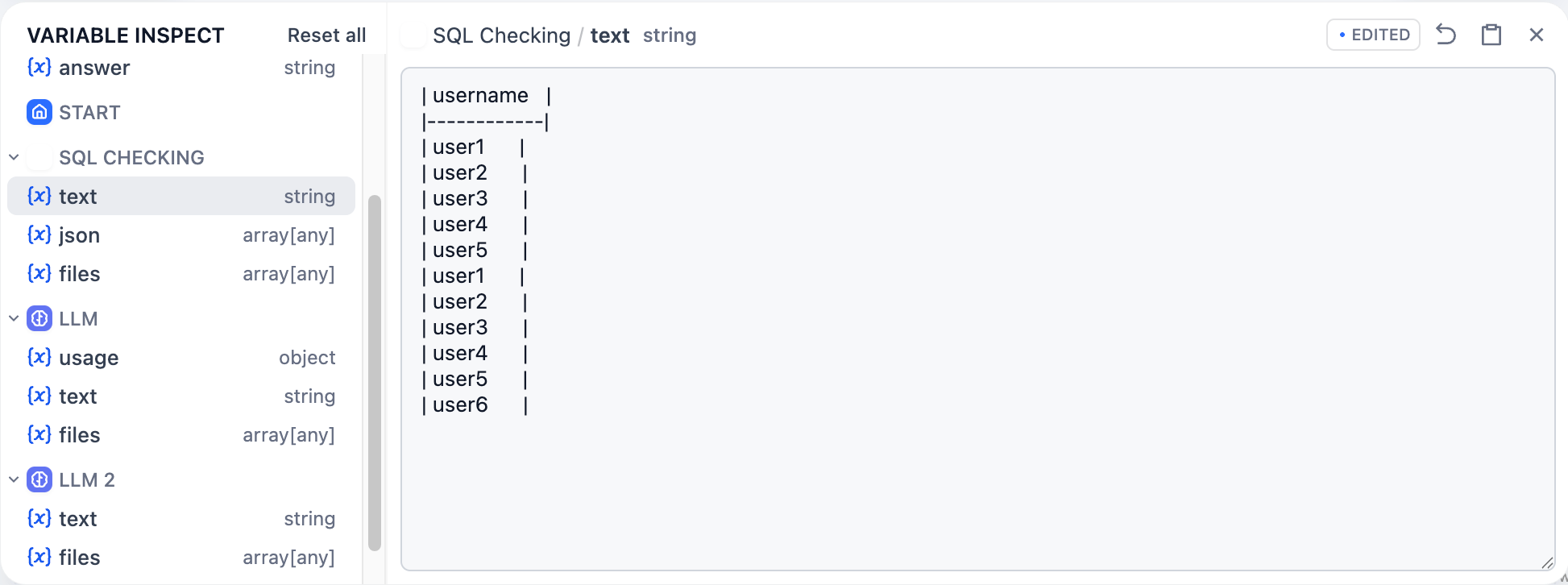
\ No newline at end of file
+
diff --git a/zh/use-dify/getting-started/introduction.mdx b/zh/use-dify/getting-started/introduction.mdx
index e52402060..a17df5b5e 100644
--- a/zh/use-dify/getting-started/introduction.mdx
+++ b/zh/use-dify/getting-started/introduction.mdx
@@ -11,13 +11,13 @@ Dify 是一个用于构建 AI 工作流的开源平台。通过在可视化画

-
+
数分钟内开始构建强大的应用
-
+
核心 Dify 构建模块解释
-
+
在你的笔记本电脑/服务器上安装 Dify
@@ -26,7 +26,7 @@ Dify 是一个用于构建 AI 工作流的开源平台。通过在可视化画
查看过往版本的更新内容
-
+
Dify 用例示例演练
diff --git a/zh/use-dify/knowledge/create-knowledge/import-text-data/readme.mdx b/zh/use-dify/knowledge/create-knowledge/import-text-data/readme.mdx
index b83cb4e32..d7b102530 100644
--- a/zh/use-dify/knowledge/create-knowledge/import-text-data/readme.mdx
+++ b/zh/use-dify/knowledge/create-knowledge/import-text-data/readme.mdx
@@ -14,17 +14,13 @@ title: 上传本地文件
2. 选择 **导入已有文本** 作为数据源,然后上传文件。
- - 单次最多可上传 5 个文件
-
-
- 在 Dify Cloud 上,仅[付费套餐](https://dify.ai/zh/pricing)支持**批量上传**(单次最多 50 个文件)。
-
-
- 单个文件最大支持 15 MB
-
- 对于自托管部署,可通过环境变量 `UPLOAD_FILE_SIZE_LIMIT` 和 `UPLOAD_FILE_BATCH_LIMIT` 调整这两个限制。
-
+ - 单次最多可上传 5 个文件
+
+
+ 在 Dify Cloud 上,仅 [**Professional** 和 **Team** 套餐](https://dify.ai/pricing) 支持 **批量上传**。
+
---
@@ -32,29 +28,29 @@ title: 上传本地文件
JPG、JPEG、PNG 和 GIF 格式且小于 2 MB 的图片将作为附件,自动提取到对应的分段。这些图片可独立管理,并在检索时与分段一同返回。
- 提取的图片 URL 会保留在分段文本中,但你可以放心删除这些 URL 以保持文本整洁——这不会影响已提取的图片。
-
- 若在索引设置中选择多模态嵌入模型(带有 **Vision** 图标),则提取出的图片也将被向量化并索引以供检索。
-
- 每个分段最多支持 10 个图片附件,超出的图片不会被提取。
-
- 对于自托管部署,可通过环境变量调整以下限制:
-
- - 最大图片尺寸:`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`
-
- - 每个分段的最大附件数量:`SINGLE_CHUNK_ATTACHMENT_LIMIT`
+ 对于自托管部署,可通过环境变量 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` 调整图片大小限制。
+
+ 每个分段最多支持 10 个图片附件,超出的图片不会被提取。
+
+ 对于自托管部署,可通过环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT` 调整此数量限制。
+
+
以上提取规则适用于如下图片类型:
- DOCX 文件中嵌入的图片
-
- 其他文件类型(如 PDF)中嵌入的图片,可通过在[知识流水线](/zh/use-dify/knowledge/knowledge-pipeline/readme)中使用合适的文档提取插件进行提取。
-
+
+ 更多文件类型(如 PDF)中嵌入的图片,只能通过在 [知识流水线](/zh/use-dify/knowledge/knowledge-pipeline/readme) 中使用合适的文档提取器插件(如 MinerU)进行提取。
+
- 在任何文件类型中,通过以下 Markdown 语法引用、URL 可访问的图片:
- - ``
- - ``
+ - ``
+ - ``
+
+
+ 若在后续的索引设置中选择多模态嵌入模型(带有 **Vision** 图标),则提取出的图片将被向量化并参与检索。
+
\ No newline at end of file
diff --git a/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods.mdx b/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods.mdx
index 430230515..fa9f1e247 100644
--- a/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods.mdx
+++ b/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods.mdx
@@ -4,13 +4,17 @@ title: 指定索引方式与检索设置
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods)。
-选定内容的分段模式后,接下来设定对于结构化内容的**索引方式**。
+选定内容的分段模式后,接下来设定对于结构化内容的**索引方式**与**检索设置**。
## 选择索引方式
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
-提供 **高质量** 与 **经济** 两种索引方式,其中分别提供不同的检索设置选项。
+提供 **高质量** 与 **经济** 两种索引方式,其中分别提供不同的检索设置选项:
+
+
+ 原 Q&A 模式(仅适用于社区版)已成为高质量索引方式下的一个可选项。
+
@@ -23,172 +27,162 @@ title: 指定索引方式与检索设置
这些向量可理解为多维空间中的坐标点——两个点越接近,它们的语义越相似。这使得系统能够基于语义相似度(而不仅仅是关键词匹配)找到相关信息。
-
- 若要启用跨模态检索——即基于语义相关性同时检索文本和图片——需选择多模态嵌入模型(带有 **Vision** 图标)。从文档中提取的图片将被嵌入并索引以供检索。
+
+ 若要启用跨模态检索——即基于语义相关性同时检索文本和图片,需选择多模态嵌入模型(带有 **Vision** 图标)。从文档中提取的图片将被向量化并参与检索。
- 使用此类嵌入模型的知识库,其卡片上标有 **Multimodal**。
+ 使用此类嵌入模型的知识库,其卡片上标有 **Multimodal**。
-
-
+
+
高质量索引方式支持三种检索策略:向量检索、全文检索或混合检索。详见 [指定检索设置](#指定检索设置)。
- ### Q&A 模式
+ **启用 Q\&A 模式(可选,仅适用于社区版)**
-
- Q&A 模式仅适用于自托管部署。
-
-
- 开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q&A 匹配对。
-
- 与常见的 「Q to P」(用户问题匹配文本段落)策略不同,Q&A 模式采用 「Q to Q」(问题匹配问题)策略。
+ 开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q\&A 匹配对。与常见的 「Q to P」(用户问题匹配文本段落)策略不同,QA 模式采用 「Q to Q」(问题匹配问题)策略。
- 这种方法特别有效,因为常见问题文档中的文本**通常是具备完整语法结构的自然语言**。
+ 这是因为 「常见问题」 文档里的文本**通常是具备完整语法结构的自然语言**,Q to Q 模式会令问题和答案的匹配更加清晰,并同时满足一些高频和高相似度问题的提问场景。
- > **Q to Q** 策略使问题和答案的匹配更加清晰,并能更好地支持高频或高相似度问题的场景。
+ > **Q\&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用**[**经济型索引方式**](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#经济)**。**
- 
+ 
当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地帮助用户检索真正需要的信息。

-
-
-
+
+ **经济**
- 在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需消耗 Token。对于检索到的区块,仅提供倒排索引方式选择最相关的区块。
-
-如果经济型索引方式的效果不符合预期,可以在知识库设置页中升级为高质量索引方式。
+ 在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读[下文](#指定检索设置)。
-
+ 选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 **“高质量”索引方式**。
+ 
-
-## 指定检索设置
-
-知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段。这些片段为 LLM 提供必要的上下文,最终影响其回答的准确性和可信度。
+## 指定检索设置
-常见的检索方式包括:
+知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。这将决定 LLM 所能获取的背景信息,从而影响生成结果的准确性和可信度。
-1. 基于向量相似度的语义检索——将文本块和查询转化为向量,通过相似度评分进行匹配。
-2. 使用倒排索引的关键词匹配(一种标准的搜索引擎技术)。
+常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
-Dify 的知识库支持这两种检索方式。具体可用的检索选项取决于所选的索引方式。
+不同的索引方式对应差异化的检索设置。
-
- **高质量**
+
+ **高质量索引**
- 在**高质量**索引方式下,Dify 提供三种检索设置:**向量检索、全文检索和混合检索**。
+ 在高质量索引方式下,Dify 提供向量检索、全文检索与混合检索设置:
-
+ 
-**向量检索**
+ **向量检索**
-**定义:** 向量化用户输入的问题并生成查询向量,然后将其与知识库中对应的文本向量进行比较,找到最相邻的分段。
+ **定义:** 向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。
-
+ 
-**向量检索设置:**
+ **向量检索设置:**
-**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型对向量检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
+ **Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
-
- 若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
-
+
+ 若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
+
-> 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
+ > 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
-**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
+ **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
-**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
+ **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-> TopK 和 Score 设置仅在 Rerank 阶段生效。因此,要应用这些设置中的任何一项,需要添加并启用 Rerank 模型。
+ > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
***
**全文检索**
-**定义:** 索引文档中的所有词汇,允许用户查询任意词汇并返回包含这些词汇的文本片段。
+ **定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+ 
-**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型对全文检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
+ **Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由全文检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
-
- 若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
-
+
+ 若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
+
-> 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
+ > 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
-**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
+ **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
+ **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-> TopK 和 Score 设置仅在 Rerank 阶段生效。因此,要应用这些设置中的任何一项,需要添加并启用 Rerank 模型。
+ > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
***
-**混合检索**
+ **混合检索**
+
+ **定义:** 同时执行全文检索和向量检索,或 Rerank 模型,从查询结果中选择匹配用户问题的最佳结果。
-**定义:** 同时执行全文检索和向量检索。它包含一个重排序步骤,根据用户的查询从两种搜索结果中选择最佳匹配结果。
+ 
-
+ 在混合检索设置内可以选择启用 **“权重设置”** 或 **“Rerank 模型”**。
-在此模式下,你可以指定**"权重设置"**而无需配置 Rerank 模型 API,或启用 **Rerank 模型**进行检索。
+ * **权重设置**
-* **权重设置**
+ 允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
- 此功能允许用户为语义优先和关键词优先设置自定义权重。关键词检索指的是在知识库内进行全文检索,语义检索指的是在知识库内进行向量检索。
+ * **将语义值拉至 1**
- * **语义值设为 1**
+ **仅启用语义检索模式**。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
+ * **将关键词的值拉至 1**
- 仅启用语义检索模式。借助嵌入模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回相关内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
- * **关键词值设为 1**
+ **仅启用关键词检索模式**。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
+ * **自定义关键词和语义权重**
- 仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
- * **自定义关键词和语义权重**
+ 除了将不同的数值拉至 1,你还可以不断调试二者的权重,找到符合业务场景的最佳权重比例。
+
+ > 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
- 除了仅启用语义检索或关键词检索外,还提供灵活的自定义权重设置。你可以不断调整两种方法的权重,找到符合业务场景的最佳权重比例。
***
- **Rerank 模型**
+ * **Rerank 模型**
- 默认关闭。开启后将使用第三方 Rerank 模型对混合检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
+ 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由混合检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
-
- 若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
-
+
+ 若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
+
- > 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
+ > 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
-**"权重设置"**和**"Rerank 模型"**设置支持以下选项:
+ **“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
-**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
+ **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
+ **Score 阈值:** 用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
-
- **经济**
+
+ **倒排索引**
-在**经济索引**模式下,仅提供倒排索引方式。倒排索引是一种用于快速检索文档中关键词的数据结构,常用于在线搜索引擎。倒排索引仅支持 **TopK** 设置。
+ 在经济索引方式下,仅提供**倒排索引方式**。这是一种用于快速检索文档中关键词的索引结构,常用于在线搜索引擎。倒排索引仅支持 **TopK** 设置项。
-**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
+ **TopK:**
-
-### 参考
+## 阅读更多
-指定检索设置后,你可以参考以下文档查看在不同场景下关键词与内容块的匹配情况。
+指定检索设置后,你可以参考以下文档查看在实际场景下,关键词与内容块的匹配情况。
-
-了解如何测试和引用知识库检索
-
+
+ 查看实际场景下的关键词与内容块匹配情况
+
\ No newline at end of file
diff --git a/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index e7815a19d..09969c7a2 100644
--- a/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -39,11 +39,9 @@ title: "步骤二:编排知识流水线"
4. **用户输入表单配置**:定义流水线使用者需要输入的参数
5. **测试与发布**:验证并正式启用知识库
----
-
## 步骤一:数据源配置
-在一个知识库里,你可以选择单一或多个数据源。目前,Dify 支持 4 种数据源:**文件上传、在线网盘、在线文档和网页爬虫**。
+在一个知识库里,你可以选择单一或多个数据源。每个数据源可以被多次选中,并包含不同配置。目前,Dify 支持 4 种数据源:文件上传、在线网盘、在线文档和网页爬虫。
你也可以前往 [Dify Marketplace](https://marketplace.dify.ai),获得更多数据源。
@@ -109,8 +107,6 @@ title: "步骤二:编排知识流水线"
----
-
### 网页爬虫
将网页内容转化为大型语言模型容易识别的格式,知识库支持 Jina Reader 和 Firecrawl,提供灵活的网页解析能力。
@@ -161,15 +157,13 @@ title: "步骤二:编排知识流水线"
| 最大爬取深度 (Max depth) | 可选 | 控制爬取层级深度 |
| 排除路径 (Exclude paths) | 可选 | 设置不爬取的页面路径 |
| 仅包含路径 (Include only paths) | 可选 | 限制只爬取指定路径 |
-| 启用内容提取器 (Extractor) | 可选 | 选择数据处理方式 |
+| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据处理方式 |
| 只提取主要内容 | 可选 | 过滤页面辅助信息 |
-
+**作成方法**:グローバル入力の`+`ボタンから追加できます。
-
-
-
-| フィールドタイプ | 説明 |
-|---------------|-----------------------------------------------------------------------|
-| テキスト | ナレッジベースユーザーが入力する短文、最大256文字 |
-| 段落 | 長い文字列用の長文テキスト入力欄 |
-| セレクト | オーケストレーターが事前設定した固定オプションから選択、ユーザーはカスタムコンテンツを追加不可 |
-| ブール値 | true/false値のみ |
-| 数値 | 数値入力のみ受付 |
-| 単一ファイル | 単一ファイルアップロード、複数のファイルタイプ(ドキュメント、画像、音声、その他のファイルタイプ)をサポート |
-| ファイルリスト | 複数ファイルの一括アップロード、複数のファイルタイプ(ドキュメント、画像、音声、その他のファイルタイプ)をサポート |
-
-
+### サポートされる入力フィールドタイプ
+ナレッジパイプラインでは7種の入力変数をサポートします:
+
+
+
-
+ 
+
+
+ | フィールドタイプ | 説明 |
+ |---------------|-----------------------------------------------------------------------|
+ | テキスト | 256文字以内の短文の入力欄 |
+ | 段落 | 長文テキストの入力欄 |
+ | セレクト | 設定済み候補リストから選択(カスタム不可) |
+ | ブール値 | 真偽値 |
+ | 数値 | 数値のみ入力 |
+ | 単一ファイル | 単一ファイルアップロード(各ファイルタイプ対応) |
+ | ファイルリスト | 複数ファイルの一括アップロード(各ファイルタイプ対応) |
+
非アクティブ期間はプランごとに異なります:
- Sandbox:7日
- Professional/Team:30日
非アクティブ期間はプランごとに異なります:
- Sandbox:7日
- Professional/Team:30日
親子分割モードのドキュメントでは、親チャンクと子チャンクの両方を追加可能です。
親子分割モード(階層分割モード)のドキュメントでは、親チャンクと子チャンクの両方を追加可能です。
親子分割モードのドキュメントでは:
- 親チャンクを編集するとき、子チャンクを再生成するか変更せずに保持するかを選択できます。
- 子チャンクを編集しても、親チャンクは更新されません。
1つのチャンクにつき最大10個のキーワードを設定可能です。| -| 画像添付ファイルの追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。
抽出された画像のURLはチャンクテキスト内に残りますが、テキストをきれいに保つためにこれらのURLを安全に削除できます。抽出された画像には影響しません。
セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` でこの制限を調整できます。
親子分割モード(階層分割モード)のドキュメントでは:
- 親チャンクを編集するとき、子チャンクを再生成するか保持するかを選択できます。
- 子チャンクを編集しても、親チャンクには影響しません。
1つのチャンクにつき最大10個のキーワードを設定可能です。 | +| 画像の追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。
画像の添付ファイルとチャンクは独立して編集でき、互いに影響しません。
セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` を変更してこの制限を調整できます。
+
+## 設定
+
+ノードが人間の入力を要求し処理する方法を定義するために、以下を設定します:
+
+- **配信方法**:リクエストフォームが受信者に届く方法。
+
+- **フォーム内容**:受信者が見る情報と入力できる内容。
+
+- **ユーザーアクション**:受信者が取れるアクションと、それに応じてワークフローがどのように進行するか。
+
+- **タイムアウト戦略**:設定された時間内に誰も応答しない場合の対応。
+
+### 配信方法
+
+リクエストフォームが配信されるチャネルを選択します。現在利用可能な方法:
+
+- **Webアプリ**:現在のユーザーが応答できるように、Webアプリインターフェースに直接リクエストフォームを表示します。
+
+- **メール**:1人以上の受信者にリクエストフォームのリンクを含むメールを直接送信します。
+
+
+
+
+
@@ -24,6 +23,16 @@ icon: "filter"
+## サポートされるデータ型
+
+ノードは適切なフィルタリングオプションを使用して、さまざまな配列タイプを処理します:
+
+**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
+
+**Array[number]** - 数値データ、スコア、測定値、または計算結果
+
+**Array[file]** - 豊富なメタデータフィルタリング機能を持つ混合ファイルアップロード
+
## 操作
### フィルタリング
@@ -70,7 +79,7 @@ icon: "filter"
**result** - バルク処理用の完全なフィルタリングおよびソート済み配列
-**first_record** - 先頭からの単一要素、「主要」または「最新」アイテム選択に最適
+**first_record** - 先頭からの単一要素、「プテム選択に最適
**last_record** - 末尾からの単一要素、「最新」または「最終」選択に有用
@@ -86,9 +95,31 @@ icon: "filter"
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効化
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリスト演算子ノードを使用:
- - `type = "image"`でフィルタリング → ビジョン機能を持つLLMにルーティング
+ - `type = "image"`でフィルタリング → ビジョン機能を持つ大規模言語モデルにルーティング
- `type = "document"`でフィルタリング → 文書抽出器にルーティング
3. **適切に処理** - 画像は直接分析され、文書はテキスト抽出が行われる
4. **結果を結合** - 処理された出力を統一されたレスポンスにマージ
-このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
\ No newline at end of file
+このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
+
+## 一般的な使用例
+
+**ファイルタイプルーティング** - 混合アップロードをコンテンツタイプに基づいて専門的な処理パイプラインに分離
+
+**データフィルタリング** - 特定の基準に基づいて大規模なデータセットから関連するサブセットを抽出
+
+**コンテンツ優先順位付け** - コレクションから最も重要または最新のアイテムをソートして選択
+
+**品質管理** - 処理前に無効、過大サイズ、またはサポートされていないコンテンツをフィルターで除外
+
+**バッチ準備** - 下流の反復処理や並列処理のためにデータを管理可能なチャンクに整理
+
+## ベストプラクティス
+
+**フィルター基準の計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義
+
+**適切な出力タイプの使用** - 下流ノードがデータをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択
+
+**空の結果の処理** - フィルターが一致しない場合の対処法を検討し、適切なフォールバックロジックを計画
+
+**実データでのテスト** - 本番環境での信頼性のある動作を保証するために、実際のユーザーアップロードでフィルタリング動作を検証
diff --git a/ja/use-dify/nodes/llm.mdx b/ja/use-dify/nodes/llm.mdx
index 5b00f5892..e5fb911fd 100644
--- a/ja/use-dify/nodes/llm.mdx
+++ b/ja/use-dify/nodes/llm.mdx
@@ -6,6 +6,7 @@ icon: "brain"
-モデルパラメータは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**Top P**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
+モデルパラメーターは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**核サンプリング**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
## プロンプト設定
@@ -39,7 +40,7 @@ User: {{user_input}}
## コンテキスト変数
-コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
+コンース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
@@ -54,7 +55,7 @@ User: {{user_input}}
質問:{{user_question}}
```
-知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用を追跡するため、ユーザーは情報源を確認できます。
+知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用と帰属を追跡するため、ユーザーは情報源を確認できます。
## 構造化出力
@@ -93,10 +94,9 @@ User: {{user_input}}
## メモリとファイル処理
-
-メモリを有効にすると、チャットフロー会話内の複数のLLM呼び出しでコンテキストを維持できます。有効にすると、以前のインタラクションがフォーマットされたユーザー - アシスタント出力として後続のプロンプトに含まれます。`USER`テンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
+**メモリ**を有効にすると、ワークフロー実行内の複数のLLM呼び出しでコンテキストを維持できます。ノードは以前のインタラクションを後続のプロンプトに含めます。メモリはノード固有であり、ワークフロー実行間では持続しません。
-**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像を、ClaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
+**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像をaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
### ビジョン機能設定
@@ -104,12 +104,18 @@ User: {{user_input}}
- **高詳細** - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
- **低詳細** - シンプルな画像でより少ないトークンでより高速な処理
-ビジョン機能のデフォルト変数セレクターは`userinput.files`で、ユーザー入力ノードからファイルを自動的に取得します。
+ビジョン機能のデフォルト変数セレクターは`sys.files`で、開始ノードからファイルを自動的に取得します。
+補完モデルでの会話履歴については、マルチターンコンテキストを維持するために会話変数を挿入します:
+
+
+
+
+
## Jinja2テンプレートサポート
LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(`edition_type: "jinja2"`)を使用すると、次のことができます:
@@ -122,9 +128,9 @@ LLMプロンプトは高度な変数処理のためにJinja2テンプレート
Jinja2変数は通常の変数置換とは別に処理され、プロンプト内でループ、条件文、複雑なデータ変換が可能になります。
-## ストリーミング出力
+## ストリーミングレスポンス
-LLMノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
+LLMノードはデフォルトでストリーミングレスポンスをサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
## エラーハンドリング
diff --git a/ja/use-dify/nodes/trigger/overview.mdx b/ja/use-dify/nodes/trigger/overview.mdx
index 87f4edf08..e250ce9aa 100644
--- a/ja/use-dify/nodes/trigger/overview.mdx
+++ b/ja/use-dify/nodes/trigger/overview.mdx
@@ -3,28 +3,26 @@ title: トリガー
sidebarTitle: "概要"
---
-文字
| 説明 | 例 |
|:-----------|:-------------|:---------|
| `*` | 「毎」を意味します。 | **時間**フィールドの `*` は「毎時」を意味します。 |
| `,` | 複数の値を区切ります。 | **曜日**フィールドの `1,3,5` は「月曜日、水曜日、金曜日」を意味します。 |
diff --git a/ja/use-dify/nodes/user-input.mdx b/ja/use-dify/nodes/user-input.mdx
index abfafba3c..a34f4fbb6 100644
--- a/ja/use-dify/nodes/user-input.mdx
+++ b/ja/use-dify/nodes/user-input.mdx
@@ -1,18 +1,16 @@
---
title: "ユーザー入力"
-description: "ワークフローとチャットフローアプリケーションを開始するためのユーザー入力を収集します"
+description: "ワークフローとチャットフローアプリケーションのエントリーポイント"
icon: "input-text"
---
-
@@ -39,64 +40,52 @@ icon: "pen-to-square"
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
@@ -112,7 +101,7 @@ icon: "pen-to-square"
-**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべてのLLMレスポンスでそれらを参照します。
+**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべての大規模言語モデルレスポンスでそれらを参照します。
### 段階的チェックリスト
@@ -122,4 +111,16 @@ icon: "pen-to-square"
-配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、LLMはそれを参照してユーザーを残りのタスクを通じてガイドします。
+配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、大規模言語モデルはそれを参照してユーザーを残りのタスクを通じてガイドします。
+
+## ベストプラクティス
+
+**適切なデータタイプを選択** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用する。
+
+**説明的な変数名を使用** - 会話変数の目的と内容を示すように明確に命名する。
+
+**データの成長を処理** - 長い会話での過度なメモリ使用を防ぐため、配列とオブジェクトのサイズを監視する。
+
+**変数を初期化** - 未定義の動作を防ぐため、会話変数に初期値を設定する。
+
+**適切な場合にクリア** - 新しいプロセスやセッションを開始する際に変数をリセットするためにクリア操作を使用する。
diff --git a/ja/use-dify/workspace/api-extension/api-extension.mdx b/ja/use-dify/workspace/api-extension/api-extension.mdx
deleted file mode 100644
index d1aba75ce..000000000
--- a/ja/use-dify/workspace/api-extension/api-extension.mdx
+++ /dev/null
@@ -1,262 +0,0 @@
----
-title: API 拡張
-sidebarTitle: 概要
----
-
-開発者は API 拡張モジュール機能を使用してモジュール機能を拡張できます。現在、以下のモジュール拡張がサポートされています:
-
-* `moderation` センシティブコンテンツ審査
-* `external_data_tool` 外部データツール
-
-モジュール機能を拡張する前に、API と認証用の API Key を準備する必要があります。
-
-対応するモジュール機能を開発する必要があるだけでなく、Dify が API を正しく呼び出せるように、以下の仕様に従う必要があります。
-
-## API 仕様
-
-Dify は以下の仕様でインターフェースを呼び出します:
-
-```
-POST {Your-API-Endpoint}
-```
-
-### Header
-
-| Header | Value | Desc |
-| --------------- | ----------------- | --------------------------------------------------------------------- |
-| `Content-Type` | application/json | リクエストコンテンツは JSON 形式です。 |
-| `Authorization` | Bearer {api_key} | API Key はトークン形式で送信されます。この `api_key` を解析し、提供された API Key と一致することを確認して、インターフェースのセキュリティを確保する必要があります。 |
-
-### Request Body
-
-```
-{
- "point": string, // 拡張ポイント、異なるモジュールには複数の拡張ポイントが含まれる場合があります
- "params": {
- ... // 各モジュール拡張ポイントに渡されるパラメータ
- }
-}
-```
-
-### API レスポンス
-
-```
-{
- ... // API が返すコンテンツ、異なる拡張ポイントのレスポンスについては各モジュールの仕様設計を参照してください
-}
-```
-
-## 検証
-
-Dify で API-based Extension を設定する際、Dify は API の可用性を確認するために API Endpoint にリクエストを送信します。
-
-API Endpoint が `point=ping` を受信したとき、インターフェースは `result=pong` を返す必要があります。具体的には以下の通りです:
-
-### Header
-
-```
-Content-Type: application/json
-Authorization: Bearer {api_key}
-```
-
-### Request Body
-
-```
-{
- "point": "ping"
-}
-```
-
-### API 期待レスポンス
-
-```
-{
- "result": "pong"
-}
-```
-
-## サンプル
-
-ここでは外部データツールを例として、地域に基づいて外部の天気情報をコンテキストとして取得するシナリオを示します。
-
-### API サンプル
-
-```
-POST https://fake-domain.com/api/dify/receive
-```
-
-**Header**
-
-```
-Content-Type: application/json
-Authorization: Bearer 123456
-```
-
-**Request Body**
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-**API レスポンス**
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-### コードサンプル
-
-コードは Python FastAPI フレームワークに基づいています。
-
-1. 依存関係をインストール
-
- ```
- pip install fastapi[all] uvicorn
- ```
-2. インターフェース仕様に従ってコードを記述
-
- ```
- from fastapi import FastAPI, Body, HTTPException, Header
- from pydantic import BaseModel
-
- app = FastAPI()
-
-
- class InputData(BaseModel):
- point: str
- params: dict = {}
-
-
- @app.post("/api/dify/receive")
- async def dify_receive(data: InputData = Body(...), authorization: str = Header(None)):
- """
- Receive API query data from Dify.
- """
- expected_api_key = "123456" # TODO Your API key of this API
- auth_scheme, _, api_key = authorization.partition(' ')
-
- if auth_scheme.lower() != "bearer" or api_key != expected_api_key:
- raise HTTPException(status_code=401, detail="Unauthorized")
-
- point = data.point
-
- # for debug
- print(f"point: {point}")
-
- if point == "ping":
- return {
- "result": "pong"
- }
- if point == "app.external_data_tool.query":
- return handle_app_external_data_tool_query(params=data.params)
- # elif point == "{point name}":
- # TODO other point implementation here
-
- raise HTTPException(status_code=400, detail="Not implemented")
-
-
- def handle_app_external_data_tool_query(params: dict):
- app_id = params.get("app_id")
- tool_variable = params.get("tool_variable")
- inputs = params.get("inputs")
- query = params.get("query")
-
- # for debug
- print(f"app_id: {app_id}")
- print(f"tool_variable: {tool_variable}")
- print(f"inputs: {inputs}")
- print(f"query: {query}")
-
- # TODO your external data tool query implementation here,
- # return must be a dict with key "result", and the value is the query result
- if inputs.get("location") == "London":
- return {
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind "
- "Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
- }
- else:
- return {"result": "Unknown city"}
- ```
-3. API サービスを起動します。デフォルトポートは 8000 で、完全な API アドレスは `http://127.0.0.1:8000/api/dify/receive`、設定された API Key は `123456` です。
-
- ```
- uvicorn main:app --reload --host 0.0.0.0
- ```
-4. Dify でこの API を設定します。
-
-5. App でこの API 拡張を選択します。
-
-App のデバッグ時、Dify は設定された API にリクエストを送信し、以下の内容を送信します(サンプル):
-
-```
-{
- "point": "app.external_data_tool.query",
- "params": {
- "app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
- "tool_variable": "weather_retrieve",
- "inputs": {
- "location": "London"
- },
- "query": "How's the weather today?"
- }
-}
-```
-
-API レスポンスは:
-
-```
-{
- "result": "City: London\nTemperature: 10°C\nRealFeel®: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
-}
-```
-
-## ローカルデバッグ
-
-Dify クラウド版では内部ネットワークの API サービスにアクセスできないため、ローカルで API サービスをデバッグするために、[Ngrok](https://ngrok.com) を使用して API サービスのエンドポイントを公開ネットワークに公開し、クラウドでローカルコードをデバッグできるようにします。操作手順:
-
-1. [https://ngrok.com](https://ngrok.com) の公式サイトにアクセスし、登録して Ngrok ファイルをダウンロードします。
-
- 
-
-2. ダウンロード完了後、ダウンロードディレクトリに移動し、以下の説明に従って圧縮ファイルを解凍し、説明の初期化スクリプトを実行します。
- ```Shell
- unzip /path/to/ngrok.zip
- ./ngrok config add-authtoken あなたのToken
- ```
-3. ローカル API サービスのポートを確認します:
-
- 
-
- そして、以下のコマンドを実行して起動します:
-
- ```Shell
- ./ngrok http ポート番号
- ```
-
- 起動成功のサンプルは以下の通りです:
-
- 
-
-4. Forwarding の中から、上図のように `https://177e-159-223-41-52.ngrok-free.app`(これはサンプルドメインです、自分のものに置き換えてください)が公開ネットワークドメインです。
-
-上記のサンプルに従って、ローカルで既に起動されているサービスエンドポイントを公開し、コードサンプルのインターフェース `http://127.0.0.1:8000/api/dify/receive` を `https://177e-159-223-41-52.ngrok-free.app/api/dify/receive` に置き換えます。
-
-この API エンドポイントは公開ネットワークでアクセス可能になります。これで、Dify でこの API エンドポイントを設定してローカルコードをデバッグできます。設定手順については、[外部データツール](/ja/use-dify/workspace/api-extension/external-data-tool-api-extension) を参照してください。
-
-## Cloudflare Workers を使用した API 拡張のデプロイ
-
-API 拡張をデプロイするには Cloudflare Workers の使用をお勧めします。Cloudflare Workers は簡単に公開ネットワークアドレスを提供でき、無料で使用できます。
-
-詳細な説明については、[Cloudflare Workers を使用した API 拡張のデプロイ](/ja/use-dify/workspace/api-extension/cloudflare-worker) を参照してください。
diff --git a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx b/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
deleted file mode 100644
index decc1237f..000000000
--- a/ja/use-dify/workspace/api-extension/cloudflare-worker.mdx
+++ /dev/null
@@ -1,131 +0,0 @@
----
-title: Cloudflare Workers を使用した API 拡張のデプロイ
----
-
-## はじめに
-
-Dify API 拡張は API Endpoint としてアクセス可能な公開ネットワークアドレスを使用する必要があるため、API 拡張を公開ネットワークアドレスにデプロイする必要があります。
-
-ここでは Cloudflare Workers を使用して API 拡張をデプロイします。
-
-[Example GitHub Repository](https://github.com/crazywoola/dify-extension-workers) をクローンします。このリポジトリには簡単な API 拡張が含まれており、これをベースに変更できます。
-
-```bash
-git clone https://github.com/crazywoola/dify-extension-workers.git
-cp wrangler.toml.example wrangler.toml
-```
-
-`wrangler.toml` ファイルを開き、`name` と `compatibility_date` をアプリケーション名と互換性日付に変更します。
-
-ここで注意が必要な設定は、`vars` 内の `TOKEN` です。Dify で API 拡張を追加する際に、この Token を入力する必要があります。セキュリティ上の理由から、Token としてランダムな文字列を使用することをお勧めします。ソースコードに直接 Token を書き込むのではなく、環境変数を使用して Token を渡すべきです。そのため、wrangler.toml をコードリポジトリにコミットしないでください。
-
-```toml
-name = "dify-extension-example"
-compatibility_date = "2023-01-01"
-
-[vars]
-TOKEN = "bananaiscool"
-```
-
-この API 拡張はランダムな Breaking Bad の名言を返します。`src/index.ts` でこの API 拡張のロジックを変更できます。この例は、サードパーティ API とのやり取り方法を示しています。
-
-```typescript
-// ⬇️ implement your logic here ⬇️
-// point === "app.external_data_tool.query"
-// https://api.breakingbadquotes.xyz/v1/quotes
-const count = params?.inputs?.count ?? 1;
-const url = `https://api.breakingbadquotes.xyz/v1/quotes/${count}`;
-const result = await fetch(url).then(res => res.text())
-// ⬆️ implement your logic here ⬆️
-```
-
-このリポジトリはビジネスロジック以外のすべての設定を簡略化しています。`npm` コマンドを直接使用して API 拡張をデプロイできます。
-
-```bash
-npm install
-npm run deploy
-```
-
-デプロイが成功すると、公開ネットワークアドレスが取得できます。このアドレスを Dify の API Endpoint として追加できます。`endpoint` パスを忘れないでください。このパスの具体的な定義は `src/index.ts` で確認できます。
-
-
-
-また、`npm run dev` コマンドを使用してローカルにデプロイしてテストすることもできます。
-
-```bash
-npm install
-npm run dev
-```
-
-関連する出力:
-
-```bash
-$ npm run dev
-> dev
-> wrangler dev src/index.ts
-
- ⛅️ wrangler 3.99.0
--------------------
-
-Your worker has access to the following bindings:
-- Vars:
- - TOKEN: "ban****ool"
-⎔ Starting local server...
-[wrangler:inf] Ready on http://localhost:58445
-```
-
-その後、Postman などのツールを使用してローカルインターフェースをデバッグできます。
-
-## Bearer Auth について
-
-```typescript
-import { bearerAuth } from "hono/bearer-auth";
-
-(c, next) => {
- const auth = bearerAuth({ token: c.env.TOKEN });
- return auth(c, next);
-},
-```
-
-Bearer 検証ロジックは上記のコードにあります。`hono/bearer-auth` パッケージを使用して Bearer 検証を実装しています。`src/index.ts` で `c.env.TOKEN` を使用して Token を取得できます。
-
-## パラメータ検証について
-
-```typescript
-import { z } from "zod";
-import { zValidator } from "@hono/zod-validator";
-
-const schema = z.object({
- point: z.union([
- z.literal("ping"),
- z.literal("app.external_data_tool.query"),
- ]), // Restricts 'point' to two specific values
- params: z
- .object({
- app_id: z.string().optional(),
- tool_variable: z.string().optional(),
- inputs: z.record(z.any()).optional(),
- query: z.any().optional(), // string or null
- })
- .optional(),
-});
-
-```
-
-ここでは `zod` を使用してパラメータの型を定義しています。`src/index.ts` で `zValidator` を使用してパラメータを検証できます。`const { point, params } = c.req.valid("json");` で検証済みパラメータを取得します。
-
-ここでの `point` は 2 つの値しかないため、`z.union` を使用して定義しています。`params` はオプションのパラメータなので、`z.optional` を使用して定義しています。その中には `inputs` パラメータがあり、これは `Record
+
3. 負荷分散プールで少なくとも2つの認証情報を有効にし、**保存** をクリックします。負荷分散が有効になったモデルには、特別なアイコンが表示されます。
- 
+
-
+
-
-
-[Unstructured](https://marketplace-staging.dify.dev/plugins/langgenius/unstructured) 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
+Unstructured 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
全文检索
混合检索 | | 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索
全文检索
混合检索 | ---- - ## 步骤四:配置用户输入表单 -用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[用户输入节点](/zh/use-dify/nodes/user-input),这个表单从用户那里收集必要的详细信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。 +用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[用户输入节点](/zh/use-dify/nodes/user-input),这个表单从用户那里收集必要的相信信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。 -通过这种方式,你可以为不同的使用场景创建特定的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。 +通过这种方式,你可以为不同的使用场景创建特定的的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。 ### 创建用户输入表单 你可以通过下面两种方式,创建用户输入表单。 -1. **知识流水线编排界面**\ - 点击输入字段(Input Field)开始创建和配置输入表单。\ -
-2. **节点参数面板**\
- 选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。
+1. **知识流水线编排界面** 点击输入字段(Input Field)开始创建和配置输入表单。
+
+ 
+2. **节点参数面板** 选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。
-### 添加用户输入字段
+ 
+
+### 输入类型
#### 非共享输入 (Unique Inputs for Each Entrance)
@@ -451,15 +438,17 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
这类输入适用于每个数据源及其下游节点,用户只需在选择对应数据源时填写这些字段,比如不同数据源的URL。
-**创建方式**:在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。
+在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。
+
+
-#### 全局共享输入 (Global Inputs for All Entrances)
+#### 全局共享输入 (Global Inputs for All Entrance)

全局共享输入可以被所有节点引用。这类输入适用于通用处理参数,比如分隔符、最大分块长度、文档处理配置等。无论用户选择哪个数据源,都需要填写这些字段。
-**创建方式**:在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。
+在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。
### 支持字段类型和填写说明
@@ -479,8 +468,8 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
| 下拉选项 | 由编排者预设的固定选项供使用者选择,使用者无法自行填写内容 |
| 布尔值 | 只有真/假两个取值 |
| 数字 | 只能输入数字 |
-| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频和其他文件类型) |
-| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频和其他文件类型) |
+| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
+| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
@@ -490,48 +479,38 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
请阅读[用户输入节点](/zh/use-dify/nodes/user-input),了解关于支持字段的更多说明。
-### 字段配置选项
-
所有类型的输入项包含:必填项、非必填项和更多设置,可以通过勾选设置为是否为必填。
-| 设置类型 | 名称 | 说明 | 示例 |
-| ---------- | ----------- | --------------------------- | ------------------ |
-| 必填项 | 变量名称 | 系统内部标识名称,通常使用英文和下划线进行命名 | `user_email` |
-| | 显示名称 | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
-| 类型特定设置 | | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
-| 更多设置 | 默认值 | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
-| | 占位符 | 输入框空白时的提示文字 | 请输入您的邮箱 |
-| | 提示 | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
-| 特殊非必填信息 | | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
+| 名称 | 说明 | 示例 |
+| ------------------ | --------------------------- | ------------------ |
+| **必填项** | | |
+| 变量名称 Variable Name | 系统内部标识名称,通常使用英文和下划线进行命名 | `user_email` |
+| 显示名称 Display Name | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
+| **类型特定设置** | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
+| **更多设置** | | |
+| 默认值 Default Value | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
+| 占位符 Placeholder | 输入框空白时的提示文字 | 请输入您的邮箱 |
+| 提示 Tooltip | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
+| **特殊非必填信息** | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
配置完成后,点击右上角的预览按钮,你可以在弹出的表单预览界面中浏览。你可以拖拽调整字段的分组,如果出现感叹号,则表明移动后引用失效。

----
-
## 步骤五:为知识库命名

-默认情况下,知识库名称为"Untitled + 序号",权限设置为"仅自己可见",图标为橙色书本。如果你使用 DSL文件导入,则将使用其保存的图标。
+默认情况下,知识库名称为"Untitled + 序号”,权限设置为"仅自己可见”,图表为橙色书本。如果你使用 DSL文件导入,则将使用其保存的图标。
-点击左侧面板中的**设置**并填写以下信息:
+点击左侧面板中的设置并填写以下信息:
-- **名称和图标**\
- 为你的知识库命名。\
- 你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
-- **知识库描述**\
- 简要描述您的知识库。这有助于 AI 更好地理解和检索您的数据。如果留空,Dify 将应用默认的检索策略。
-- **权限**\
- 从下拉菜单中选择适当的访问权限。
-
----
+- **名称和图标** 为你的知识库命名。你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
+- **知识库描述** 简要描述您的知识库。这有助于 AI 更好地理解和检索您的数据。如果留空,Dify 将应用默认的检索策略。
+- **权限** 从下拉菜单中选择适当的访问权限。
## 步骤六:测试
-你马上就要完成了!这是知识流水线编排的最后一步。
-
在完成编排后,你需要先验证配置的完整性,然后测试流水线运行效果,确认各项设置正确无误,最后发布知识库。
### 检查配置完成度
@@ -548,15 +527,14 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种

-1. **开始测试**:点击右上角的测试运行(Test Run)按钮
-2. **导入测试文件**:在右侧弹出的数据源窗口中,导入文件
-
-不同订阅计划的未活跃时长如下:
- Sandbox:7 天
- Professional & Team:30 天
不同订阅计划的未活跃时长如下:
- Sandbox:7 天
- Professional & Team:30 天
对于采用父子分段模式的文档,可同时新增父分段和子分段。
对于采用父子分段模式的文档:
- 编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。
- 编辑子分段不会改变其父分段。
对于采用父子分段模式的文档:
- 编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。
- 编辑子分段不会改变其父分段。
一个分段最多可添加 10 个关键词。| -| 添加 / 删除图片附件 | 在对应分段中,删除从文档中提取的图片或上传新图片。
提取的图片 URL 会保留在分段文本中,你可以安全地删除这些 URL 以保持文本简洁——这不会影响已提取的图片。
对于自托管部署,可通过修改环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT` 调整此数量限制。
图片附件和分段内容可独立编辑,互不影响。
对于自托管部署,可通过修改环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT`(默认值:10)调整此数量限制。
+
+## 配置
+
+配置以下内容以定义节点如何请求和处理人工输入:
+
+- **发送方式**:请求表单如何发送给接收者。
+
+- **表单内容**:接收者将看到什么信息以及他们可以输入什么。
+
+- **用户操作**:接收者可以采取哪些操作,以及工作流如何相应地继续。
+
+- **超时策略**:如果在设定时间内没有人响应会发生什么。
+
+### 发送方式
+
+选择发送请求表单的渠道。目前可用的方式:
+
+- **Web 应用**:直接在 Web 应用界面中显示请求表单,供当前用户响应。
+
+- **电子邮件**:直接向一个或多个接收者发送包含请求表单链接的电子邮件。
+
+
+
+
@@ -24,6 +22,16 @@ icon: "filter"
+## 支持的数据类型
+
+该节点处理不同的数组类型,并提供相应的筛选选项:
+
+**Array[string]** - 文本列表、类别、名称或任何字符串集合
+
+**Array[number]** - 数值数据、分数、测量值或计算结果
+
+**Array[file]** - 具有丰富元数据筛选功能的混合文件上传
+
## 操作
### 筛选
@@ -91,4 +99,26 @@ icon: "filter"
3. **适当处理** - 图像被直接分析,文档进行文本提取
4. **合并结果** - 将处理后的输出合并为统一响应
-这种模式自动将不同文件类型路由到适当的处理器,创建无缝的多模态用户体验。
\ No newline at end of file
+这种模式自动将不同文,创建无缝的多模态用户体验。
+
+## 常见用例
+
+**文件类型路由** - 根据内容类型将混合上传分离到专门的处理管道中。
+
+**数据筛选** - 根据特定条件从大型数据集中提取相关子集。
+
+**内容优先级排序** - 从集合中排序并选择最重要或最近的项目。
+
+**质量控制** - 在处理前筛选出无效、超大或不支持的内容。
+
+**批处理准备** - 将数据组织成可管理的块,用于下游迭代或并行处理。
+
+## 最佳实践
+
+**规划筛选条件** - 根据下游处理要求定义清晰的筛选规则。
+
+**使用适当的输出类型** - 根据下游节点如何使用数据,选择完整数组、第一条记录或最后一条记录。
+
+**处理空结果** - 考虑筛选器返回无匹配时会发生什么,并规划适当的后备逻辑。
+
+**使用真实数据测试** - 使用实际用户上传验证筛选行为,确保在生产环境中可靠运行。
diff --git a/zh/use-dify/nodes/llm.mdx b/zh/use-dify/nodes/llm.mdx
index 6c76e1cee..8d7883e68 100644
--- a/zh/use-dify/nodes/llm.mdx
+++ b/zh/use-dify/nodes/llm.mdx
@@ -1,11 +1,11 @@
---
title: "大语言模型"
-description: "调用语言模型进行文本生成和分析"
icon: "brain"
---
+对于完成模型中的对话历史,插入对话变量以维护多轮对话上下文:
+
+
+
+
+
## Jinja2 模板支持
大型语言模型提示词支持 Jinja2 模板以进行高级变量处理。当你使用 Jinja2 模式(`edition_type: "jinja2"`)时,你可以:
diff --git a/zh/use-dify/nodes/trigger/overview.mdx b/zh/use-dify/nodes/trigger/overview.mdx
index b9e45cfd5..89636c59e 100644
--- a/zh/use-dify/nodes/trigger/overview.mdx
+++ b/zh/use-dify/nodes/trigger/overview.mdx
@@ -3,29 +3,26 @@ title: 触发器
sidebarTitle: "概述"
---
-字符
| 描述 | 示例 |
|:-----------|:-------------|:---------|
| `*` | 表示「每个」。 | **小时** 字段中的 `*` 表示「每个小时」。 |
| `,` | 分隔多个值。 | **星期几** 字段中的 `1,3,5` 表示「星期一、星期三和星期五」。 |
diff --git a/zh/use-dify/nodes/user-input.mdx b/zh/use-dify/nodes/user-input.mdx
index 9e3433407..0e3def687 100644
--- a/zh/use-dify/nodes/user-input.mdx
+++ b/zh/use-dify/nodes/user-input.mdx
@@ -1,6 +1,6 @@
---
title: "用户输入"
-description: "收集用户输入以启动工作流和对话流应用程序"
+description: "工作流和对话流应用程序的入口点"
icon: "input-text"
---
@@ -8,11 +8,9 @@ icon: "input-text"
## 简介
-用户输入节点允许你定义从最终用户收集哪些内容作为应用程序的输入。
+用户输入节点是一种开始节点,你可以在其中定义应用程序运行时从最终用户收集的信息。
-使用此节点启动的应用程序*按需*运行,可以通过直接用户交互或 API 调用启动。
-
-你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
+使用此节点启动的应用程序按需运行,通过直接用户交互或 API 调用启动。你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
@@ -39,58 +39,46 @@ icon: "pen-to-square"
不同变量类型根据其数据结构支持不同的操作:
-使用**覆写**模式从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
+从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
### 渐进式清单
@@ -123,3 +111,15 @@ icon: "pen-to-square"
使用数组会话变量跟踪已完成的项目。变量赋值器在每轮更新清单,而大型语言模型引用它来指导用户完成剩余任务。
+
+## 最佳实践
+
+**选择适当的数据类型** - 对于不断增长的集合使用数组,对于结构化数据使用对象,对于单个值使用简单类型。
+
+**使用描述性变量名** - 清晰地命名会话变量以表明其用途和内容。
+
+**处理数据增长** - 监控数组和对象大小,防止在长对话中过度使用内存。
+
+**初始化变量** - 为会话变量设置初始值以防止未定义行为。
+
+**适当时清除** - 在开始新流程或会话时使用清除操作来重置变量。
diff --git a/zh/use-dify/pages/build/mcp.mdx b/zh/use-dify/pages/build/mcp.mdx
new file mode 100644
index 000000000..ca5f1dac0
--- /dev/null
+++ b/zh/use-dify/pages/build/mcp.mdx
@@ -0,0 +1,108 @@
+---
+title: "使用 MCP 工具"
+icon: "microchip"
+---
+
+ +这些应用类型在底层运行相同的工作流引擎,但提供了更简单的传统界面:
+
+这些应用类型在底层运行相同的工作流引擎,但提供了更简单的传统界面:
+ +
+ +
+此外,用户输入节点还带有一组输入变量,你可以在流程中稍后引用。根据应用程序类型(工作流或对话流),会提供不同的变量。
+
+
+
+此外,用户输入节点还带有一组输入变量,你可以在流程中稍后引用。根据应用程序类型(工作流或对话流),会提供不同的变量。
+
+数据类型
| 描述 | 注释 |
+ |:----------------|:-----------|:-------------|:--------|
+ | `sys.user_id` | String | 用户 ID:系统在用户使用工作流应用程序时自动分配给每个用户的唯一标识符。用于区分不同的用户。 | |
+ | `sys.app_id` | String | 应用程序 ID:系统自动分配给每个应用程序的唯一标识符。此参数用于记录当前应用程序的基本信息。 | 此参数用于具有开发能力的用户区分和定位不同的工作流应用程序。 |
+ | `sys.workflow_id` | String | 工作流 ID:此参数记录当前工作流应用程序中所有节点的信息。 | 此参数可供具有开发能力的用户用于跟踪和记录工作流中包含的节点信息。 |
+ | `sys.workflow_run_id` | String | 工作流运行 ID:用于记录工作流应用程序的运行时状态和执行日志。 | 此参数可供具有开发能力的用户用于跟踪应用程序的历史执行记录。 |
+ | `sys.timestamp` | String | 每次工作流执行的开始时间。 | |
+
+ 数据类型
| 描述 | 注释 |
+ |:----------------|:-----------|:-------------|:--------|
+ | `sys.conversation_id` | String | 聊天框交互会话的唯一 ID,将所有相关消息分组到同一对话中,确保 LLM 在相同的主题和上下文中继续聊天。 | |
+ | `sys.dialogue_count` | Number | 用户与对话流应用程序交互期间的对话轮次数。每次聊天轮次后计数自动增加 1,可与 if-else 节点结合使用以创建丰富的分支逻辑。例如,LLM 将在第 X 个对话轮次时审查对话历史并自动提供分析。 | | + | `sys.user_id` | String | 为每个应用程序用户分配一个唯一 ID,以区分不同的对话用户。 | 服务 API 不共享 WebApp 创建的对话。这意味着具有相同 ID 的用户将在 API 和 WebApp 界面之间具有单独的对话历史记录。 | + | `sys.app_id` | String | 应用程序 ID:系统自动分配给每个应用程序的唯一标识符。此参数用于记录当前应用程序的基本信息。 | 此参数用于具有开发能力的用户区分和定位不同的工作流应用程序。 | + | `sys.workflow_id` | String | 工作流 ID:此参数记录当前工作流应用程序中所有节点的信息。 | 此参数可供具有开发能力的用户用于跟踪和记录工作流中包含的节点信息。 | + | `sys.workflow_run_id` | String | 工作流运行 ID:用于记录工作流应用程序的运行时状态和执行日志。 | 此参数可供具有开发能力的用户用于跟踪应用程序的历史执行记录。 | + +
 +
+与输入一样,节点输出也无法更新。
+
+**环境变量**:使用环境变量来存储你应用特定的敏感信息,如 API 密钥。这允许在密钥和 Dify 应用本身之间进行清晰分离,因此在分享你的应用领域特定语言时,你不必承担暴露密码和密钥的风险。环境变量也是常量,无法更新。
+
+**会话变量(仅对话流)**:这些变量是对话特定的——意味着它们在单个对话的多轮对话流运行中持续存在,因此你可以存储和访问动态信息,如待办事项列表和令牌成本。你可以通过变量分配器节点更新会话变量的值:
+
+
+
+与输入一样,节点输出也无法更新。
+
+**环境变量**:使用环境变量来存储你应用特定的敏感信息,如 API 密钥。这允许在密钥和 Dify 应用本身之间进行清晰分离,因此在分享你的应用领域特定语言时,你不必承担暴露密码和密钥的风险。环境变量也是常量,无法更新。
+
+**会话变量(仅对话流)**:这些变量是对话特定的——意味着它们在单个对话的多轮对话流运行中持续存在,因此你可以存储和访问动态信息,如待办事项列表和令牌成本。你可以通过变量分配器节点更新会话变量的值:
+
+ +
+### 变量引用
+
+在配置输入字段时,你可以通过从下拉菜单中选择,轻松将变量传递给任何节点:
+
+
+
+### 变量引用
+
+在配置输入字段时,你可以通过从下拉菜单中选择,轻松将变量传递给任何节点:
+
+ +
+你还可以通过键入 `/` 斜杠并从下拉菜单中选择所需变量,将变量值插入到复杂的文本输入中。
+
+
+
+你还可以通过键入 `/` 斜杠并从下拉菜单中选择所需变量,将变量值插入到复杂的文本输入中。
+
+ diff --git a/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx b/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx
new file mode 100644
index 000000000..d18abd998
--- /dev/null
+++ b/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx
@@ -0,0 +1,143 @@
+---
+title: 连接外部知识库
+icon: "link"
+---
+
+> 为做出区别,独立于 Dify 平台之外的知识库在本文内均被统称为 **“外部知识库”** 。
+
+## 功能简介
+
+对于内容检索有着更高要求的进阶开发者而言,Dify 平台内置的知识库功能和文本检索和召回机制**存在限制,无法轻易变更文本召回结果。**
+
+出于对文本检索和召回的精确度有着更高追求,以及对内部资料的管理需求,部分团队选择自主研发 RAG 算法并独立维护文本召回系统、或将内容统一托管至云厂商的知识库服务(例如 [AWS Bedrock](https://aws.amazon.com/bedrock/))。
+
+作为中立的 LLM 应用开发平台,Dify 致力于给予开发者更多选择权。
+
+**连接外部知识库**功能可以将 Dify 平台与外部知识库建立连接。通过 API 服务,AI 应用能够获取更多信息来源。这意味着:
+
+* Dify 平台能够直接获取托管在云服务提供商知识库内的文本内容,开发者无需将内容重复搬运至 Dify 中的知识库;
+* Dify 平台能够直接获取自建知识库内经算法处理后的文本内容,开发者仅需关注自建知识库的信息检索机制,并不断优化与提升信息召回的准确度。
+
+
+
diff --git a/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx b/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx
new file mode 100644
index 000000000..d18abd998
--- /dev/null
+++ b/zh/use-dify/pages/knowledge/connect-external-knowledge-base.mdx
@@ -0,0 +1,143 @@
+---
+title: 连接外部知识库
+icon: "link"
+---
+
+> 为做出区别,独立于 Dify 平台之外的知识库在本文内均被统称为 **“外部知识库”** 。
+
+## 功能简介
+
+对于内容检索有着更高要求的进阶开发者而言,Dify 平台内置的知识库功能和文本检索和召回机制**存在限制,无法轻易变更文本召回结果。**
+
+出于对文本检索和召回的精确度有着更高追求,以及对内部资料的管理需求,部分团队选择自主研发 RAG 算法并独立维护文本召回系统、或将内容统一托管至云厂商的知识库服务(例如 [AWS Bedrock](https://aws.amazon.com/bedrock/))。
+
+作为中立的 LLM 应用开发平台,Dify 致力于给予开发者更多选择权。
+
+**连接外部知识库**功能可以将 Dify 平台与外部知识库建立连接。通过 API 服务,AI 应用能够获取更多信息来源。这意味着:
+
+* Dify 平台能够直接获取托管在云服务提供商知识库内的文本内容,开发者无需将内容重复搬运至 Dify 中的知识库;
+* Dify 平台能够直接获取自建知识库内经算法处理后的文本内容,开发者仅需关注自建知识库的信息检索机制,并不断优化与提升信息召回的准确度。
+
+
+ 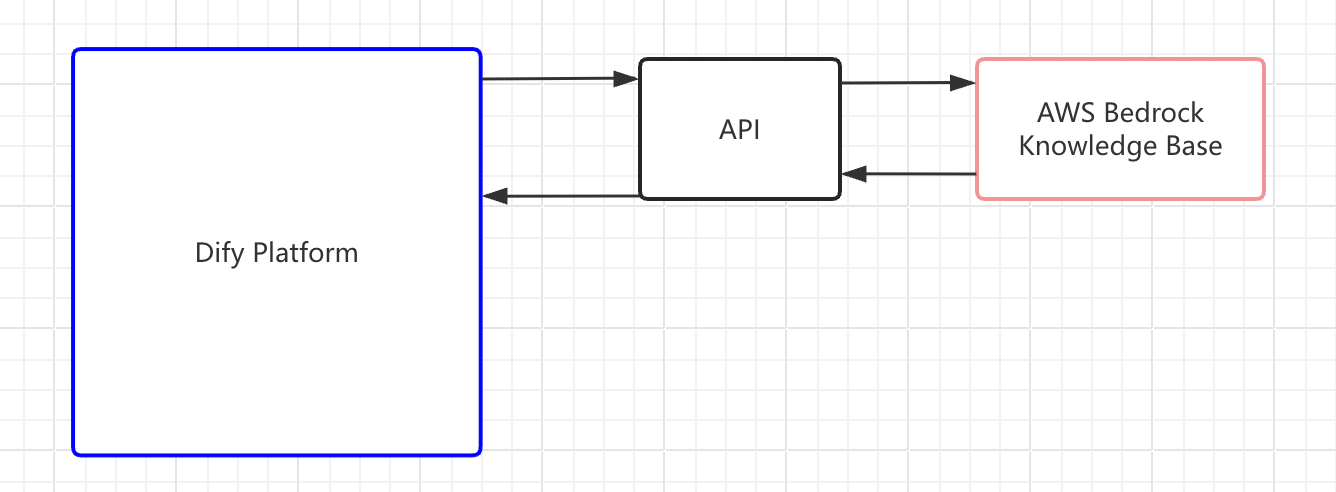 +
+
+以下是连接外部知识的详细步骤:
+
+
+
+
+以下是连接外部知识的详细步骤:
+
+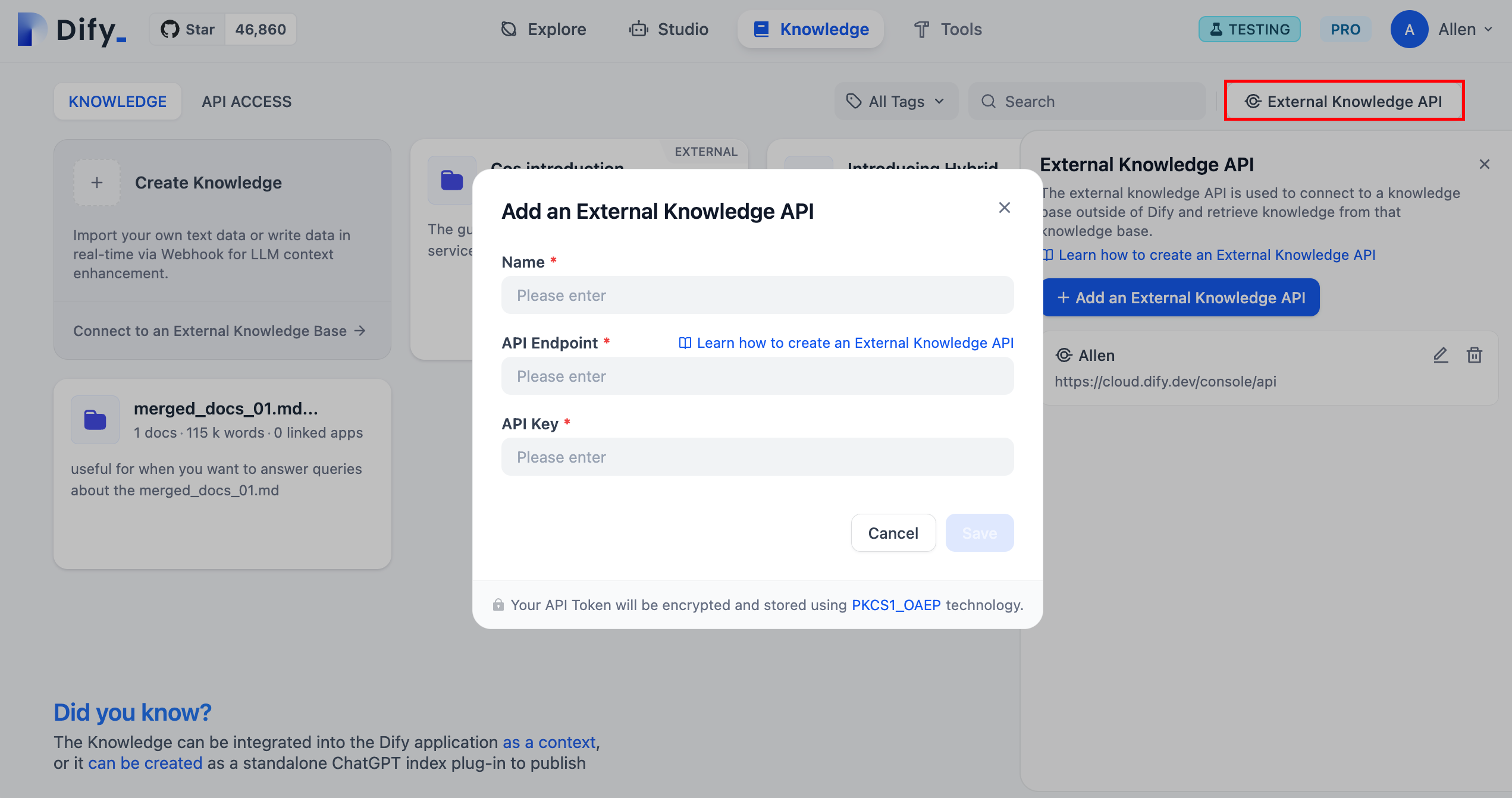 +
+
+
+ 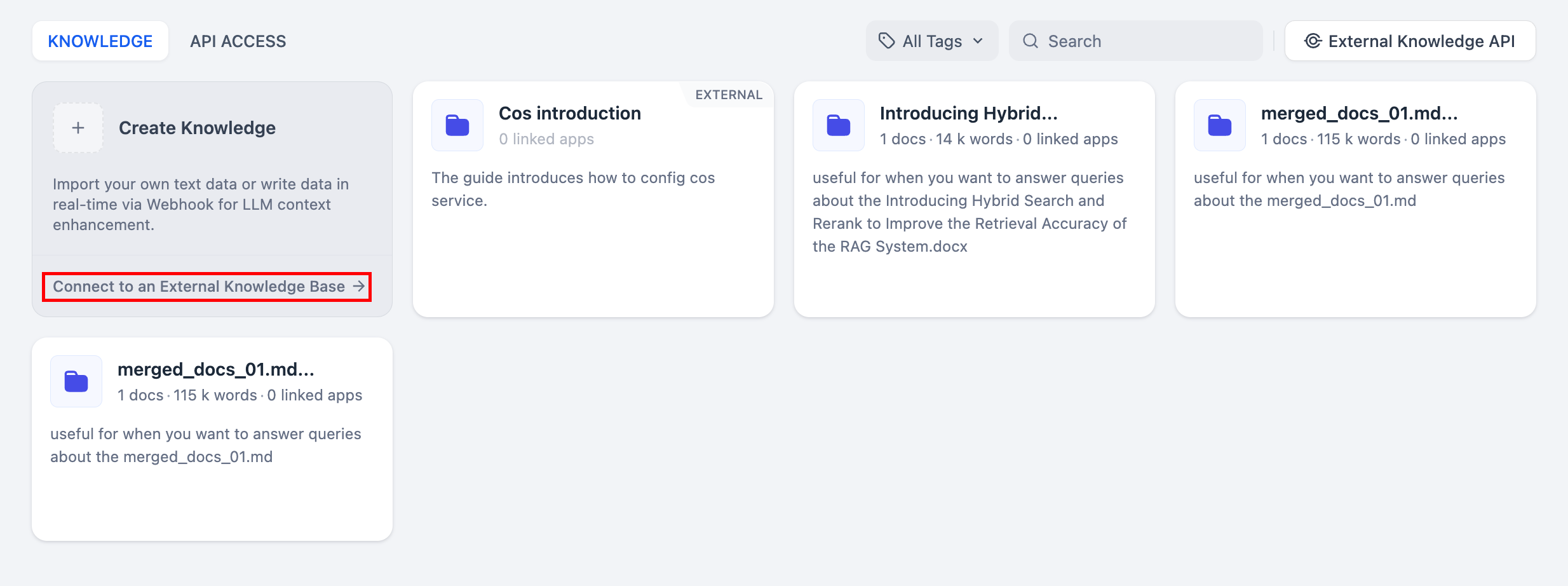 +
+
+ 填写以下参数:
+
+ * **知识库名称与描述**
+ * **外部知识库 API** 选择在第二步中关联的外部知识库 API;Dify 将通过 API 连接的方式,调用存储在外部知识库的文本内容;
+ * **外部知识库 ID** 指定需要被关联的特定的外部知识库 ID,详细说明请参考[外部知识库 API](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
+ * **调整召回设置**
+
+ **Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
+
+ **Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
+
+
+
+
+
+ 填写以下参数:
+
+ * **知识库名称与描述**
+ * **外部知识库 API** 选择在第二步中关联的外部知识库 API;Dify 将通过 API 连接的方式,调用存储在外部知识库的文本内容;
+ * **外部知识库 ID** 指定需要被关联的特定的外部知识库 ID,详细说明请参考[外部知识库 API](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
+ * **调整召回设置**
+
+ **Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
+
+ **Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
+
+
+ 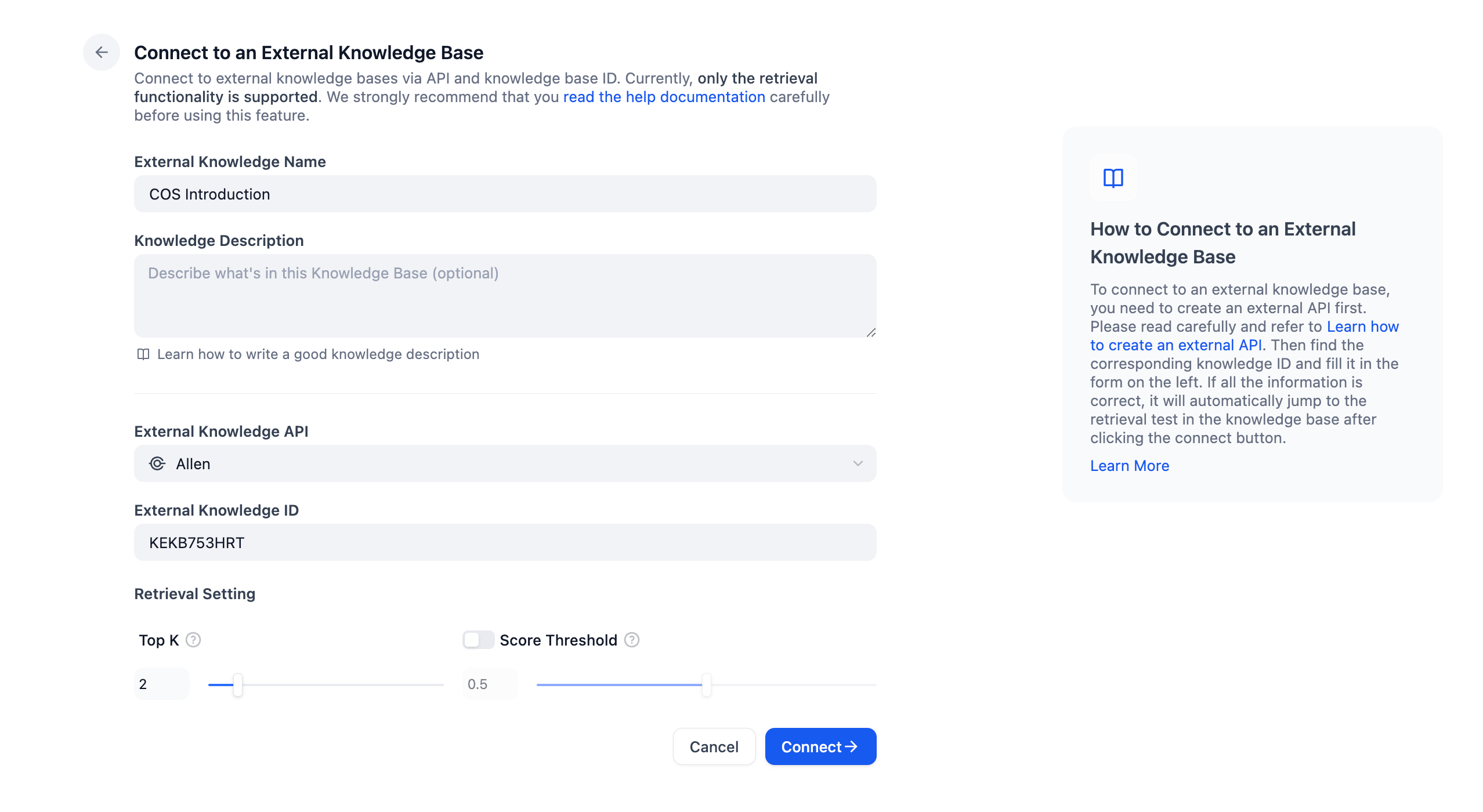 +
+
+
+
+
+ 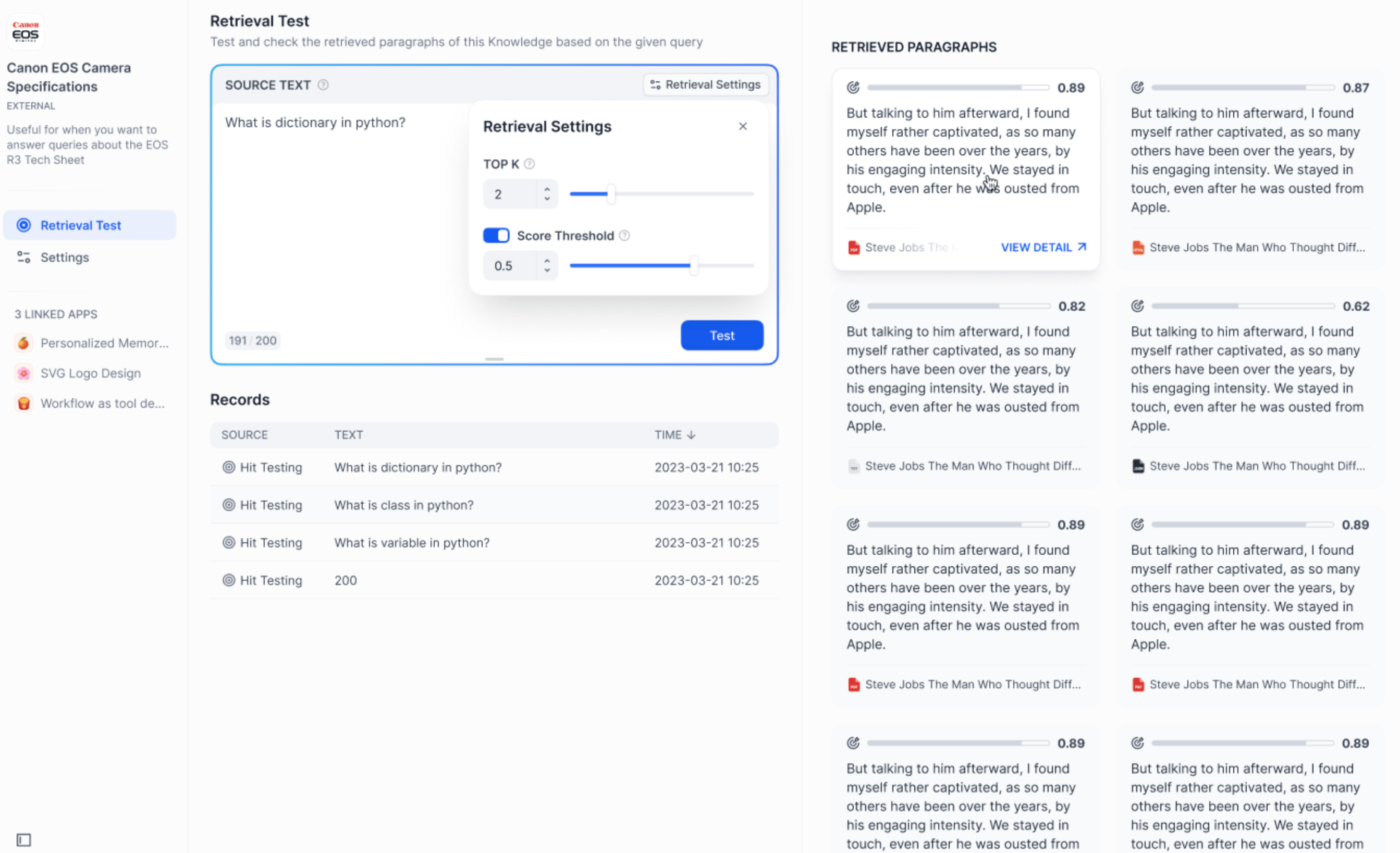 +
+
+
+ 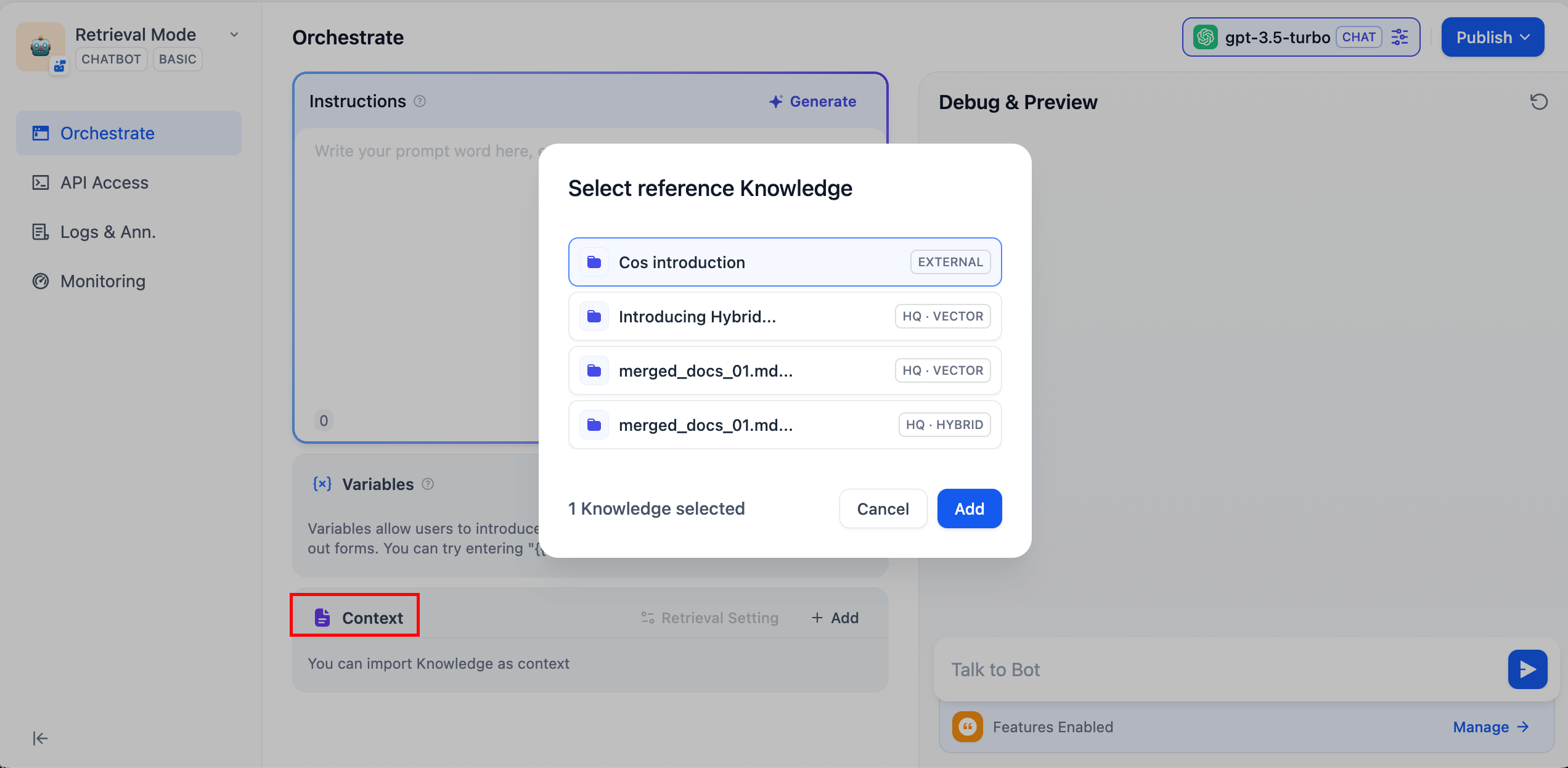 +
+
+ - **Chatflow / Workflow 类型应用**
+
+ 在 Chatflow / Workflow 类型应用内添加 **“知识检索”** 节点,选中带有 `EXTERNAL` 标签的外部知识库。
+
+
+
+
+
+ - **Chatflow / Workflow 类型应用**
+
+ 在 Chatflow / Workflow 类型应用内添加 **“知识检索”** 节点,选中带有 `EXTERNAL` 标签的外部知识库。
+
+
+ 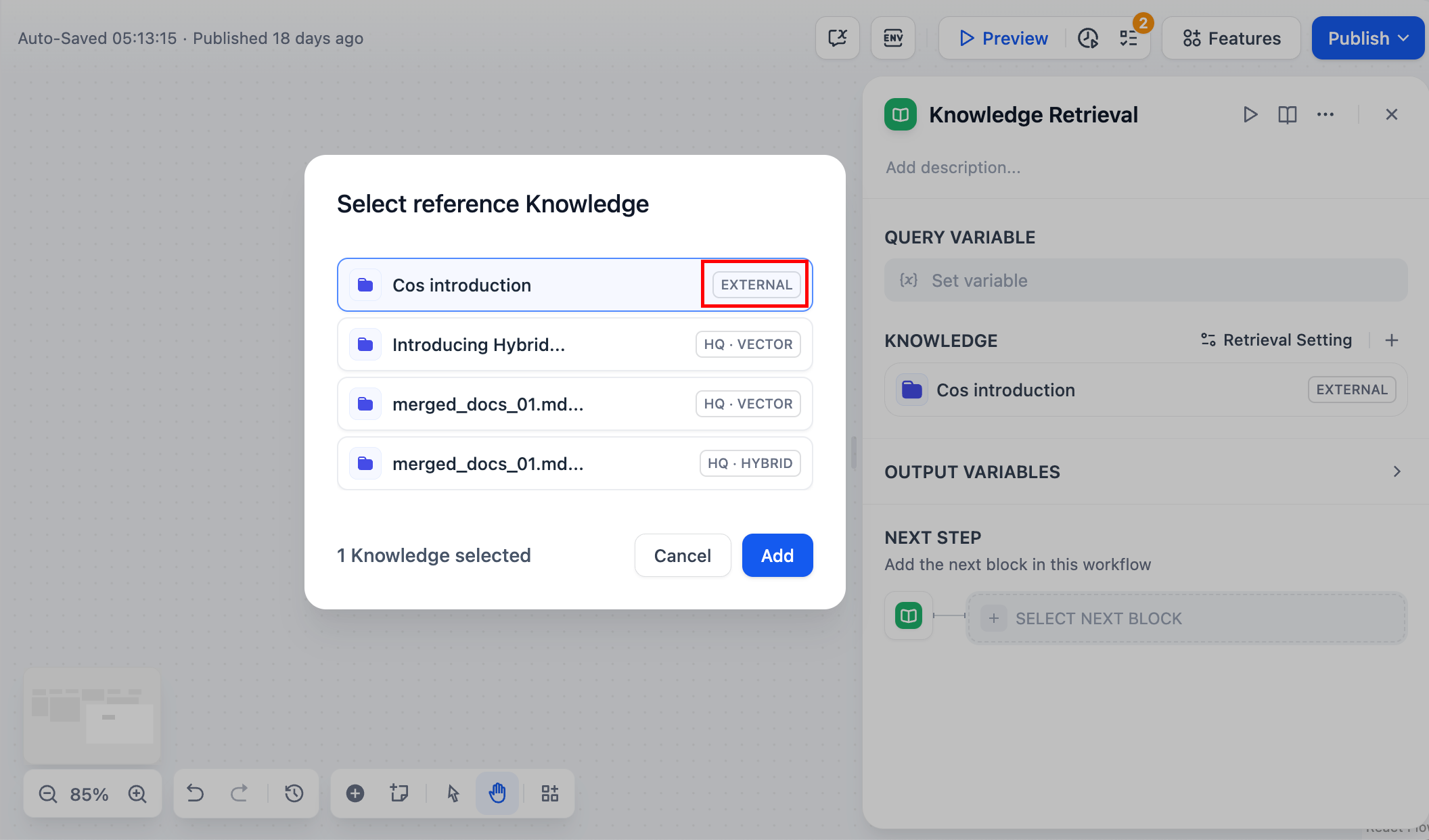
 +
+
+**可调参数**
+
+* **TopK**
+
+ 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
+* **Score 阈值**
+
+ 用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
+
+### 使用元数据筛选知识
+
+#### 聊天流/工作流
+
+在 **聊天流/工作流** 的 **知识检索** 节点中,你可以使用 **元数据筛选** 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。
+
+##### 配置步骤
+
+1. 选择筛选模式
+
+ - **禁用模式**(默认):禁用 **元数据筛选** 功能,不配置任何筛选条件。
+
+ - **自动模式**:系统会根据传输给该 **知识检索** 节点的 **查询变量** 自动配置筛选条件,适用于简单的筛选需求。
+
+ > 启用自动模式后,你依然需要在 **模型** 栏中选择合适的大模型以执行文档检索任务。
+
+ 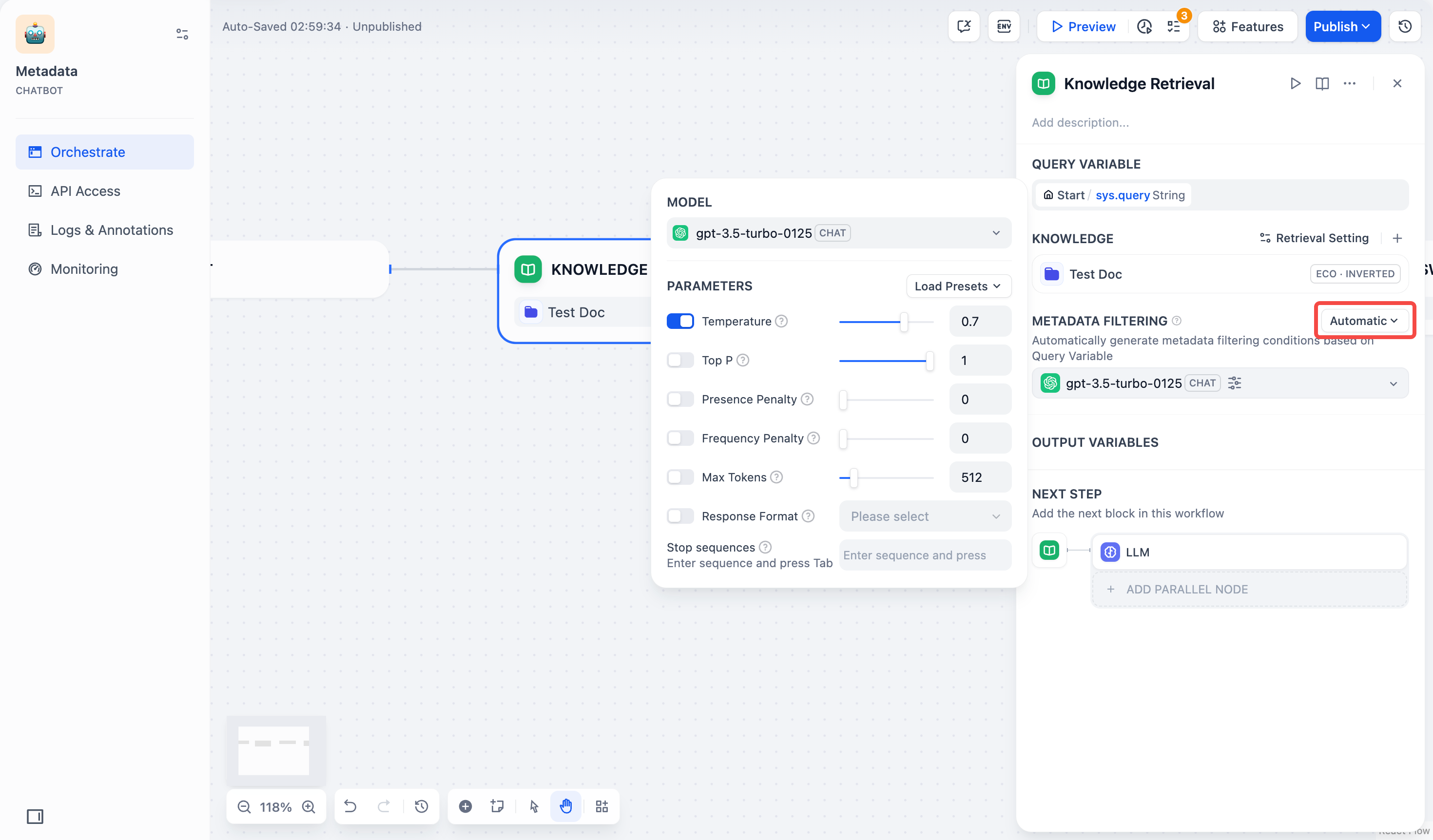
+
+ - **手动模式**:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
+
+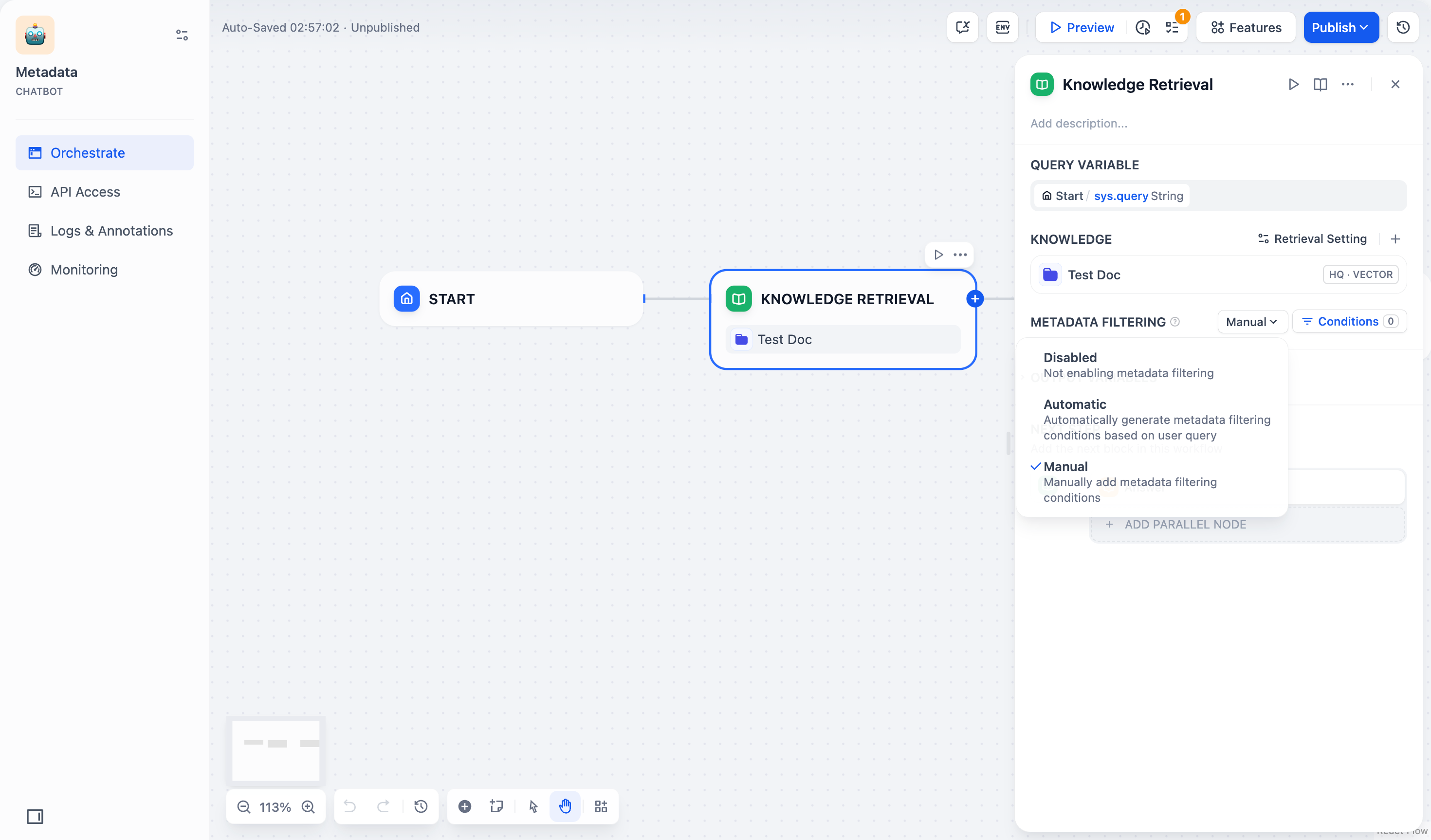
+
+2. 如果你选择了 **手动模式**,请参照以下步骤配置筛选条件:
+
+ 1. 点击 **条件** 按钮,弹出配置框。
+
+ 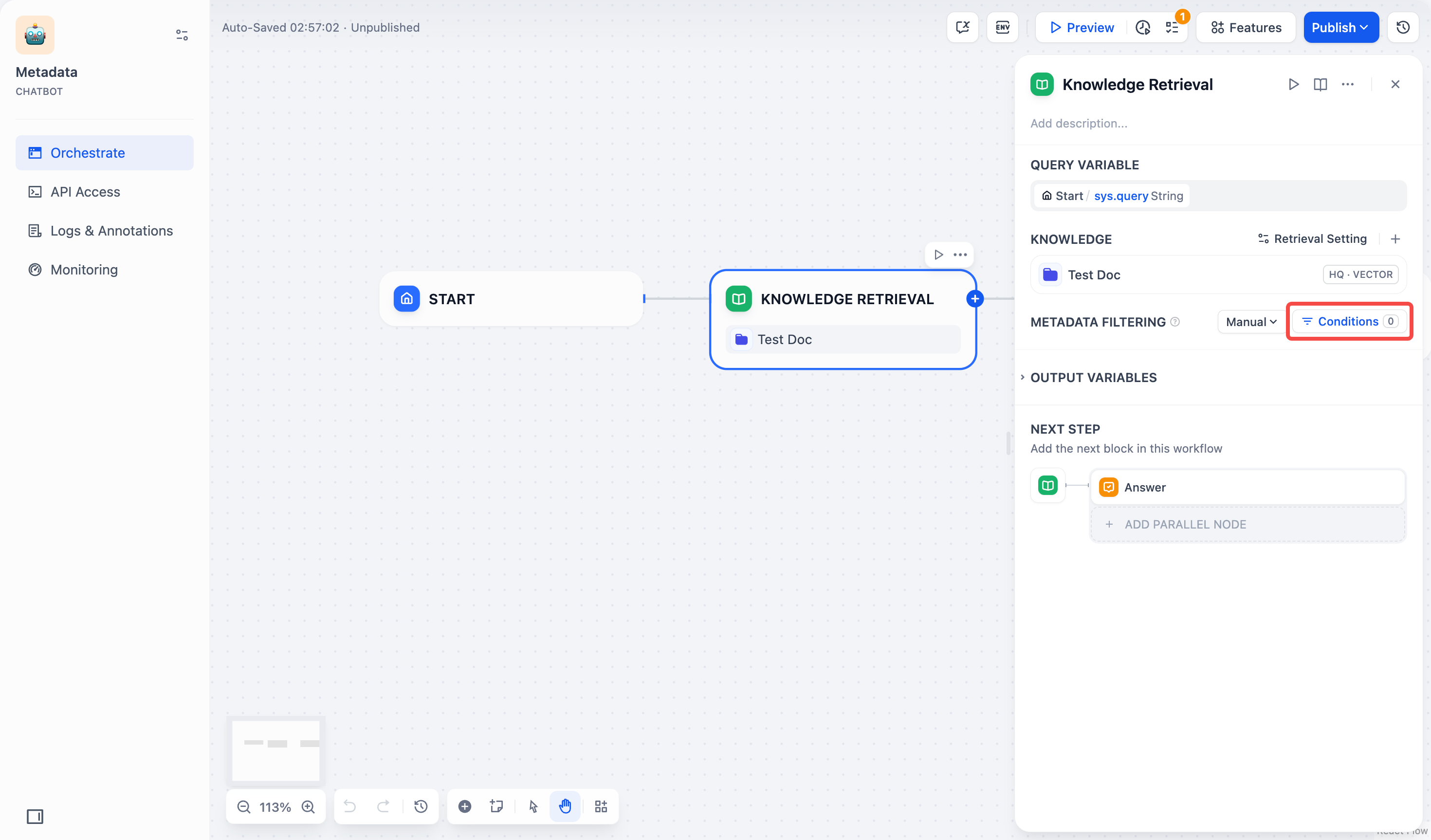
+
+ 2. 点击配置框中的 **+添加条件** 按钮:
+
+ - 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
+
+ > 如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
+
+ - 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到筛选条件列表中。
+
+ 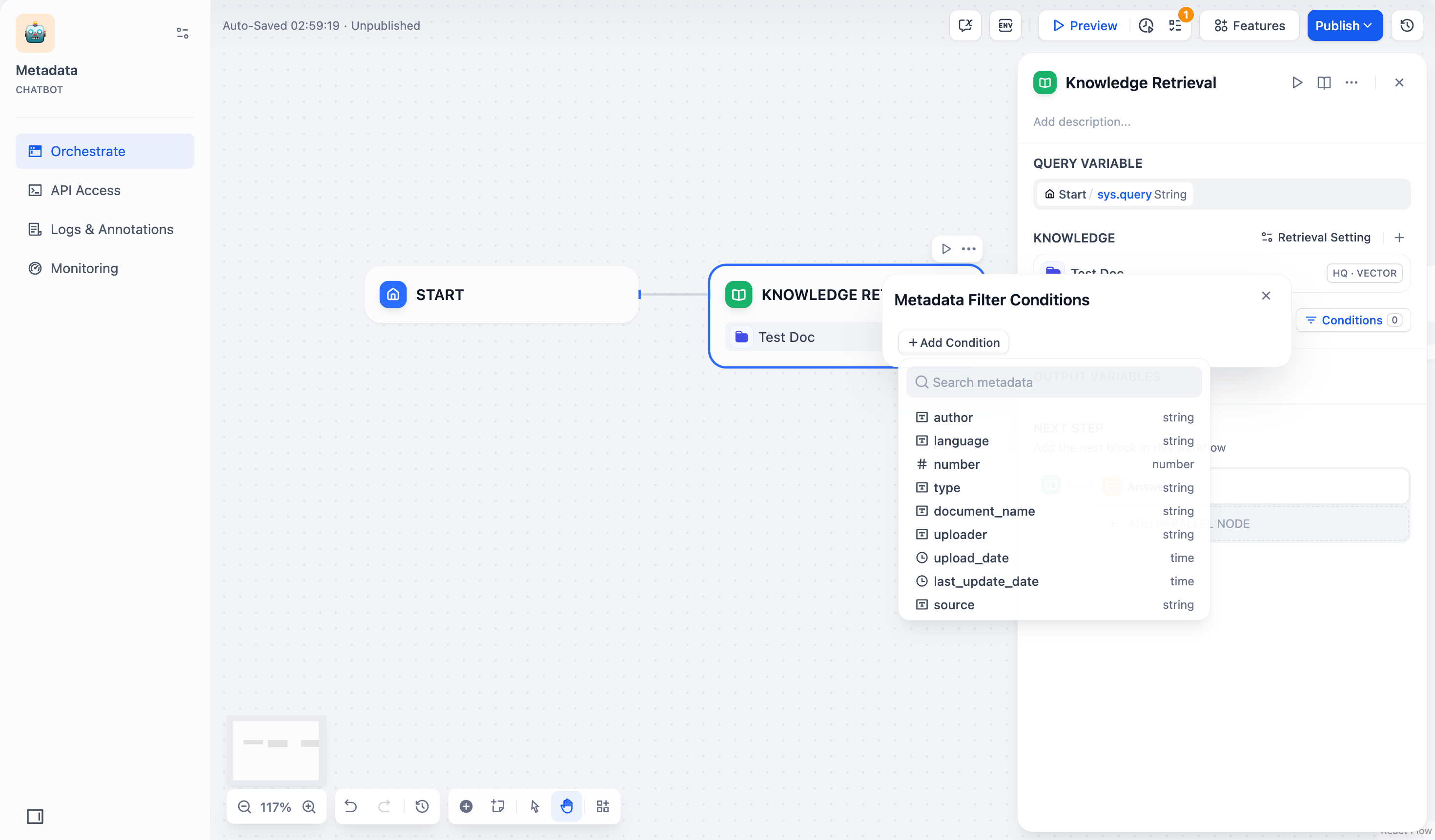
+
+ 3. 如果需要添加多条字段,可以重复点击 **+添加条件** 按钮。
+
+ 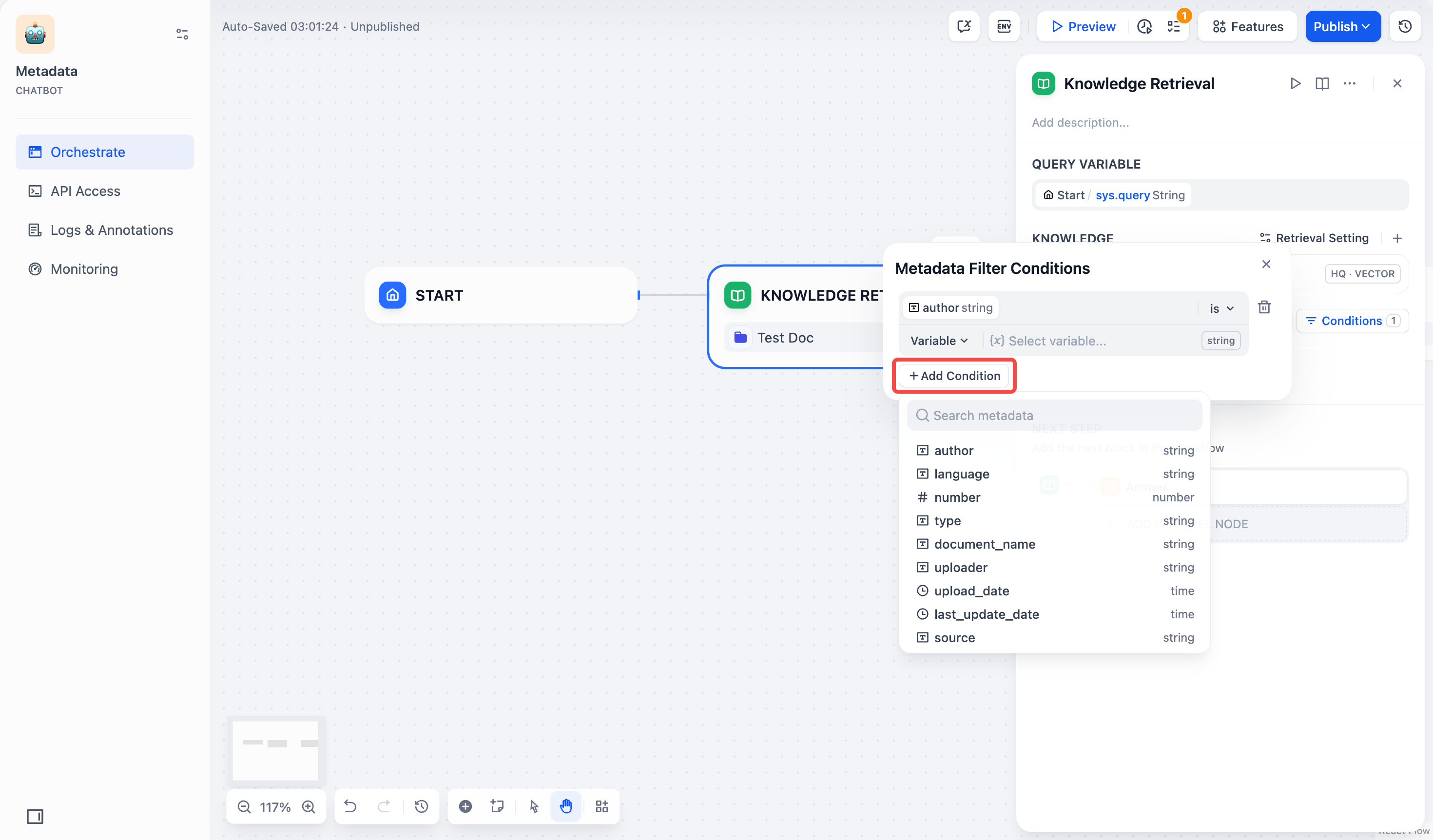
+
+ 4. 配置字段类型的筛选条件:
+
+ | 字段类型 | 筛选条件 | 筛选条件说明与示例 |
+ | --- | --- | --- |
+ | 字符串 | is | 字段的值必须与你输入的值完全匹配。例如,如果你设置筛选条件为 `is "Published"`,则只会返回标记为 "Published" 的文档。 |
+ | | is not | 字段的值不能与你输入的值匹配。例如,如果你设置筛选条件为 `is not "Draft"`,则会返回所有未标记为 "Draft" 的文档。 |
+ | | is empty | 字段的值为空。如果你配置了此条件,可以检索到未标记该字符串的文档。 |
+ | | is not empty | 字段的值不为空。如果你配置了此条件,可以检索到标记了该字符串的文档。 |
+ | | contains | 字段的值包含你输入的文本。例如,如果你设置筛选条件为 `contains "Report"`,则会返回所有包含"Report"的文档,如"Monthly Report" 或 "Annual Report"。 |
+ | | not contains | 字段的值不包含你输入的文本。例如,如果你设置筛选条件为 `not contains "Draft"`,则会返回所有不包含 "Draft" 的文档。 |
+ | | starts with | 字段的值以你输入的文本开头。例如,如果你设置筛选条件为 `starts with "Doc"`,则会返回所有以"Doc"开头的文档,如 "Doc1"、"Document"等。 |
+ | | ends with | 字段的值以你输入的文本结尾。例如,如果你设置筛选条件为 `ends with "2024"`,则会返回所有以"2024"结尾的文档,如"Report 2024"、"Summary 2024"等。 |
+ | 数字 | = | 字段的值必须等于你输入的数字。例如,`= 10` 会匹配所有数字标记为 10 的文档。 |
+ | | ≠ | 字段的值不能等于你输入的数字。例如,`≠ 5` 会返回所有数字未标记为 5 的文档。 |
+ | | > | 字段的值必须大于你输入的数字。例如,`100` 会返回所有数字标记为大于 100 的文档。 |
+ | | < | 字段的值必须小于你输入的数字。例如,`< 50` 会返回所有数字标记为小于 50 的文档。 |
+ | | ≥ | 字段的值必须大于或等于你输入的数字。例如,`≥ 20` 会返回所有数字标记为大于或等于 20 的文档。 |
+ | | ≤ | 字段的值必须小于或等于你输入的数字。例如,`≤ 200` 会返回所有数字标记为小于或等于 200 的文档。 |
+ | | is empty | 字段未设置值。例如,`is empty` 会返回所有该字段未标记数字的文档。 |
+ | | is not empty | 字段已设置值。例如,`is not empty` 会返回所有该字段已标记数字的文档。 |
+ | 时间 | is | 字段的时间值必须与你选择的时间完全匹配。例如,`is "2024-01-01"` 只会返回标记为 2024 年 1 月 1 日的文档。 |
+ | | before | 字段的时间值必须早于你选择的时间。例如,`before "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之前的文档。 |
+ | | after | 字段的时间值必须晚于你选择的时间。例如,`after "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之后的文档。 |
+ | | is empty | 字段的时间值为空。如果你配置了此条件,可以检索到未标记该时间信息的文档。 |
+ | | is not empty | 字段的时间值不为空。如果你配置了此条件,可以检索到标记了该时间信息的文档。 |
+
+ 5. 选择并添加元数据筛选值:
+ - **变量**:选择 **变量(Variable)**,并选择该**聊天流/工作流**中需要用于筛选文档的变量。
+
+ 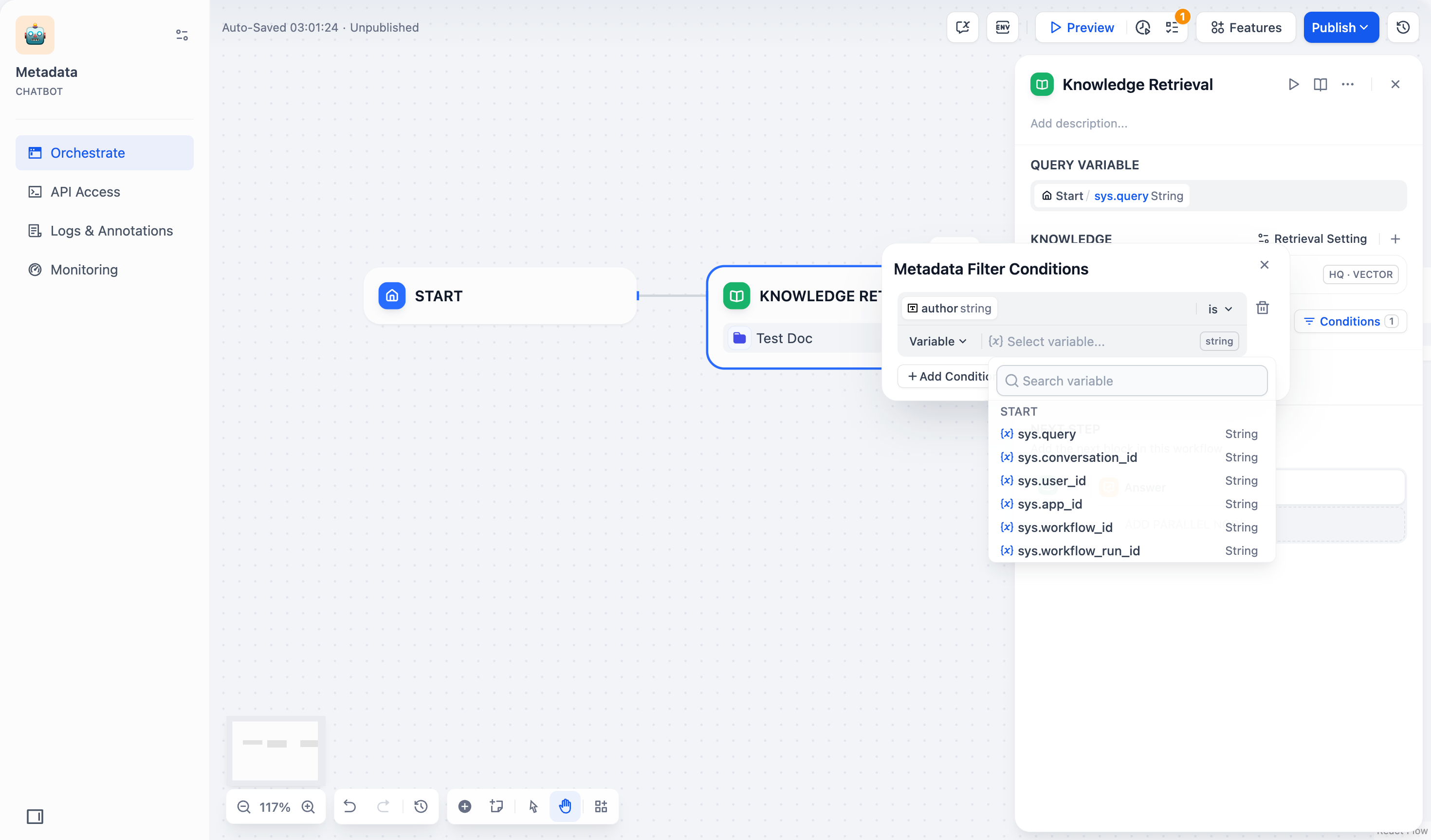
+
+ - **常量**:选择 **常量(Constant)**,并手动输入你需要的常量值。
+
+ > **时间** 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
+
+ 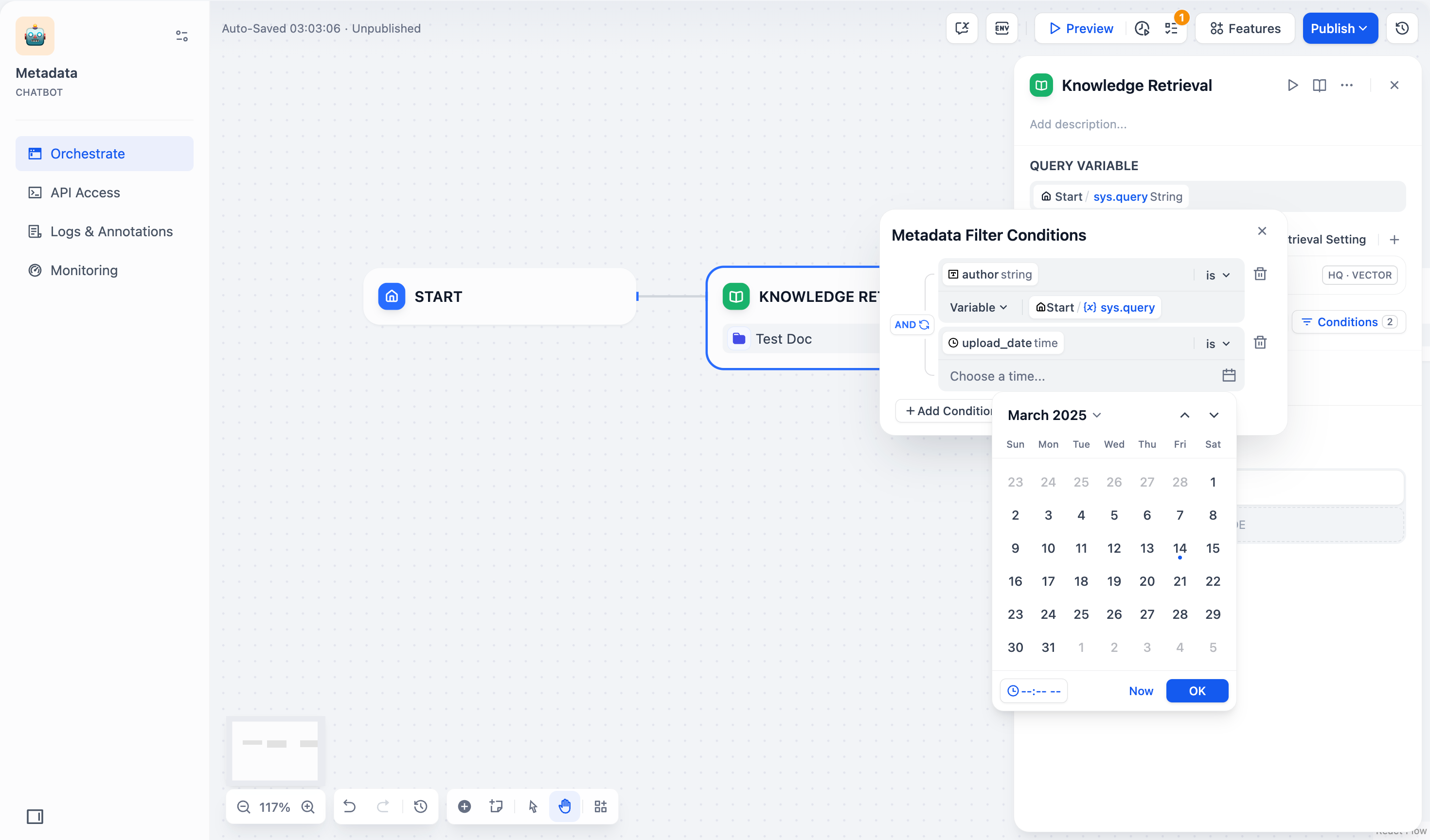
+
+
+
+
+**可调参数**
+
+* **TopK**
+
+ 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
+* **Score 阈值**
+
+ 用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
+
+### 使用元数据筛选知识
+
+#### 聊天流/工作流
+
+在 **聊天流/工作流** 的 **知识检索** 节点中,你可以使用 **元数据筛选** 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。
+
+##### 配置步骤
+
+1. 选择筛选模式
+
+ - **禁用模式**(默认):禁用 **元数据筛选** 功能,不配置任何筛选条件。
+
+ - **自动模式**:系统会根据传输给该 **知识检索** 节点的 **查询变量** 自动配置筛选条件,适用于简单的筛选需求。
+
+ > 启用自动模式后,你依然需要在 **模型** 栏中选择合适的大模型以执行文档检索任务。
+
+ 
+
+ - **手动模式**:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
+
+
+
+2. 如果你选择了 **手动模式**,请参照以下步骤配置筛选条件:
+
+ 1. 点击 **条件** 按钮,弹出配置框。
+
+ 
+
+ 2. 点击配置框中的 **+添加条件** 按钮:
+
+ - 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
+
+ > 如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
+
+ - 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到筛选条件列表中。
+
+ 
+
+ 3. 如果需要添加多条字段,可以重复点击 **+添加条件** 按钮。
+
+ 
+
+ 4. 配置字段类型的筛选条件:
+
+ | 字段类型 | 筛选条件 | 筛选条件说明与示例 |
+ | --- | --- | --- |
+ | 字符串 | is | 字段的值必须与你输入的值完全匹配。例如,如果你设置筛选条件为 `is "Published"`,则只会返回标记为 "Published" 的文档。 |
+ | | is not | 字段的值不能与你输入的值匹配。例如,如果你设置筛选条件为 `is not "Draft"`,则会返回所有未标记为 "Draft" 的文档。 |
+ | | is empty | 字段的值为空。如果你配置了此条件,可以检索到未标记该字符串的文档。 |
+ | | is not empty | 字段的值不为空。如果你配置了此条件,可以检索到标记了该字符串的文档。 |
+ | | contains | 字段的值包含你输入的文本。例如,如果你设置筛选条件为 `contains "Report"`,则会返回所有包含"Report"的文档,如"Monthly Report" 或 "Annual Report"。 |
+ | | not contains | 字段的值不包含你输入的文本。例如,如果你设置筛选条件为 `not contains "Draft"`,则会返回所有不包含 "Draft" 的文档。 |
+ | | starts with | 字段的值以你输入的文本开头。例如,如果你设置筛选条件为 `starts with "Doc"`,则会返回所有以"Doc"开头的文档,如 "Doc1"、"Document"等。 |
+ | | ends with | 字段的值以你输入的文本结尾。例如,如果你设置筛选条件为 `ends with "2024"`,则会返回所有以"2024"结尾的文档,如"Report 2024"、"Summary 2024"等。 |
+ | 数字 | = | 字段的值必须等于你输入的数字。例如,`= 10` 会匹配所有数字标记为 10 的文档。 |
+ | | ≠ | 字段的值不能等于你输入的数字。例如,`≠ 5` 会返回所有数字未标记为 5 的文档。 |
+ | | > | 字段的值必须大于你输入的数字。例如,`100` 会返回所有数字标记为大于 100 的文档。 |
+ | | < | 字段的值必须小于你输入的数字。例如,`< 50` 会返回所有数字标记为小于 50 的文档。 |
+ | | ≥ | 字段的值必须大于或等于你输入的数字。例如,`≥ 20` 会返回所有数字标记为大于或等于 20 的文档。 |
+ | | ≤ | 字段的值必须小于或等于你输入的数字。例如,`≤ 200` 会返回所有数字标记为小于或等于 200 的文档。 |
+ | | is empty | 字段未设置值。例如,`is empty` 会返回所有该字段未标记数字的文档。 |
+ | | is not empty | 字段已设置值。例如,`is not empty` 会返回所有该字段已标记数字的文档。 |
+ | 时间 | is | 字段的时间值必须与你选择的时间完全匹配。例如,`is "2024-01-01"` 只会返回标记为 2024 年 1 月 1 日的文档。 |
+ | | before | 字段的时间值必须早于你选择的时间。例如,`before "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之前的文档。 |
+ | | after | 字段的时间值必须晚于你选择的时间。例如,`after "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之后的文档。 |
+ | | is empty | 字段的时间值为空。如果你配置了此条件,可以检索到未标记该时间信息的文档。 |
+ | | is not empty | 字段的时间值不为空。如果你配置了此条件,可以检索到标记了该时间信息的文档。 |
+
+ 5. 选择并添加元数据筛选值:
+ - **变量**:选择 **变量(Variable)**,并选择该**聊天流/工作流**中需要用于筛选文档的变量。
+
+ 
+
+ - **常量**:选择 **常量(Constant)**,并手动输入你需要的常量值。
+
+ > **时间** 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
+
+ 
+
+
+
+---
+
+### 在线数据
+
+#### Notion
+
+将知识库连接 Notion 工作区,可直接导入 Notion 页面和数据库内容,支持后续的数据自动同步。
+
+
+ 
+
+
+ **配置选择**
+
+ | 配置项 | 说明 |
+ |--------|------|
+ | 文件格式 | 支持 pdf, xlxs, docs 等,用户可自定义选择 |
+ | 上传方式 | 通过拖拽或选择文件或文件夹上传本地文件,支持批量上传 |
+
+ **限制**
+
+ | 限制项 | 说明 |
+ |--------|------|
+ | 文件数量 | 每次最多上传 50 个文件 |
+ | 文件大小 | 每个文件大小不超过 15MB |
+ | 储存限制 | 不同 SaaS 版本的订阅计划对文档上传总数和向量存储空间有所限制 |
+
+ **输出变量**
+
+ | 输出变量 | 变量格式 |
+ |----------|----------|
+ | `{x} Document` | 单个文档 |
+
+
+
+
+### 网页爬虫
+
+将网页内容转化为大型语言模型容易识别的格式,知识库支持 Jina Reader 和 Firecrawl,提供灵活的网页解析能力。
+
+#### Jina Reader
+
+开源网页解析工具,提供简洁易用的 API 服务,适合快速抓取和处理网页内容。
+
+
+ 
+
+
+ **配置选项说明**
+
+ | 配置项 | 选项 | 输出变量 | 说明 |
+ |--------|------|----------|------|
+ | Extractor | 开启 | `{x} Content` | 输出结构化处理的页面信息 |
+ | | 关闭 | `{x} Document` | 输出页面的原始文本信息 |
+
+
+
+
+#### Firecrawl
+
+开源网页解析工具,提供更精细的爬取控制选项和 API 服务,支持复杂网站结构的深度爬取,适合需要批量处理和精确控制的场景。
+
+
+ 
+
+
+ **参数配置和说明**
+
+ | 参数 | 类型 | 说明 |
+ |------|------|------|
+ | URL | 必填 | 目标网页地址 |
+ | 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
+ | 使用站点地图 (Use sitemap) | 可选 | 利用网站地图进行爬取 |
+ | 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
+ | 启用内容提取器 (Enable Extractor) | 可选 | 选择数据提取方式 |
+
+
+
+
+### 在线网盘 (Online Drive)
+
+连接你的在线云储存服务(例如 Google Drive、Dropbox、OneDrive),Dify 将自动检索云储存中的文件,你可以勾选并导入相应文档进行下一步处理,无需手动下载文件再进行上传。
+
+
+ 
+
+
+ **参数配置和说明**
+
+ | 参数 | 类型 | 说明 |
+ |------|------|------|
+ | URL | 必填 | 目标网页地址 |
+ | 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
+ | 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
+ | 最大爬取深度 (Max depth) | 可选 | 控制爬取层级深度 |
+ | 排除路径 (Exclude paths) | 可选 | 设置不爬取的页面路径 |
+ | 仅包含路径 (Include only paths) | 可选 | 限制只爬取指定路径 |
+ | 启用内容提取器 (Enable Extractor) | 可选 | 选择数据处理方式 |
+ | 只提取主要内容 | 可选 | 过滤页面辅助信息 |
+
+
+
+
+#### Unstructured
+
+
+ 
+
+
+ MinerU 是一款高质量文档解析器,可将文档转换为机器可读格式(Markdown、JSON),专注于保留复杂结构和数学符号。
+
+ 与基础 PDF 提取器相比,MinerU 会移除页眉、页脚和页码,同时保持语义连贯性。它还能自动检测扫描 PDF 和乱码文档,支持 84 种语言的 OCR 功能。建议使用 MinerU 处理包含复杂公式的科学论文(自动转换为 LaTex)、多栏布局、包含混合内容(文本+图片+表格)的学术出版物文档。
+
+
+
+
+你可前往 [Dify Marketplace](https://marketplace.dify.ai) 探索更多工具。
+
+### 分块器 (Chunker)
+
+在构建 AI 应用时,我们需要处理大量和不同种类的文档内容,比如产品手册、技术文档或论文等。和人类有限的注意力相似,大型语言模型无法同时处理过多的信息。因此,在信息提取后,分块器将大段的文档内容拆分成更小、更易于管理的片段(称为"块")。这就好比一本很厚的书,被分成了许多章节,你可以通过阅读目录快速定位到相关内容所在章节。
+
+当 AI 应用需要回答问题时,良好的分块策略能够提供足够的上下文信息,并包含完整的语义。这样,当检索到对应的片段时,大型语言模型能够基于这个片段中的信息生成较为准确的答案。
+
+不同类型的文档需要不同的分块策略,比如产品手册可能需要按照产品型号进行分块,确保产品功能介绍的完整性;论文则需要根据逻辑结构进行分块,确保论点叙述的流畅性。基于这样的多样性,Dify 提供了 3 种分块器,帮助你根据不同文档类型和使用场景进行选择和使用。
+
+#### 分块器类型概述
+
+| 类型 | 特点 | 使用场景 |
+|------|------|----------|
+| 通用分块器 | 固定大小分块,支持自定义分隔符 | 结构简单的基础文档 |
+| 父子分块器 | 双层分段结构,平衡匹配精准度和上下文 | 需要较多上下文信息的复杂文档结构 |
+| 问答处理器 | 处理表格中的问答组合 | CSV 和 Excel 的结构化问答数据 |
+
+#### 通用文本预处理规则
+
+| 处理选项 | 说明 |
+|----------|------|
+| 替换连续空格、换行符和制表符 | 将文档中的连续空格、换行符和制表符替换为单个空格 |
+| 移除所有 URL 和邮箱地址 | 自动识别并移除文本中的网址链接和邮箱地址 |
+
+#### 通用分块器 (General Chunker)
+
+基础文档分块处理,适用于结构相对简单的文档,你可以参考下面的配置对文本的分块、文本预处理规则进行配置。
+
+**输入输出变量**
+
+| 类型 | 变量 | 说明 |
+|------|------|------|
+| 输入变量 | `{x} Content` | 完整的文档内容块,通用分块器将其拆分为若干小段 |
+| 输出变量 | `{x} Array[Chunk]` | 分块后的内容数组,每个片段适合进行检索和分析 |
+
+**分块设置 (Chunk Settings)**
+
+| 配置项 | 说明 |
+|--------|------|
+| 分段标识符 (Delimiter) | 默认值为 `\n`,即按照文本段落分段。你可以遵循正则表达式语法自定义分块规则,系统将在文本出现分段标识符时自动执行分段。 |
+| 分段最大长度 (Maximum Chunk Length) | 指定分段内的文本字符数最大上限,超出该长度时将强制分段。 |
+| 分段重叠长度 (Chunk Overlap) | 对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。 |
+
+#### 父子分块器 (Parent-child Chunker)
+
+父子分块器采用双层分段结构解决了上下文与准确度之间的矛盾,在检索增强生成(RAG)系统中实现了准确匹配与全面的上下文信息的平衡。
+
+**父子检索的工作机制**
+
+- **使用子分块匹配查询**:使用小而精准的信息片段(通常简洁到段落中的单个句子)来匹配用户查询。这些子分块能够实现精确且相关的初始检索。
+- **父分块提供丰富的上下文**:检索包含匹配子分块的更大范围内容(如段落、章节甚至整个文档)。这些父分块为大语言模型(LLM)提供全面的上下文信息。
+
+**输入输出变量**
+
+| 类型 | 变量 | 说明 |
+|------|------|------|
+| 输入变量 | `{x} Content` | 完整的文档内容块,通用分块器将其拆分为若干小段 |
+| 输出变量 | `{x} Array[ParentChunk]` | 父分块数组 |
+
+**分块设置 (Chunk Settings)**
+
+| 配置项 | 说明 |
+|--------|------|
+| 父分块分隔符 (Parent Delimiter) | 设置父分块的分割标识符 |
+| 父分块最大长度 (Parent Maximum Chunk Length) | 控制父分块的最大字符数 |
+| 子分块分隔符 (Child Delimiter) | 设置子分块的分割标识符 |
+| 子分块最大长度 (Child Maximum Chunk Length) | 控制子分块的最大字符数 |
+| 父块模式 (Parent Mode) | 选择"段落"(将文本分割为段落)或"完整文档"(使用整个文档作为父分块)进行直接检索 |
+
+#### 问答处理器 Q&A Processor (Extractor+Chunker)
+
+问答处理器结合了提取和分块功能,专门用于处理 CSV 和 Excel 文件的结构化问答数据集,比如常见问题(FAQ)列表、排班表等。
+
+**输入输出变量**
+
+| 类型 | 变量 | 说明 |
+|------|------|------|
+| 输入变量 | `{x} Document` | 单个文档 |
+| 输出变量 | `{x} Array[QAChunk]` | 问答分块数组 |
+
+**变量配置**
+
+| 名称 | 说明 |
+|------|------|
+| 问题所在的列 | 将内容所在的列设置为问题 |
+| 答案所在的列 | 将内容所在的列设置为答案 |
+
+## 步骤三:配置知识库节点
+
+在完成数据处理后,我们将进入知识流水线的最后一个环节 — 知识库节点。你可以根据实际需求,在这个节点选择不同的索引方法和检索策略,以获得最适合的检索效果和成本控制。
+
+知识库节点配置分为以下部分:输入变量、分段结构、索引方式以及检索设置。
+
+### 分段结构 (Chunk Structure)
+
+
+
+分段结构决定了知识库如何组织和索引你的文档内容。你可以根据文档类型、使用场景和成本考虑来选择最适合的结构模式。
+
+知识库支持两种分段模式:通用模式与父子模式。如果你是首次创建知识库,建议选择父子模式。
+
+
+ 
+
+
+ Unstructured 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
+
+ 经济 | Embedding 嵌入模型
关键词数量 | 向量检索
全文检索
混合检索
倒排索引 | +| 父子模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索
全文检索
混合检索 | +| 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索
全文检索
混合检索 | + +## 步骤四:配置用户输入表单 + +用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[开始节点](/zh/use-dify/nodes/start),这个表单从用户那里收集必要的相信信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。 + +通过这种方式,你可以为不同的使用场景创建特定的的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。 + +### 创建用户输入表单 + +你可以通过下面两种方式,创建用户输入表单。 + +1. **知识流水线编排界面** + 点击输入字段(Input Field)开始创建和配置输入表单。 + +  + +2. **节点参数面板** + 选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。 + +  + +### 输入类型 + +#### 非共享输入 (Unique Inputs for Each Entrance) + + + +这类输入适用于每个数据源及其下游节点,用户只需在选择对应数据源时填写这些字段,比如不同数据源的URL。 + +在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。 + + + +#### 全局共享输入 (Global Inputs for All Entrance) + + + +全局共享输入可以被所有节点引用。这类输入适用于通用处理参数,比如分隔符、最大分块长度、文档处理配置等。无论用户选择哪个数据源,都需要填写这些字段。 + +在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。 + +### 支持字段类型和填写说明 + +知识流水线支持以下七种类型的输入变量。 +
+
+
+
+ 
+
+
+ | 字段类型 | 说明 |
+ |----------|------|
+ | 文本 | 短文本,由知识库使用者自行填写,最大长度为 256 字符 |
+ | 段落 | 长文本,知识库使用者可以输入较长字符 |
+ | 下拉选项 | 由编排者预设的固定选项供使用者选择,使用者无法自行填写内容 |
+ | 布尔值 | 只有真/假两个取值 |
+ | 数字 | 只能输入数字 |
+ | 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
+ | 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
+
+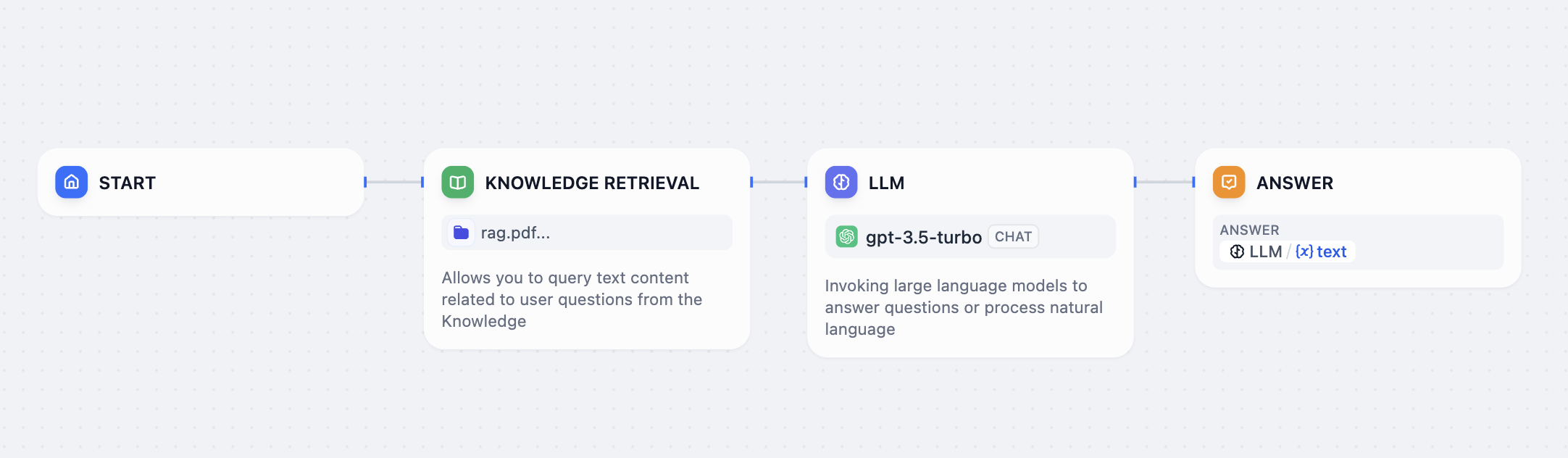 +
+
+
+
+
+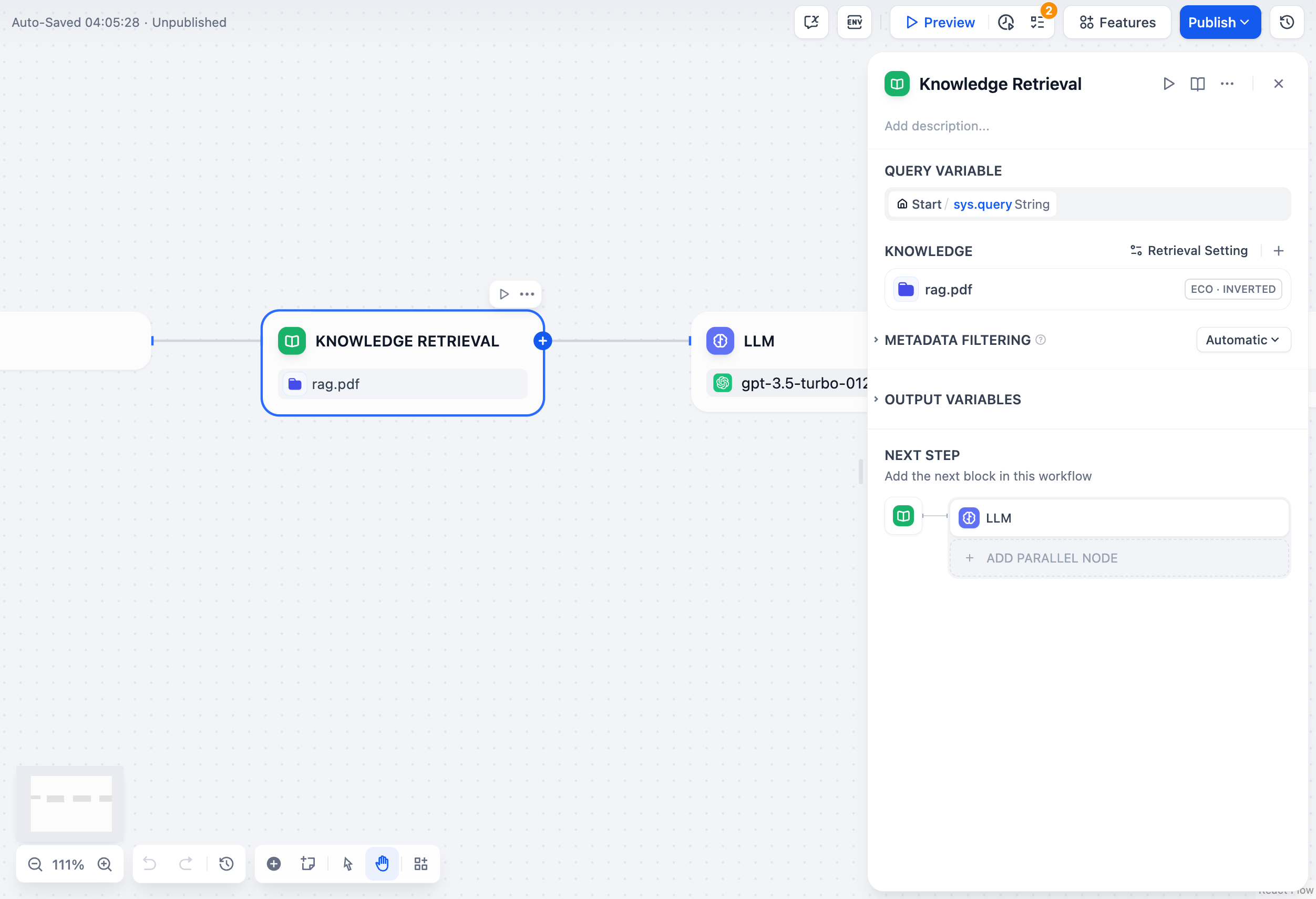 +
+
+### 检索参数
+
+**TopK**控制要检索的文档块数量。从3-5个块开始以获得聚焦结果,或使用10-15个块以获得全面覆盖。
+
+**分数阈值**设置最小相似度分数。更高的阈值(0.7+)确保相关性,较低的阈值(0.5-)包含更多相关的内容。
+
+**重排序**在初始检索后重新评分结果。对于混合检索、大量块,或当精度比速度更重要时启用。
+
+### 元数据筛选
+
+使用文档元数据(如类型、日期或部门)筛选结果。上传文档时设置元数据,以在大型知识库中启用有针对性的搜索。
+
+### 多知识库策略
+
+**N对1召回**使用函数调用来分析查询、选择适当的知识库并优化搜索。最适用于不同领域的专业知识库。
+
+**多路召回**同时查询所有选定的知识库并合并结果。当信息跨越多个来源或你需要全面覆盖时使用。
+
+
+
+
+
+### 检索参数
+
+**TopK**控制要检索的文档块数量。从3-5个块开始以获得聚焦结果,或使用10-15个块以获得全面覆盖。
+
+**分数阈值**设置最小相似度分数。更高的阈值(0.7+)确保相关性,较低的阈值(0.5-)包含更多相关的内容。
+
+**重排序**在初始检索后重新评分结果。对于混合检索、大量块,或当精度比速度更重要时启用。
+
+### 元数据筛选
+
+使用文档元数据(如类型、日期或部门)筛选结果。上传文档时设置元数据,以在大型知识库中启用有针对性的搜索。
+
+### 多知识库策略
+
+**N对1召回**使用函数调用来分析查询、选择适当的知识库并优化搜索。最适用于不同领域的专业知识库。
+
+**多路召回**同时查询所有选定的知识库并合并结果。当信息跨越多个来源或你需要全面覆盖时使用。
+
+
+ 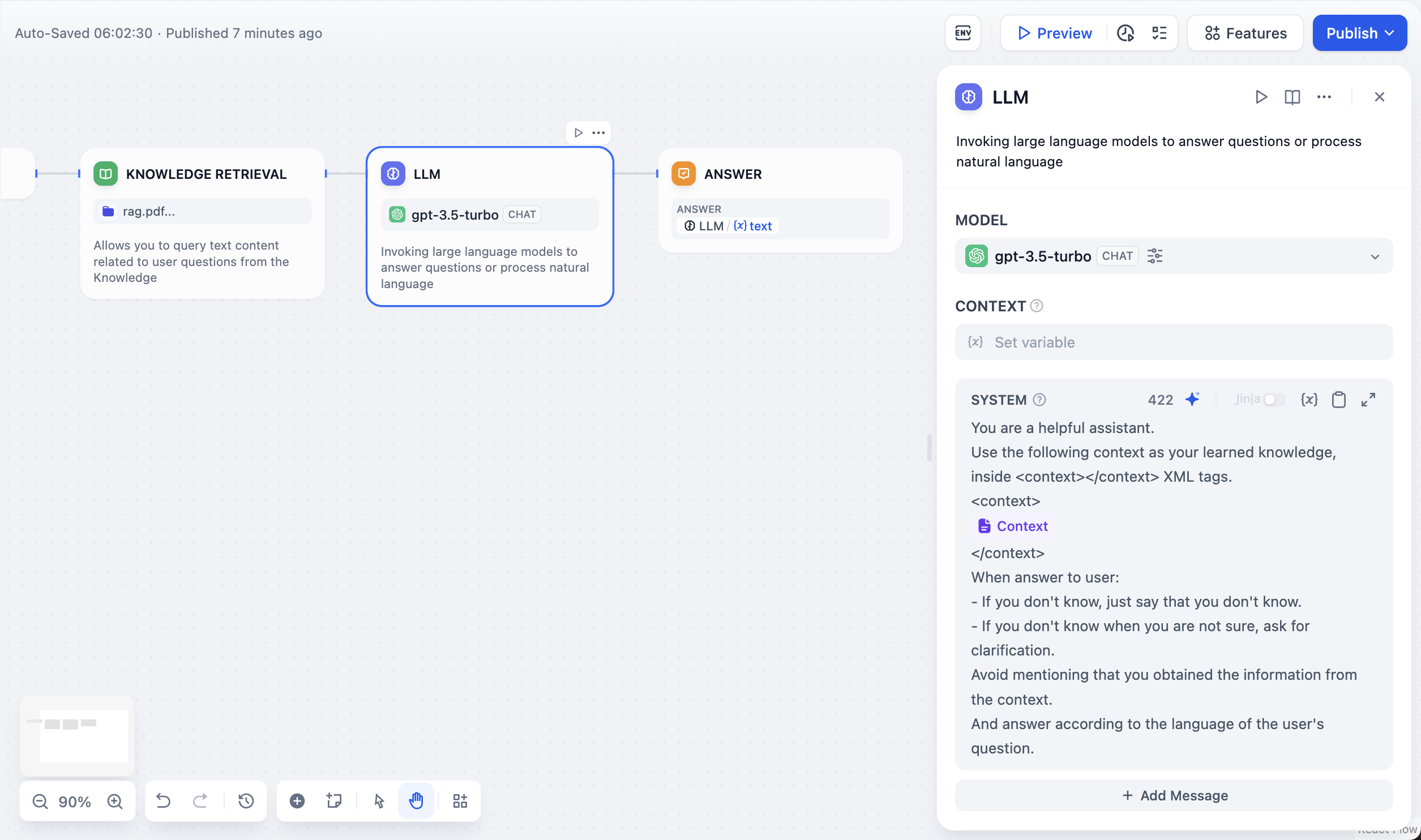 +
+
+## 输出和集成
+
+该节点输出包含文本内容和元数据(来源、分数、文档ID)的检索文档块数组。这种结构化输出保留了引用所需的信息。
+
+### RAG集成
+
+将知识检索输出连接到大型语言模型节点上下文输入,用于RAG应用。当使用检索结果作为上下文变量时,Dify会自动跟踪来源并启用引用功能。
+
+```text
+System: 根据提供的上下文回答。
+Context: {{knowledge_retrieval.result}}
+User: {{user_question}}
+```
+
+### 速率限制
+
+知识检索操作受到基于你订统使用Redis以60秒滑动窗口跟踪请求。当超出限制时,会返回`RateLimitExceeded`错误。
+
+### 性能考虑
+
+检索质量取决于索引实践。较小的块(200-500个标记)能够实现精确检索,较大的块(800-1500个标记)保持上下文。知识库有速率限制——该节点处理限制并自动缓存相同的查询。
diff --git a/zh/use-dify/pages/nodes/llm.mdx b/zh/use-dify/pages/nodes/llm.mdx
new file mode 100644
index 000000000..8d7883e68
--- /dev/null
+++ b/zh/use-dify/pages/nodes/llm.mdx
@@ -0,0 +1,136 @@
+---
+title: "大语言模型"
+icon: "brain"
+---
+
+
+
+
+## 输出和集成
+
+该节点输出包含文本内容和元数据(来源、分数、文档ID)的检索文档块数组。这种结构化输出保留了引用所需的信息。
+
+### RAG集成
+
+将知识检索输出连接到大型语言模型节点上下文输入,用于RAG应用。当使用检索结果作为上下文变量时,Dify会自动跟踪来源并启用引用功能。
+
+```text
+System: 根据提供的上下文回答。
+Context: {{knowledge_retrieval.result}}
+User: {{user_question}}
+```
+
+### 速率限制
+
+知识检索操作受到基于你订统使用Redis以60秒滑动窗口跟踪请求。当超出限制时,会返回`RateLimitExceeded`错误。
+
+### 性能考虑
+
+检索质量取决于索引实践。较小的块(200-500个标记)能够实现精确检索,较大的块(800-1500个标记)保持上下文。知识库有速率限制——该节点处理限制并自动缓存相同的查询。
diff --git a/zh/use-dify/pages/nodes/llm.mdx b/zh/use-dify/pages/nodes/llm.mdx
new file mode 100644
index 000000000..8d7883e68
--- /dev/null
+++ b/zh/use-dify/pages/nodes/llm.mdx
@@ -0,0 +1,136 @@
+---
+title: "大语言模型"
+icon: "brain"
+---
+
+ +
+
+
+
+
+模型参数控制响应生成。**温度**范围从 0(确定性)到 1(创造性)。**核采样**通过概率限制词汇选择。**频率惩罚**减少重复。**存在惩罚**鼓励新话题。你也可以使用预设:**精确**、**平衡**或**创意**。
+
+## 提示词配置
+
+你的界面根据模型类型自适应。聊天模型使用消息角色(**系统**用于行为,**用户**用于输入,**助手**用于示例),而完成模型使用简单的文本续写。
+
+在提示词中使用双花括号引用工作流变量:`{{variable_name}}`。变量在到达模型之前会被实际值替换。
+
+```text
+System: You are a technical documentation expert.
+User: {{user_input}}
+```
+
+## 上下文变量
+
+上下文变量在保持来源归属的同时注入外部知识。这使得大型语言模型可以使用你的特定文档回答问题的检索增强生成应用成为可能。
+
+
+
+
+
+将知识检索节点的输出连接到你的大型语言模型节点的上下文输入,然后引用它:
+
+```text
+Answer using only this context:
+{{knowledge_retrieval.result}}
+
+Question: {{user_question}}
+```
+
+当使用来自知识检索的上下文变量时,Dify 会自动跟踪引用与归属,以便用户看到信息来源。
+
+## 结构化输出
+
+强制模型返回特定数据格式(如 JSON)以便程序化使用。通过三种方法配置:
+
+
+
+
+对于完成模型中的对话历史,插入对话变量以维护多轮对话上下文:
+
+
+
+
+
+## Jinja2 模板支持
+
+大型语言模型提示词支持 Jinja2 模板以进行高级变量处理。当你使用 Jinja2 模式(`edition_type: "jinja2"`)时,你可以:
+
+```jinja2
+{% for item in search_results %}
+{{ loop.index }}. {{ item.title }}: {{ item.content }}
+{% endfor %}
+```
+
+Jinja2 变量与常规变量替换分别处理,允许在提示词中进行循环、条件和复杂数据转换。
+
+## 流式结果返回
+
+大型语言模型节点默认支持流式结果返回。每个文本块都作为 `RunStreamChunkEvent` 产生,实现实时响应显示。文件输出(图像、文档)在流式传输期间自动处理和保存。
+
+## 错误处理
+
+为失败的大型语言模型调用配置重试行为。设置最大重试次数、重试间隔和退避乘数。当重试不足时,定义回退策略,如默认值、错误路由或替代模型。
diff --git a/zh/use-dify/pages/nodes/tools.mdx b/zh/use-dify/pages/nodes/tools.mdx
new file mode 100644
index 000000000..c04be74da
--- /dev/null
+++ b/zh/use-dify/pages/nodes/tools.mdx
@@ -0,0 +1,91 @@
+---
+title: "工具"
+icon: "wrench"
+---
+
+
+
+
+
+
+
+模型参数控制响应生成。**温度**范围从 0(确定性)到 1(创造性)。**核采样**通过概率限制词汇选择。**频率惩罚**减少重复。**存在惩罚**鼓励新话题。你也可以使用预设:**精确**、**平衡**或**创意**。
+
+## 提示词配置
+
+你的界面根据模型类型自适应。聊天模型使用消息角色(**系统**用于行为,**用户**用于输入,**助手**用于示例),而完成模型使用简单的文本续写。
+
+在提示词中使用双花括号引用工作流变量:`{{variable_name}}`。变量在到达模型之前会被实际值替换。
+
+```text
+System: You are a technical documentation expert.
+User: {{user_input}}
+```
+
+## 上下文变量
+
+上下文变量在保持来源归属的同时注入外部知识。这使得大型语言模型可以使用你的特定文档回答问题的检索增强生成应用成为可能。
+
+
+
+
+
+将知识检索节点的输出连接到你的大型语言模型节点的上下文输入,然后引用它:
+
+```text
+Answer using only this context:
+{{knowledge_retrieval.result}}
+
+Question: {{user_question}}
+```
+
+当使用来自知识检索的上下文变量时,Dify 会自动跟踪引用与归属,以便用户看到信息来源。
+
+## 结构化输出
+
+强制模型返回特定数据格式(如 JSON)以便程序化使用。通过三种方法配置:
+
+
+
+
+对于完成模型中的对话历史,插入对话变量以维护多轮对话上下文:
+
+
+
+
+
+## Jinja2 模板支持
+
+大型语言模型提示词支持 Jinja2 模板以进行高级变量处理。当你使用 Jinja2 模式(`edition_type: "jinja2"`)时,你可以:
+
+```jinja2
+{% for item in search_results %}
+{{ loop.index }}. {{ item.title }}: {{ item.content }}
+{% endfor %}
+```
+
+Jinja2 变量与常规变量替换分别处理,允许在提示词中进行循环、条件和复杂数据转换。
+
+## 流式结果返回
+
+大型语言模型节点默认支持流式结果返回。每个文本块都作为 `RunStreamChunkEvent` 产生,实现实时响应显示。文件输出(图像、文档)在流式传输期间自动处理和保存。
+
+## 错误处理
+
+为失败的大型语言模型调用配置重试行为。设置最大重试次数、重试间隔和退避乘数。当重试不足时,定义回退策略,如默认值、错误路由或替代模型。
diff --git a/zh/use-dify/pages/nodes/tools.mdx b/zh/use-dify/pages/nodes/tools.mdx
new file mode 100644
index 000000000..c04be74da
--- /dev/null
+++ b/zh/use-dify/pages/nodes/tools.mdx
@@ -0,0 +1,91 @@
+---
+title: "工具"
+icon: "wrench"
+---
+
+ +
+
+## 工具类型
+
+Dify支持多种类型的工具来处理不同的集成需求:
+
+
+
+
+
+## 工具类型
+
+Dify支持多种类型的工具来处理不同的集成需求:
+
+
+  +
+
+
+
+
+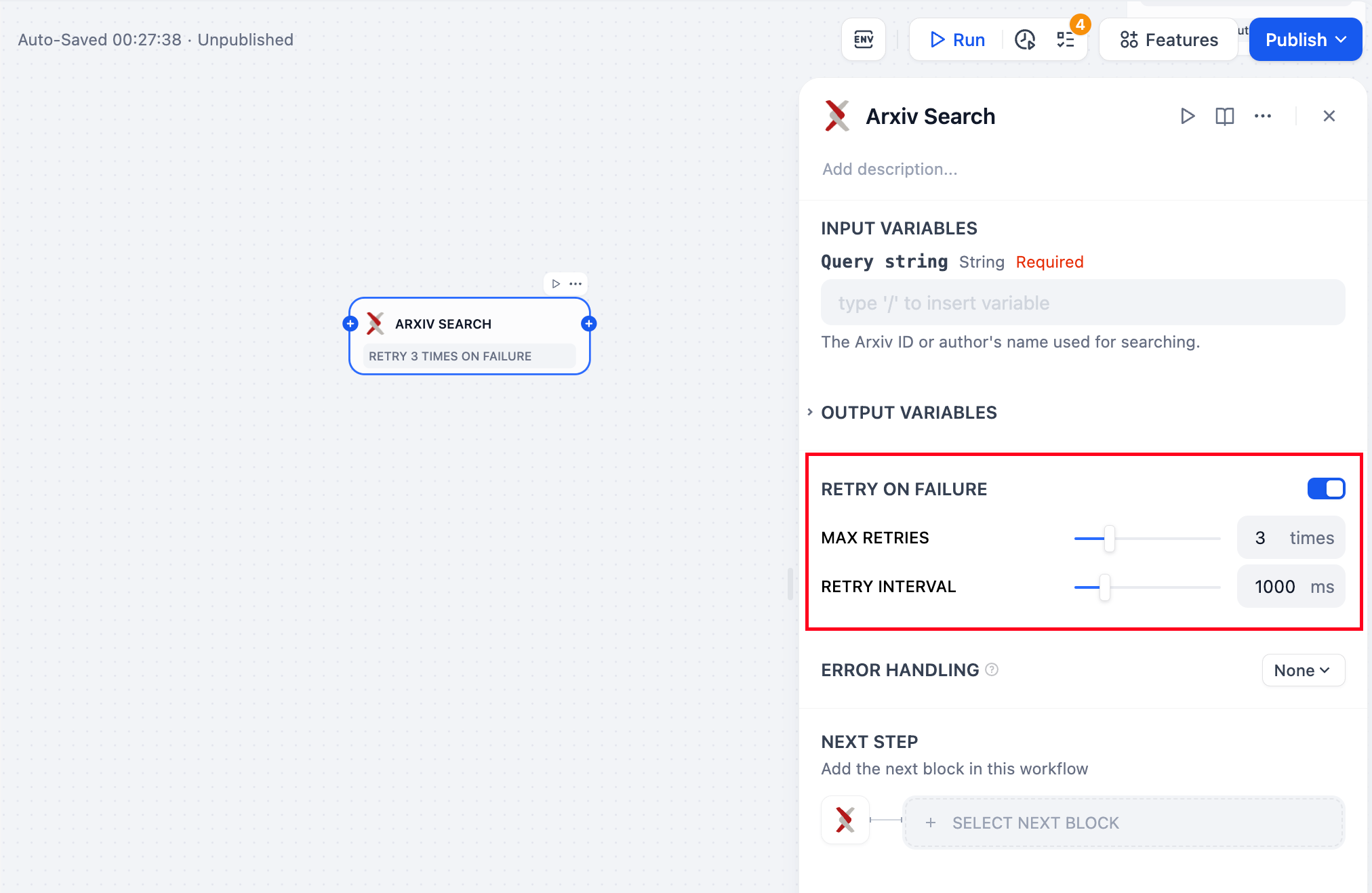 +
+
+**重试设置**自动重试失败的工具执行,最多10次,带有可配置的间隔(最大5000毫秒)。这可以处理临时服务问题或网络问题。
+
+
+
+
+
+**重试设置**自动重试失败的工具执行,最多10次,带有可配置的间隔(最大5000毫秒)。这可以处理临时服务问题或网络问题。
+
+
+ 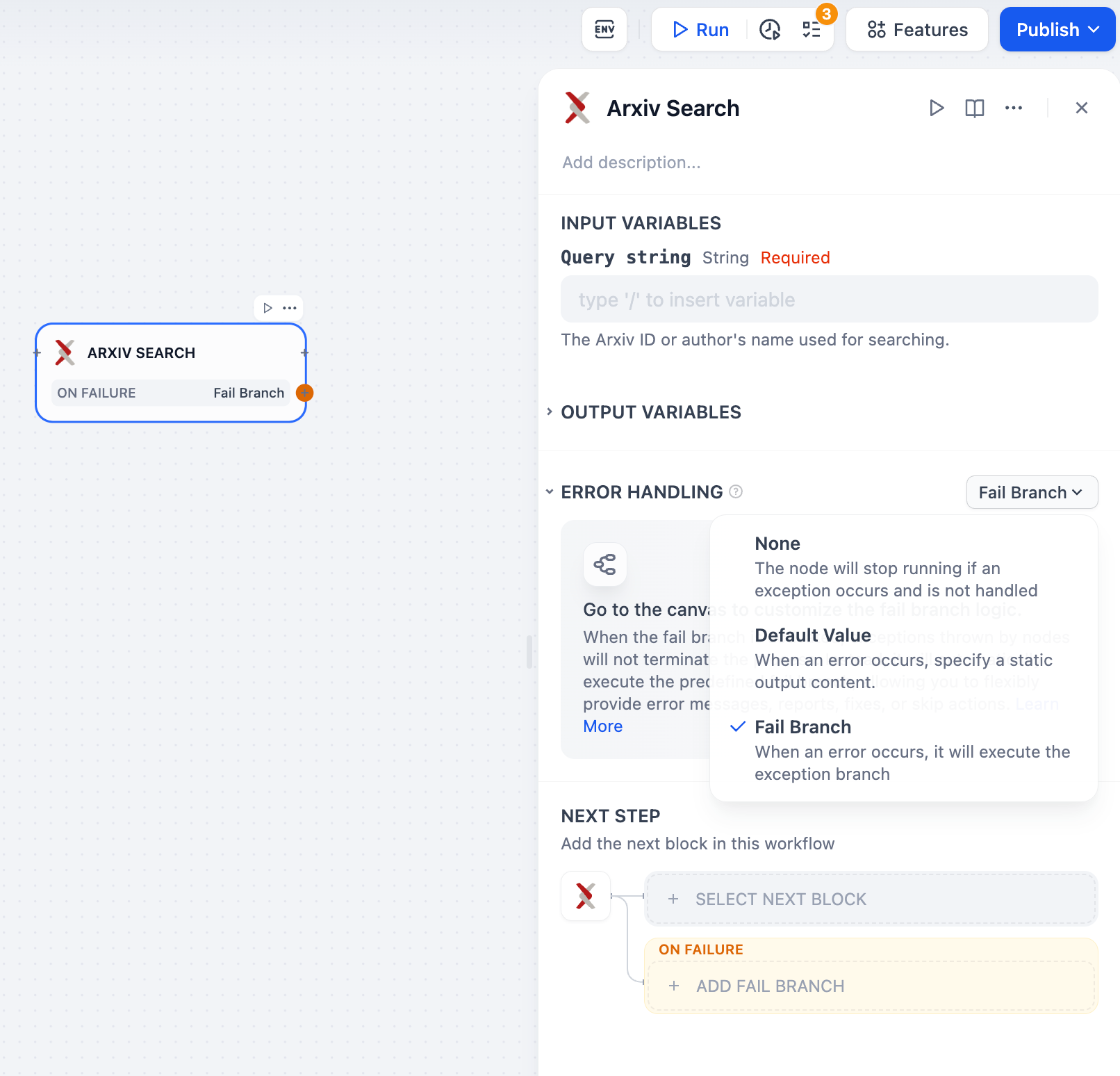 +
+
+**错误处理**定义当工具执行失败时的替代工作流路径,确保即使外部服务不可用时你的工作流也能继续。
+
+## 创建自定义工具
+
+**OpenAPI集成**允许你导入任何带有OpenAPI/Swagger规范的服务。导入后,该服务将作为工具可用,具有与内置选项相同的易用性。
+
+**工作流发布**将多节点工作流转换为可在工具。这促进了模块化并简化了复杂的工作流管理。
+
+## 工具管理
+
+通过你工作空间导航中的**工具**访问工具配置。在这里你可以管理身份验证凭据、导入自定义工具、配置MCP服务器以及将工作流发布为工具。
+
+有关工具创建、管理和将工作流发布为工具的详细指导,请参阅[工具配置指南](/zh/use-dify/nodes/tools)。
diff --git a/zh/use-dify/pages/publish/publish-mcp.mdx b/zh/use-dify/pages/publish/publish-mcp.mdx
new file mode 100644
index 000000000..4d9864c63
--- /dev/null
+++ b/zh/use-dify/pages/publish/publish-mcp.mdx
@@ -0,0 +1,58 @@
+---
+title: "MCP 服务器"
+icon: "network-wired"
+---
+
+
+
+
+**错误处理**定义当工具执行失败时的替代工作流路径,确保即使外部服务不可用时你的工作流也能继续。
+
+## 创建自定义工具
+
+**OpenAPI集成**允许你导入任何带有OpenAPI/Swagger规范的服务。导入后,该服务将作为工具可用,具有与内置选项相同的易用性。
+
+**工作流发布**将多节点工作流转换为可在工具。这促进了模块化并简化了复杂的工作流管理。
+
+## 工具管理
+
+通过你工作空间导航中的**工具**访问工具配置。在这里你可以管理身份验证凭据、导入自定义工具、配置MCP服务器以及将工作流发布为工具。
+
+有关工具创建、管理和将工作流发布为工具的详细指导,请参阅[工具配置指南](/zh/use-dify/nodes/tools)。
diff --git a/zh/use-dify/pages/publish/publish-mcp.mdx b/zh/use-dify/pages/publish/publish-mcp.mdx
new file mode 100644
index 000000000..4d9864c63
--- /dev/null
+++ b/zh/use-dify/pages/publish/publish-mcp.mdx
@@ -0,0 +1,58 @@
+---
+title: "MCP 服务器"
+icon: "network-wired"
+---
+
+ +
+## 与 Claude Desktop 集成
+
+要将你的 Dify 应用程序连接到 Claude Desktop,你需要添加一个 Claude 集成。转到你的 Claude Profile > Settings > Integrations > Add integration。用你的 Dify 应用程序的服务器 URL 替换集成 URL。
+
+## 与 Cursor 集成
+
+对于 Cursor,在你的项目根目录中创建或编辑 `.cursor/mcp.json` 文件:
+
+```json
+{
+ "mcpServers": {
+ "your-server-name": {
+ "url": "your-server-url"
+ }
+ }
+}
+```
+
+只需用你的 Dify 应用程序的 MCP 服务器地址替换 URL。Cursor 会自动检测此配置并将你的 Dify 应用程序作为工具提供。你可以通过在 `mcpServers` 对象中添加其他条目来添加多个 Dify 应用程序。
+
+## 实用注意事项
+
+- 描述性
+
+ 在为你的工具及其输入参数设计描述时,考虑 AI 如何解释它们。清晰、具体的描述能带来更好的调用效果。不要使用"输入数据",而是指定"包含用户配置文件的 JSON 对象,必需字段:姓名、邮箱、偏好设置"。
+- 延迟
+
+ MCP 协议处理通信层,但你的 Dify 应用程序的性能仍然很重要。如果你的应用程序通常需要 30 秒来处理,那么这种延迟在客户端应用程序中会被感受到。考虑添加进度指示器或将复杂的工作流分解为更小、更快的操作。
diff --git a/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx b/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx
new file mode 100644
index 000000000..d3c02816e
--- /dev/null
+++ b/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx
@@ -0,0 +1,170 @@
+---
+title: "聊天 Web App "
+---
+
+
+
+## 与 Claude Desktop 集成
+
+要将你的 Dify 应用程序连接到 Claude Desktop,你需要添加一个 Claude 集成。转到你的 Claude Profile > Settings > Integrations > Add integration。用你的 Dify 应用程序的服务器 URL 替换集成 URL。
+
+## 与 Cursor 集成
+
+对于 Cursor,在你的项目根目录中创建或编辑 `.cursor/mcp.json` 文件:
+
+```json
+{
+ "mcpServers": {
+ "your-server-name": {
+ "url": "your-server-url"
+ }
+ }
+}
+```
+
+只需用你的 Dify 应用程序的 MCP 服务器地址替换 URL。Cursor 会自动检测此配置并将你的 Dify 应用程序作为工具提供。你可以通过在 `mcpServers` 对象中添加其他条目来添加多个 Dify 应用程序。
+
+## 实用注意事项
+
+- 描述性
+
+ 在为你的工具及其输入参数设计描述时,考虑 AI 如何解释它们。清晰、具体的描述能带来更好的调用效果。不要使用"输入数据",而是指定"包含用户配置文件的 JSON 对象,必需字段:姓名、邮箱、偏好设置"。
+- 延迟
+
+ MCP 协议处理通信层,但你的 Dify 应用程序的性能仍然很重要。如果你的应用程序通常需要 30 秒来处理,那么这种延迟在客户端应用程序中会被感受到。考虑添加进度指示器或将复杂的工作流分解为更小、更快的操作。
diff --git a/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx b/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx
new file mode 100644
index 000000000..d3c02816e
--- /dev/null
+++ b/zh/use-dify/pages/publish/webapp/chatflow-webapp.mdx
@@ -0,0 +1,170 @@
+---
+title: "聊天 Web App "
+---
+
+ +
+
+用户体验流程如下:
+
+
+
+
+用户体验流程如下:
+
+ +
+
+每个AI回应都包含这些操作:
+
+- **复制按钮** - 一键复制,便于分享或记录笔记
+- **反馈按钮** - 点的应用持续改进
+- **后续建议** - AI生成3个与上下文相关的后续问题
+
+## 会话管理
+
+用户可以像现代消息应用一样管理多个对话线程:
+
+
+
+
+
+每个AI回应都包含这些操作:
+
+- **复制按钮** - 一键复制,便于分享或记录笔记
+- **反馈按钮** - 点的应用持续改进
+- **后续建议** - AI生成3个与上下文相关的后续问题
+
+## 会话管理
+
+用户可以像现代消息应用一样管理多个对话线程:
+
+
+  +
+
+**对话控制功能:**
+- **新建** - 开始新的对话而不丢失之前对话的上下文
+- **置顶重要对话** - 将重要对话保持在列表顶部,便于访问
+- **删除已完成对话** - 清理不再相关的对话
+
+
+
+
+**对话控制功能:**
+- **新建** - 开始新的对话而不丢失之前对话的上下文
+- **置顶重要对话** - 将重要对话保持在列表顶部,便于访问
+- **删除已完成对话** - 清理不再相关的对话
+
+ +
+
+当用户开始新对话时,AI会主动介绍自己并解释其功能。这立即向用户展示他们可以完成什么任务,并提高参与度。
+
+
+
+
+当用户开始新对话时,AI会主动介绍自己并解释其功能。这立即向用户展示他们可以完成什么任务,并提高参与度。
+
+ +
+
+这些建议具有以下特点:
+- **与当前对话主题相关**
+- **基于AI的回应动态生成**
+- **可点击的快捷方式**,帮助用户深入探索或转向相关主题
+
+## 语音输入
+
+语音转文字将你的聊天 Web App 转变为语音优先的体验:
+
+
+
+
+
+这些建议具有以下特点:
+- **与当前对话主题相关**
+- **基于AI的回应动态生成**
+- **可点击的快捷方式**,帮助用户深入探索或转向相关主题
+
+## 语音输入
+
+语音转文字将你的聊天 Web App 转变为语音优先的体验:
+
+
+  +
+
+**工作原理:**
+1. 当你在对话流中启用语音转文字时,会出现麦克风按钮
+2. 用户点击开始录制他们的问题
+3. 语音在说话时实时转换为文本
+4. 他们可以在发送前编辑文本或立即发送
+
+
+
3. 在负载均衡池中启用至少 2 个凭据,点击 **保存**。已启用负载均衡的模型将带有特殊标识。
- 
+
+
+
+**工作原理:**
+1. 当你在对话流中启用语音转文字时,会出现麦克风按钮
+2. 用户点击开始录制他们的问题
+3. 语音在说话时实时转换为文本
+4. 他们可以在发送前编辑文本或立即发送
+
+
+
3. 在负载均衡池中启用至少 2 个凭据,点击 **保存**。已启用负载均衡的模型将带有特殊标识。
- 
+