Releases: QoderAI/blog
Repo Wiki: Surfacing Implicit Knowledge
desc: Turn code into living, shared documentation.
category: Product
img: https://img.alicdn.com/imgextra/i2/O1CN01c6LKGp1NGHqns4lxb_!!6000000001542-0-tps-1712-1152.jpg
time: September 11, 2025 · 3min read
What can Repo Wiki do for you?
Repo Wiki automatically generates a structured documentation knowledge base for your project based on your code, covering project architecture, dependency diagrams, technical documentation, and other content while continuously tracking changes in both code and documentation. It transforms experiential knowledge hidden in code into explicit knowledge that can be shared across teams, converting experience into reusable project assets. When developing with Qoder, Repo Wiki can help in:
- Improving collaboration efficiency with Agents
Structured and complete engineering knowledge enables Agents to better understand context and provide you with more accurate, detailed answers, significantly boosting development efficiency.
- Quickly learning about projects
By reviewing clear engineering documentation, you can quickly grasp project structure and implementation details, easily get started with development.
How is Repo Wiki generated?
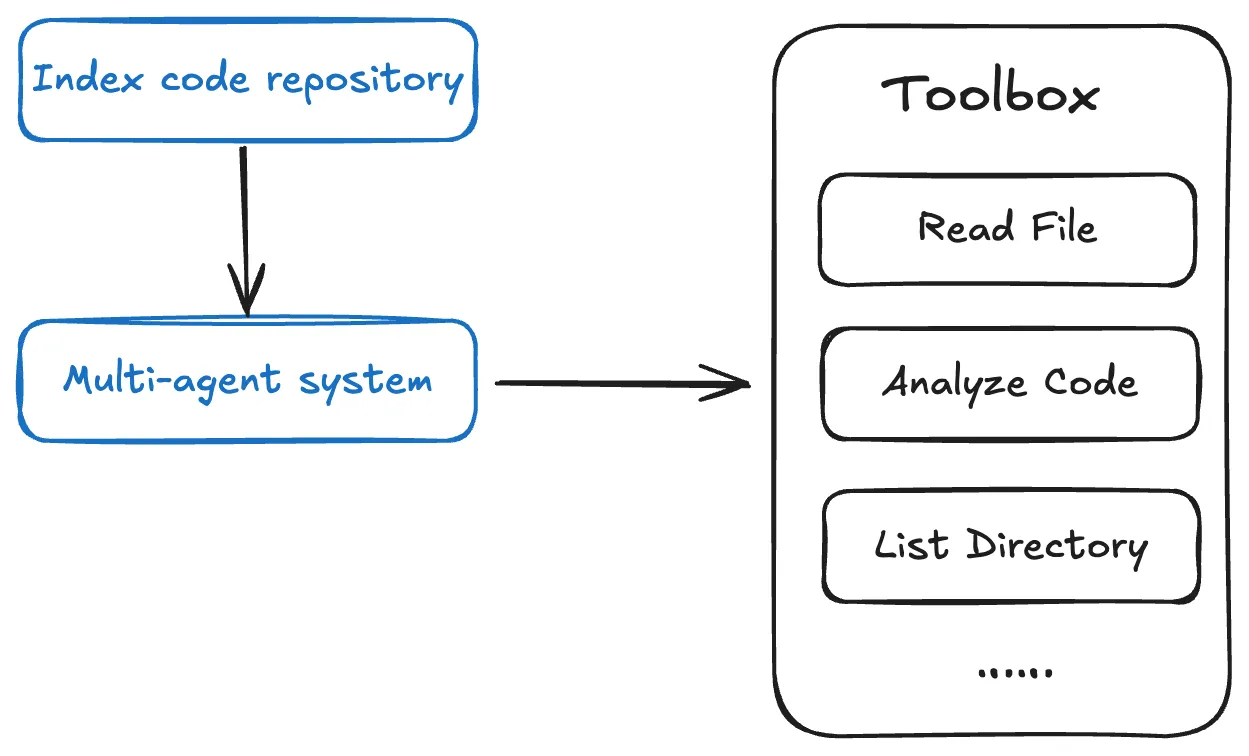
Repo Wiki utilizes a multi-Agent architecture, generating project knowledge in phases.
-
Repo Wiki automatically establishes an index for the code repository, thereby providing Agents with strong codebase awareness through its tools.
-
The multi-Agent system analyzes and models the code repository, plans documentation structure, balances knowledge depth with reading efficiency, and appropriately captures project knowledge across various types of documentation.
How is Repo Wiki maintained and shared?
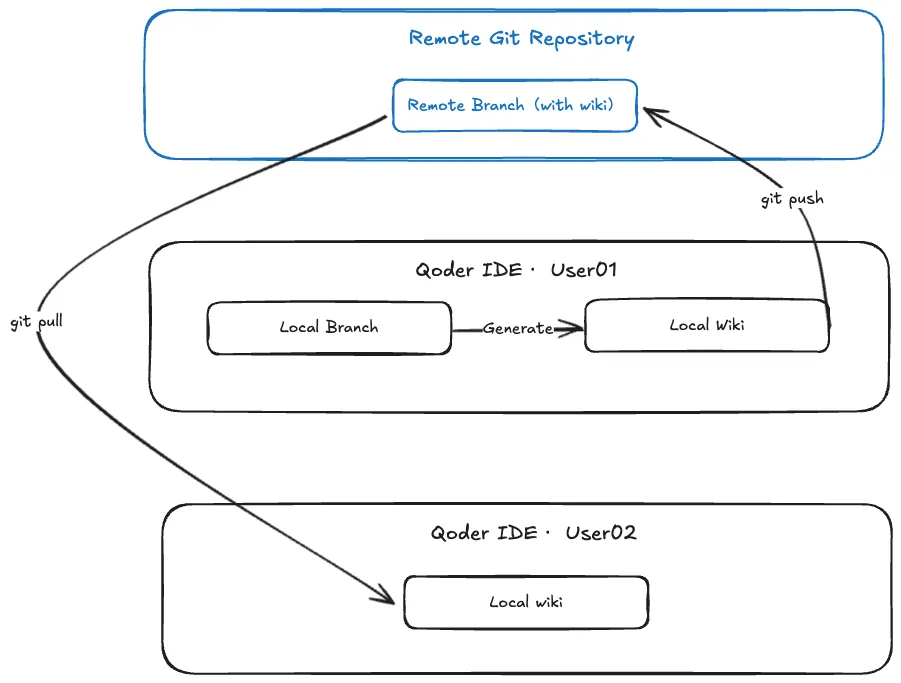
Wiki sharing
Wiki sharing is offered to share project knowledge within the team. When you generate a Wiki locally, the directory (.qoder/repowiki) is automatically created in your code repository. Simply pushing this directory to the remote repository allows you to easily share the generated Wiki with team members.
Content maintenance and export
To ensure the Wiki remains consistent with the code, the system automatically detects code changes and prompts you to update the related Wiki.
Also, self-maintenance is supported. You can modify files in the Wiki directory (.qoder/repowiki) and synchronize changes back to the Wiki by yourself.
Best practices
Get better AI chat responses
-
When querying about code repositories, the Agent will quickly respond. It automatically consults the relevant Wiki, combining contextual information to provide accurate code explanations, relevant technical documentation, and implementation details.
-
When adding features or fixing bugs, the Agent automatically consults Repo Wiki, combining real-time project learning to provide solutions that align with the project architecture. This ensures new code maintains consistency with the existing system while improving development efficiency.
Learn about code faster
- Through Repo Wiki, you can quickly learn about the project's overall architecture, module dependencies, and technical implementation details, as Repo Wiki provides a structured knowledge base, including project architecture descriptions, dependency diagrams, and detailed technical documentation.
Qwen-Coder-Qoder: Customizing a fast-evolving frontier model for real software
desc: Inside Qwen-Coder-Qoder: The RL-optimized model behind Qoder's agent architecture
category: Product
img: https://img.alicdn.com/imgextra/i3/O1CN01fbHceT1K4t9NQua1T_!!6000000001111-2-tps-1712-1152.png
time: February 1, 2026 · 5 min read
Introduction
Today, we are pleased to introduce Qwen-Coder-Qoder, a customized model tailored to elevate the end-to-end agentic coding experience on Qoder.
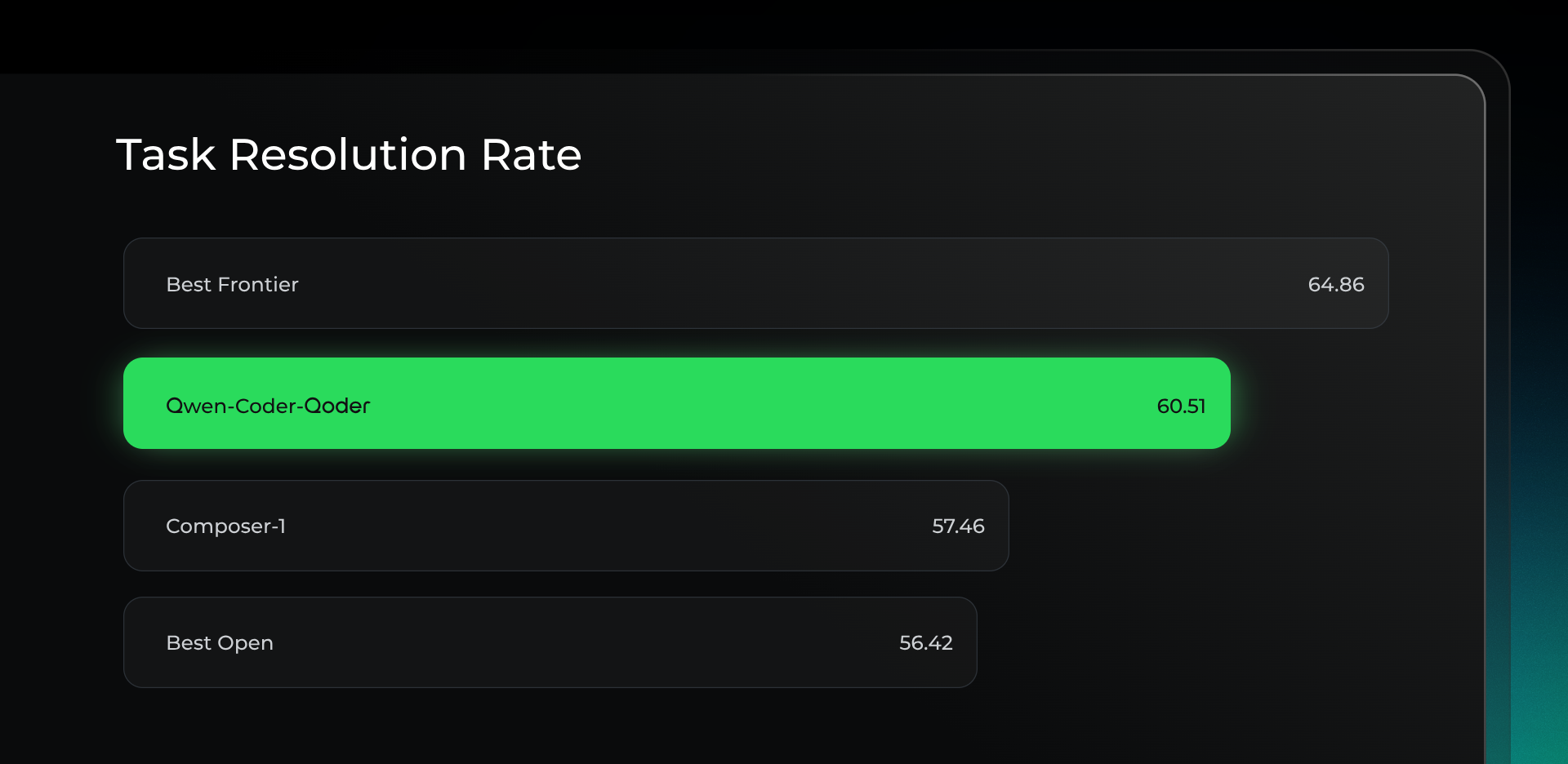
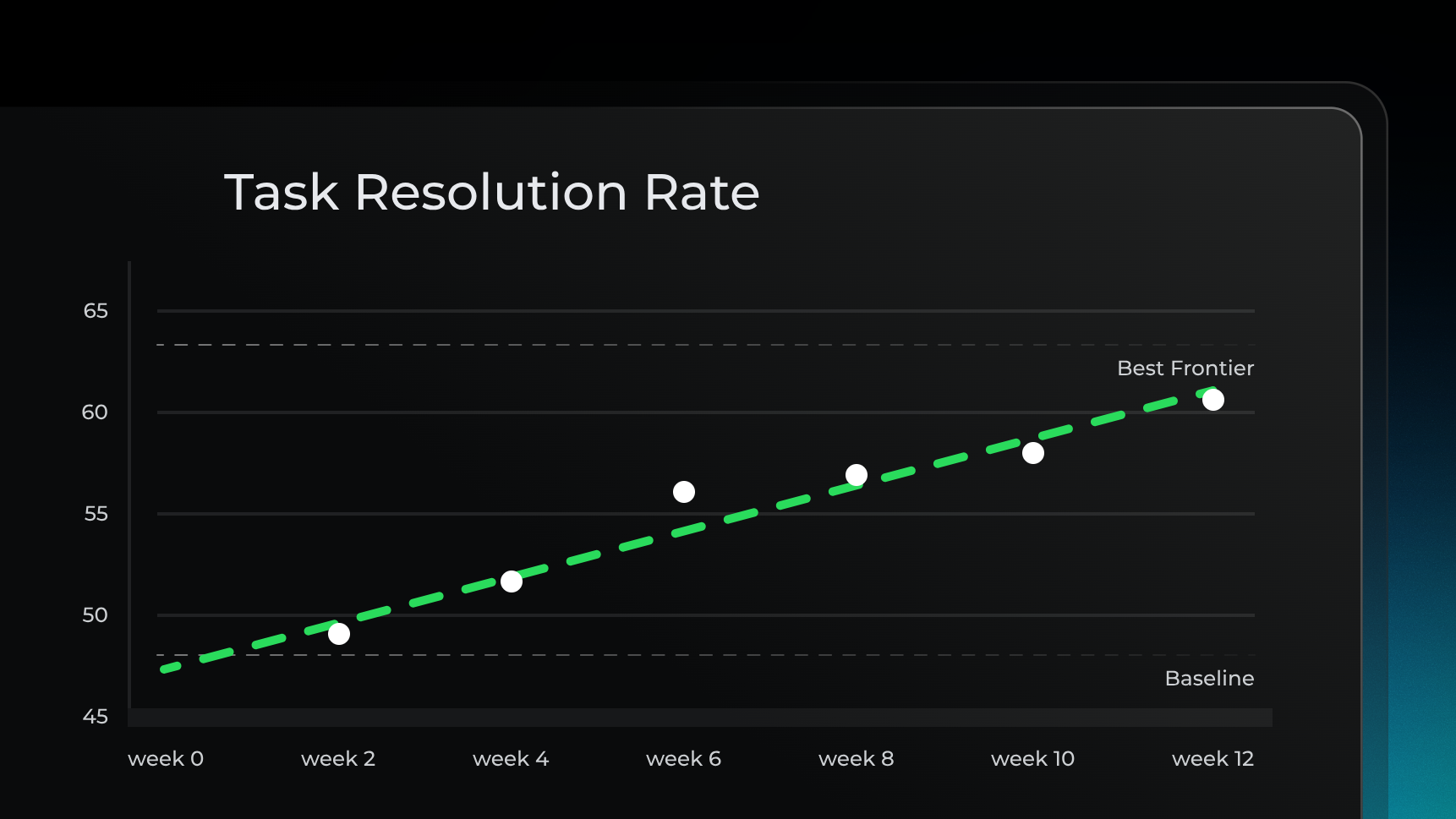
Built upon the Qwen-Coder foundation, Qwen-Coder-Qoder has been optimized with large-scale reinforcement learning to align tightly with Qoder's scenarios, tools, and agent architecture. On Qoder Bench — our benchmark for real-world software engineering tasks — it surpasses Cursor Composer-1 in task resolution performance. The gains are particularly notable on Windows, where terminal command accuracy is improved by up to 50%.
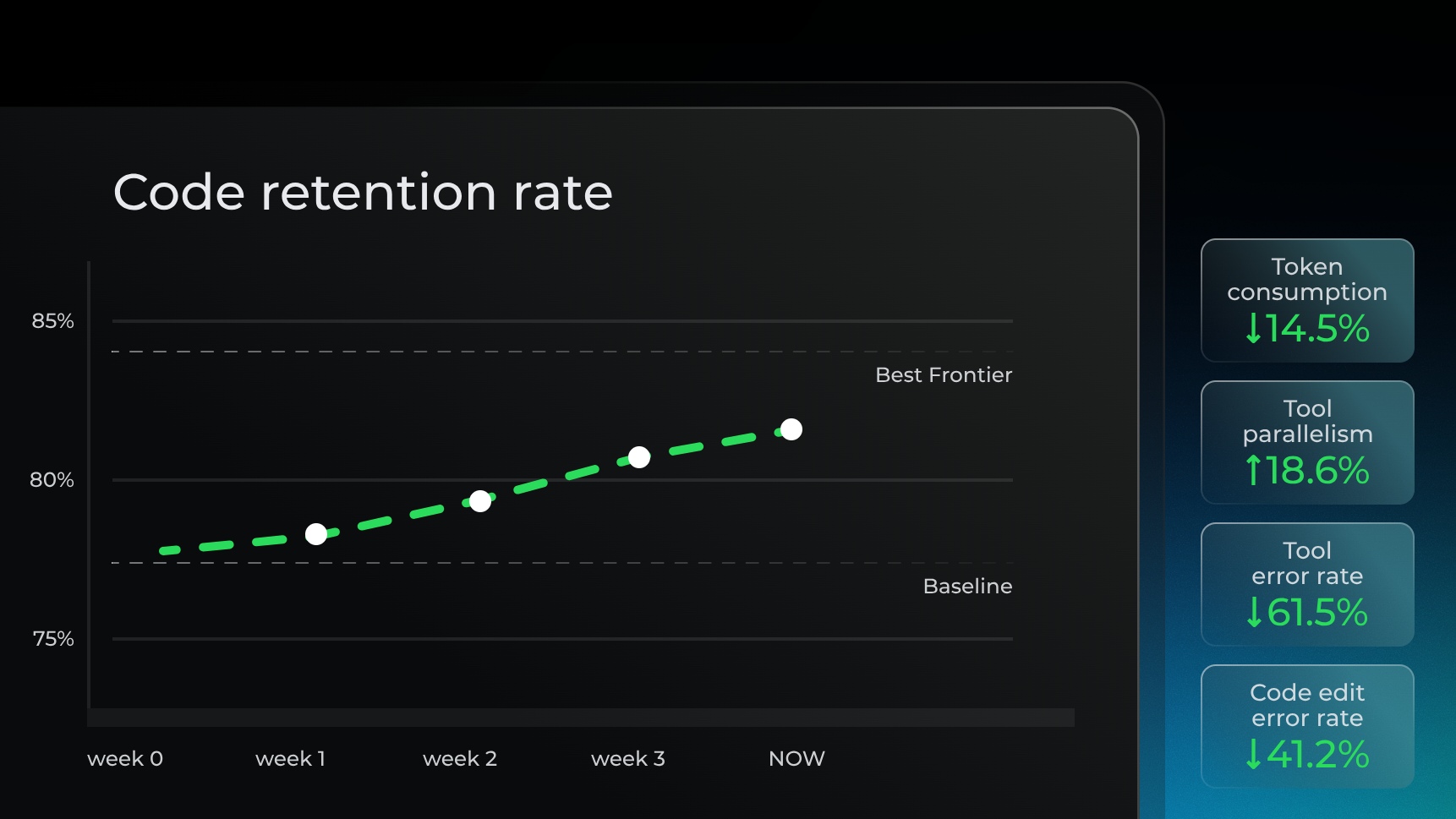
At the same time, Qwen-Coder-Qoder has delivered tangible, data-backed improvements to the Qoder user experience. With rapid model iterations, we have observed meaningful gains in production over the past few weeks: code retention has increased by 3.85%, tool error rates have dropped by 61.5%, and token consumption has decreased by 14.5%. These metrics now position Qoder alongside the world's top-tier models.
Beyond superior performance metrics, Qwen-Coder-Qoder reflects the 'taste' and 'mindset' of a senior software engineer. We believe a great AI coding partner shouldn't just solve problems—it should solve them elegantly and masterfully.
- Adheres to best engineering practices: Many general models optimize solely for task resolution and may take shortcuts that bypass established engineering conventions. In contrast, Qwen-Coder-Qoder is trained to follow rigorous software engineering principles, maintain consistent project code style, and ensure production-ready outputs.
- Holistic Repository Understanding: By leveraging Qoder's unique context systems — including code graphs, project memory, and Repo Wiki — Qwen-Coder-Qoder understands the project from a global perspective and uses the right tools to complete tasks with precision.
- High-Efficiency Parallelism: The model recognizes tasks that don't depend on each other and runs them parallelly — whether it's fetching code, planning tasks, or making multiple edits. This makes the entire workflow much faster.
- Resilient Problem Solving: When faced with complex or stubborn issues, general models may abandon the task after limited attempts. Qwen-Coder-Qoder demonstrates a developer-level persistence: it refines its approach iteratively and stays engaged until the problem is resolved.
Our Vision: A "Model-Agent-Product" Flywheel for Co-evolving Intelligence
Qwen-Coder-Qoder is not an accident — it is the inevitable outcome of the intelligent evolution loop we've built around the Model-Agent-Product paradigm.
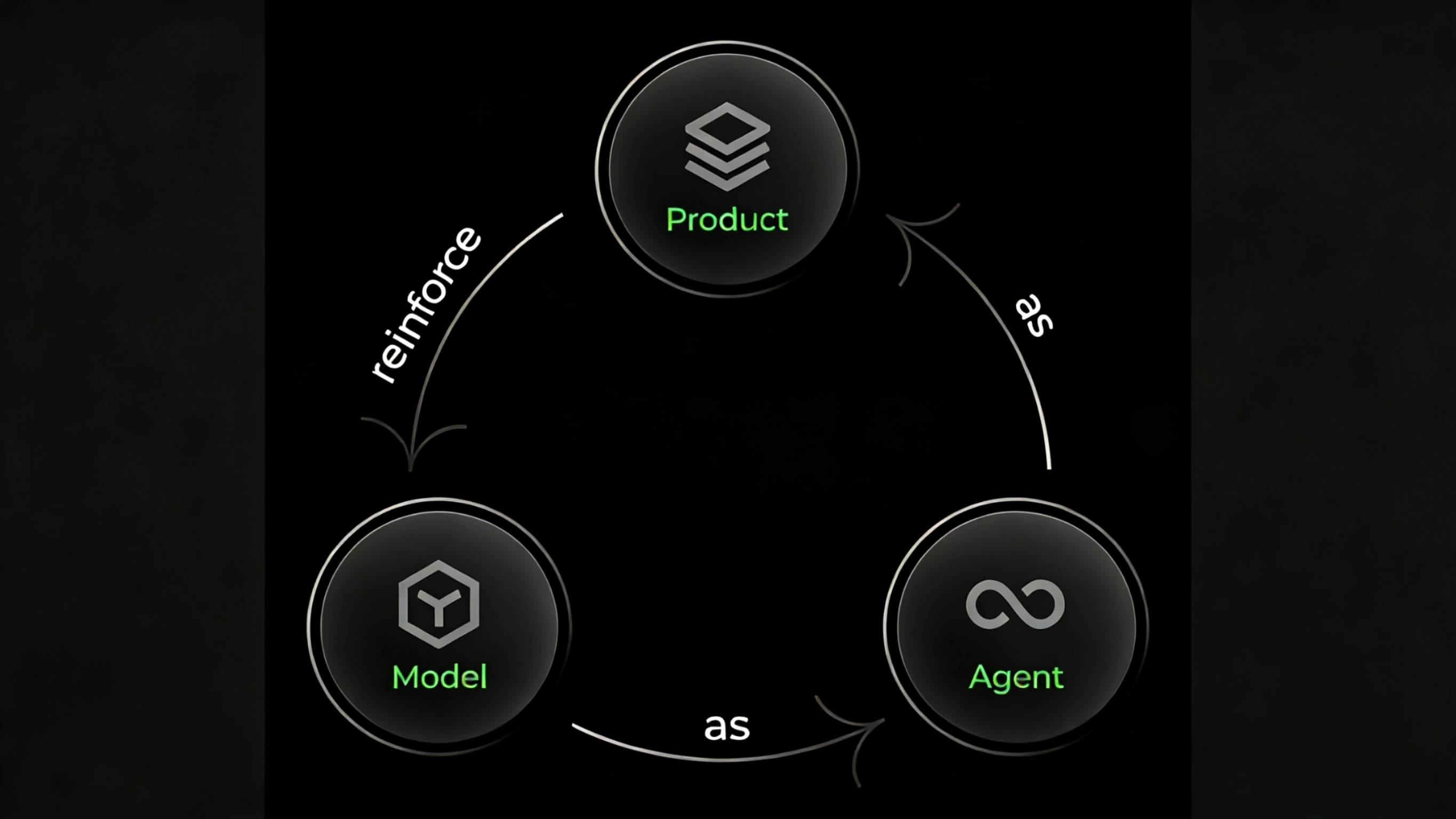
In the rapidly evolving landscape of AI coding, we've focused on building a self-evolving cycle: Model → Agent → Product (model as agent, agent as product, product reinforces model). This loop ensures that insights from real user interactions continuously inform and enhance our models' capabilities. At the core of this system, the model provides the foundation — we embed all of the capabilities required by the Qoder Agent directly into Qwen-Coder-Qoder, which powers task execution. On the product side, the Agent is central — every feature and workflow in Qoder revolves around it. With thousands of users engaging with the product daily, we capture real-world usage patterns and preferences, extract best software engineering practices, and convert them into reward signals that further strengthen our RL training.
This completes our flywheel of software engineering intelligence. Qwen-Coder-Qoder is a large-scale RL model trained on real-world product environments, real-world development tasks, and real-world rewards.
Under the Hood: How We Made It Happen
Achieving these results requires a robust, state-of-the-art training strategy built on three core elements:
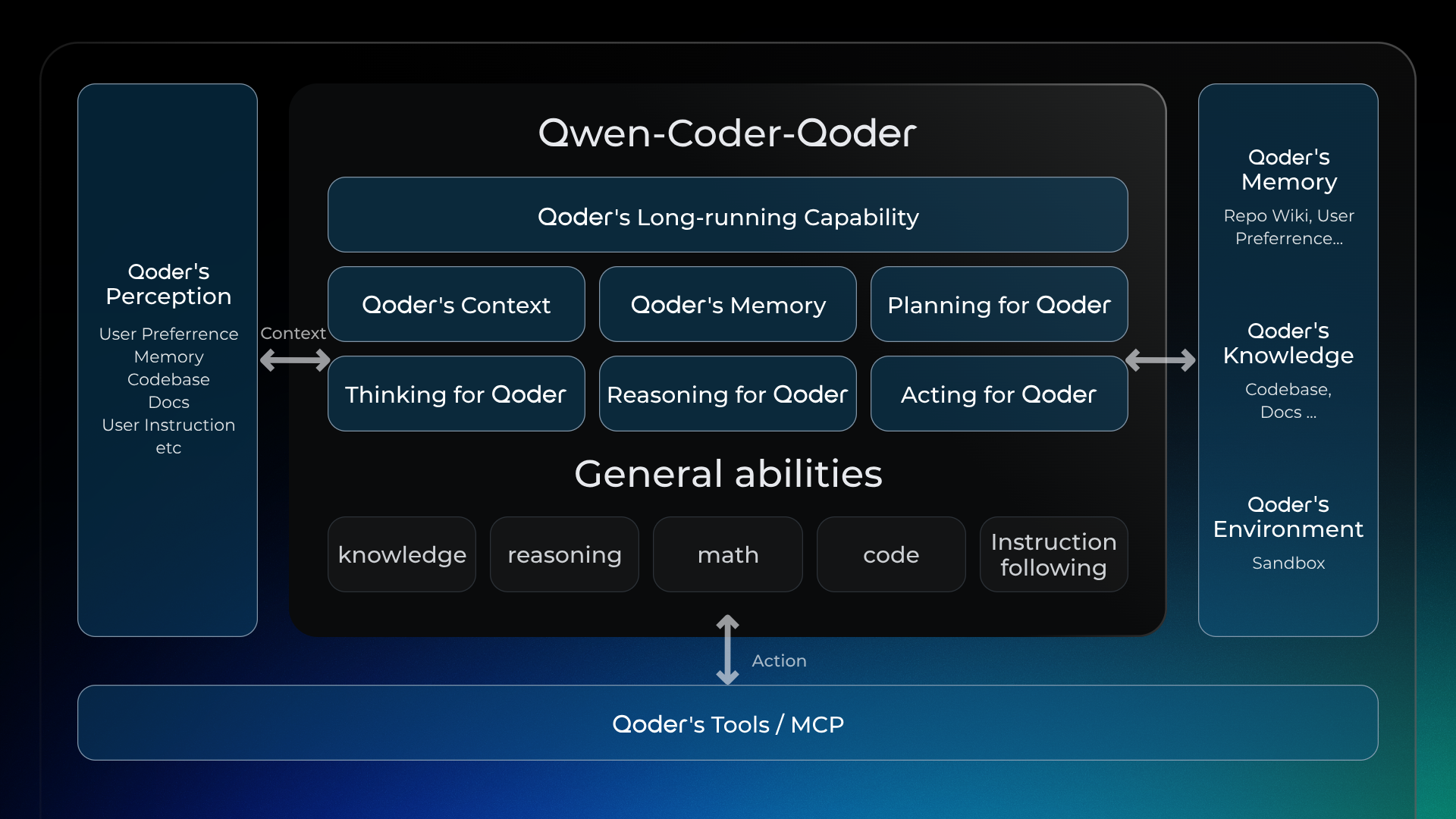
A Real-World Qoder Agent as the Sandbox
We train the model to master the full stack of Qoder's Knowledge, Memory, Tools/MCP, and Context to solve real-world coding tasks. Unlike general-purpose models, our model is tightly aligned with the Qoder product. As the model continues to evolve, this synergy is unlocking massive value. To scale this, we've automated the setup of tens of thousands of real-world software environments. Using High-speed containerization, we can spin up and tear down these sandboxes instantly to power our reinforcement learning at massive scale.
Real-World Best Engineering Practices as Reward Signals
In agentic reinforcement learning, reward signals are critical to guiding the model toward desirable behaviors. We use several criterias to verify correctness including unit tests, CLI checks, and custom checklists to make sure the agent actually gets the job done. It's not just about getting a passing diff patch. We also enforce strict rules on how the code is written, ensuring the entire process follows professional engineering standards. we ensure the agent's output meets the same standards you'd expect from a senior engineer.
Reward hacking is an inherent challenge in reinforcement learning. For instance, if we reward the model for parallel tool use to boost speed, it might try to 'game the system' by scanning tons of irrelevant files just to rack up points. While the parallelism metrics look great, there's no real contribution to the final accuracy.
Solving Reward Hacking is essentially a battle of wits with the model. To tackle this, we built a 'Rewarder-Attacker' adversarial framework. We use an LLM as a reviewer to constantly stress-test and 'attack' our reward system, hunting for loopholes before training even begins. This setup has drastically improved both the iteration speed and the robustness of our reward design.
Large-Scale, High-Efficiency RL Training Framework
Qwen-Coder-Qoder is powered by ROLL, which is optimized to enable efficient RL training of MoE LLMs with hundreds of billions of parameters on clusters scaled to thousands of GPUs. In a typical RL loop, the rollout phase often consumes over 70% of the total time. To maximize end-to-end throughput, we optimized the system from two angles:
- Optimizing the Rollout Phase: We implemented asynchronous scheduling to minimize idle time, Prefix/KV cache reuse to eliminate redundant compute, and redundant environment execution to mitigate long-tail latency.
- Rollout-Training Co-design: We decoupled the two by relaxing on-policy constraints to allow cross-version sampling. By running training and rollout in parallel, we implemented dynamic resource yielding, ensuring that GPUs are surrendered to rollout during training wait times.
Together, these system-level optimizations delivered a 10x boost in throughput, significantly compressing our training cycles.
Future Prospects
The Qwen-Coder-Qoder we're releasing today is the first milestone of our "Model-Agent-Product" flywheel. In just a few short months, we've already witnessed how this loop can drastically elevate the end-to-end experience.
This is just the beginning. Doubling down on this trajectory, we will continue to evolve through weekly iterations, refining model efficacy and experience as we forge ahead toward an 'Agentic Coding Platform for Real Software'.
Quest Remote: Delegate Tasks to Cloud as Effortlessly as Sending an Email
desc: Let the cloud handle the routine and free your mind for what matters.
img: https://img.alicdn.com/imgextra/i4/O1CN01rVNSWR22RBWIKqmk8_!!6000000007116-2-tps-1712-1152.png
category: Feature
time: October 22, 2025 · 3min read
Qoder’s flagship feature, the Quest Mode, has now reached a major milestone with the launch of the all-new "Remote Delegation" capability. This upgrade empowers developers to outsource complex, time-consuming development tasks to a secure, cloud-based sandbox environment for asynchronous execution, and fully liberates local computing resources. Therefore, developers can finally break free from tedious background operations and refocus on the pure joy and value of coding. Qoder delivers a more efficient and secure AI-native development experience to developers worldwide.
What is Remote Delegation?
Before diving into remote delegation, let’s revisit the core philosophy behind Quest: Task Delegation. In Qoder, every development requirement—large or small—is abstracted into a "Quest". A Quest could range from bug fixes and feature developments to major code refactoring. Traditionally, developers must personally handle each step of the Quest lifecycle.
Quest Mode, introduces a highly capable coding agent, elevating developers from "executors" to "commander". You simply interact with the agent locally to generate the task specification (Spec), which then guides the agent to autonomously handle the development process. This means developers need only express intent clearly; the system will formulate an execution plan and perform the tasks. Previously, Quest tasks are delegated mainly to local agents for code generation and automated testing. This helps improving coding efficiency—but constraints in environment setup, resources, and security remains.
Now, with Remote Delegation, Qoder fully extends the delegation paradigm from the local machine to the cloud.
How Remote Delegation Works
Imagine you’re facing an extremely challenging task: upgrading dependencies and refactoring the performance of a massive codebase. In the past, this meant cloning the entire repository, dealing with outdated dependencies, and then getting ready for an unpredictable, time-consuming battle—all on your local machine.
With Qoder’s Remote Delegation, your workflow becomes dramatically more streamlined:
-
Create a Quest
Describe your task objectives in natural language within Qoder to create a new Quest. -
Generate a Design Document
Qoder automatically crafts a detailed design document for your Quest through interactive dialogue. -
One-Click Delegation
Once you’ve reviewed and approved the design document, simply click "Start" to send the task to the cloud for execution. -
Refocus Your Attention
You’re now free to concentrate on creative, high-impact work.
Under the Hood
The moment you delegate a task, Qoder performs all of the following:
-
Intelligent Environment Provisioning
Qoder instantly creates an isolated, secure, and high-performance sandbox in the cloud. It automatically analyzes your project, detects required runtime environments, language versions, toolchains, and dependencies, and preconfigures everything. -
Asynchronous Task Execution
A powerful cloud-based agent takes the helm, tackling your task like a seasoned developer: cloning code, analyzing dependencies, upgrading packages, compiling, trouble shooting, bug fixing, iterative testing, and more—all executed asynchronously and efficiently in the cloud. -
Real-Time Progress Tracking
Within Qoder IDE, you can monitor task progress in real time, much like tracking a parcel: view current steps, obstacles encountered, and solutions the AI agent is attempting—all at a glance. -
Seamless Human-AI Collaboration
If the cloud agent encounters a challenge it cannot resolve autonomously, the task is paused and Qoder notifies you for input. You can review the context within the IDE, provide guidance, and let the agent continue. -
Review and Merge Results
Once the Quest is complete, Qoder delivers a comprehensive report—including a summary and code changes—and submits the final result as a Pull Request to your repository, ready for your review and merge.
Core Value of Remote Delegation
Quest Remote brings transformative benefits to developers:
-
Unleash Productivity:
Delegate repetitive, resource-intensive tasks to the cloud, freeing your focus for creative work—ideation, design, and innovation. -
Accelerate Learning and Exploration:
Want to experiment with a new technology or framework? Skip the local setup. Delegate with a click and instantly validate your ideas in a cloud sandbox, dramatically lowering the barrier to new tech adoption. -
Extend Your Reach:
Once delegated to a Remote Agent, your tasks keep progressing in the cloud—even when your laptop is closed—expanding the time and space boundaries of AI-powered coding. -
Embrace the Future:
Remote Delegation fundamentally reimagines development workflows for a cloud-native era, aligning the coding process with real deployment environments—ushering in true DevOps and modern cloud-native culture.
Let the cloud handle the routine and free your mind for what matters. Upgrade Qoder and experience the future of development with Quest Remote!
Quest 1.0: Refactoring the Agent with the Agent
desc: Tokens Produce Deliverables, Not Just Code
category: Technology
img: https://img.alicdn.com/imgextra/i2/O1CN01dz3f931IyBjmbJ4B0_!!6000000000961-2-tps-1712-1152.png
time: January 15, 2026 · 8 min read
Last week, the Qoder Quest team accomplished a complex 26-hour task using Quest 1.0: refactoring its own long-running task execution logic. This wasn't a simple feature iteration, as it involved optimizing interaction flows, managing mid-layer state, adjusting the Agent Loop logic, and validating long-running task execution capabilities.
From requirement definition to merging code into the main branch, the Qoder Quest team only did three things: described the requirements, reviewed the final code, and verified the experimental results.
This is the definition of autonomous programming: AI doesn't just assist or pair. It autonomously completes tasks.
Tokens Produce Deliverables, Not Just Code
Copilot can autocomplete code, but you need to confirm line by line. Cursor or Claude Code can refactor logic, but debugging and handling errors is still your job. These tools improve efficiency, but humans remain the primary executor.
The problem Quest solves is this: Tokens must produce deliverable results. If AI writes code and a human still needs to debug, test, and backstop, the value of those tokens is heavily discounted. Autonomous programming is only achieved when AI can consistently produce complete, runnable, deliverable results.
Agent Effectiveness = Model Capability × Architecture
From engineering practice, we've distilled a formula:
Agent Effectiveness = Model Capability × Agent Architecture (Context + Tools + Agent Loop)
Model capability is the foundation, but the same model performs vastly differently under different architectures. Quest optimizes architecture across three dimensions: context management, tool selection, and Agent Loop, to fully unleash model potential.
Context Management: Agentic, Not Mechanical
As tasks progress, conversations balloon. Keeping everything drowns the model; mechanical truncation loses critical information. Quest employs "Agentic Context Management": letting the model autonomously decide when to compress and summarize.
Model-Driven Compression
In long-running tasks, Quest lets the model summarize completed work at appropriate moments. This isn't "keep the last N conversation turns"; it's letting the model understand which information matters for subsequent tasks and what can be compressed.
Compression triggers based on multiple factors:
-
Conversation rounds reaching a threshold
-
Context length approaching limits
-
Task phase transitions (e.g., from exploring to implementation)
-
Model detection of context redundancy
The model makes autonomous decisions based on current task state, rather than mechanically following fixed rules.
Dynamic Reminder Mechanism
The traditional approach hardcodes all considerations into the system prompt. But this bloats the prompt, scatters model attention, and tanks cache hit rates.
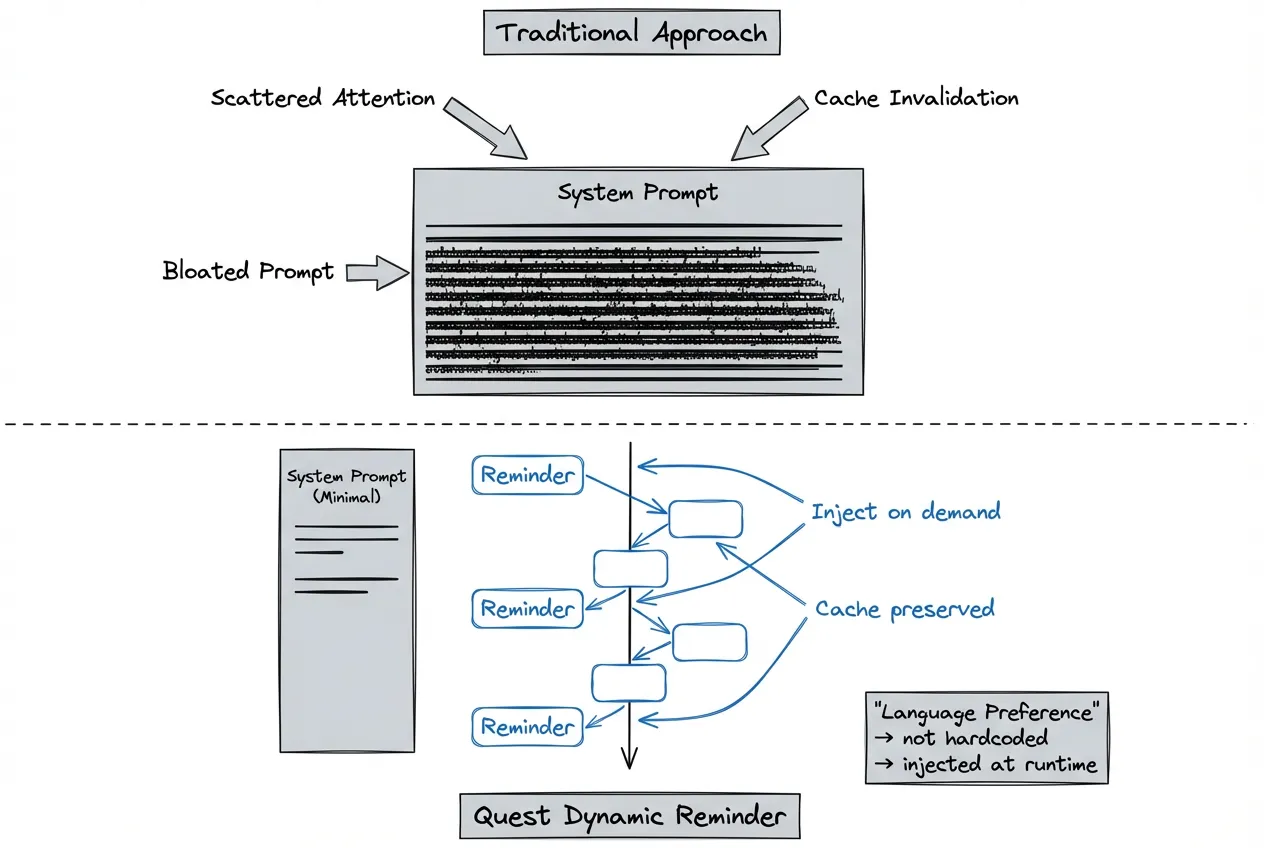
Take language preference as an example:
Traditional approach: System prompt hardcodes "Reply in Japanese." Every time a user switches languages, the entire prompt cache invalidates, multiplying costs.
Quest approach: Dynamically inject context that needs attention through the Reminder mechanism. Language preferences, project specs, temporary constraints—all added to conversations as needed. This ensures timely information delivery while avoiding infinite system prompt bloat.
Benefits:
-
Improved cache hit rates, reduced inference costs
-
Lean system prompts, enhanced model attention
-
Flexible adaptation to different scenario requirements
Tool Selection: Why Bash is the Ultimate Partner
If we could only keep one tool, it would be Bash. This decision may seem counterintuitive. Most agents on the market offer rich specialized tools: file I/O, code search, Git operations, etc. But increasing tool count raises model selection complexity and error probability.
Three Advantages of Bash
Comprehensive. Bash handles virtually all system-level operations: file management, process control, network requests, text processing, Git operations. One tool covers most scenarios—the model doesn't need to choose among dozens.
Programmable and Composable. Pipelines, redirects, and scripting mechanisms let simple commands compose into complex workflows. This aligns perfectly with Agent task decomposition: break large tasks into small steps, complete each with one or a few commands.
Native Model Familiarity. LLMs have seen vast amounts of Unix commands and shell scripts during pre-training. When problems arise, models can often find solutions themselves without detailed prompt instructions.
Less is More
Quest still maintains a few fixed tools, mainly for security isolation and IDE collaboration. But the principle remains: if Bash can solve it, don't build a new tool.
Every additional tool increases the model's selection burden and error potential. A lean toolset actually makes the Agent more stable and predictable. Through repeated experimentation, after removing redundant specialized tools, task completion rates remained the same level while context token consumption dropped by 12%.
Agent Loop: Spec -> Coding -> Verify
Autonomous programming's Coding Agent needs a complete closed loop: gather context > formulate plan > execute coding > verify results > iterate optimization.
Observing coding agents in the market, users most often say "just run it...", "make it work", "help me fix this error." This exposes a critical weakness: they're cutting corners on verification. AI writes code, humans test it - that's not autonomous programming.
Spec-Driven Development Flow
Spec Phase: Clarify requirements before starting, define acceptance criteria. For complex tasks, Quest generates detailed technical specifications, ensuring both parties agree on the definition of "done."
Spec elements include:
-
Feature description: What functionality to implement
-
Acceptance criteria: How to judge completion
-
Technical constraints: Which tech stacks to use, which specifications to follow
-
Testing requirements: Which tests must pass
Coding Phase: Implement functionality according to Spec. Quest proceeds autonomously in this phase, without continuous user supervision.
Verify Phase: Automatically run tests, verify implementation meets Spec. Verification types include syntax checks, unit tests, integration tests, etc. If criteria aren't met, automatically enter the next iteration rather than throwing the problem back to the user.
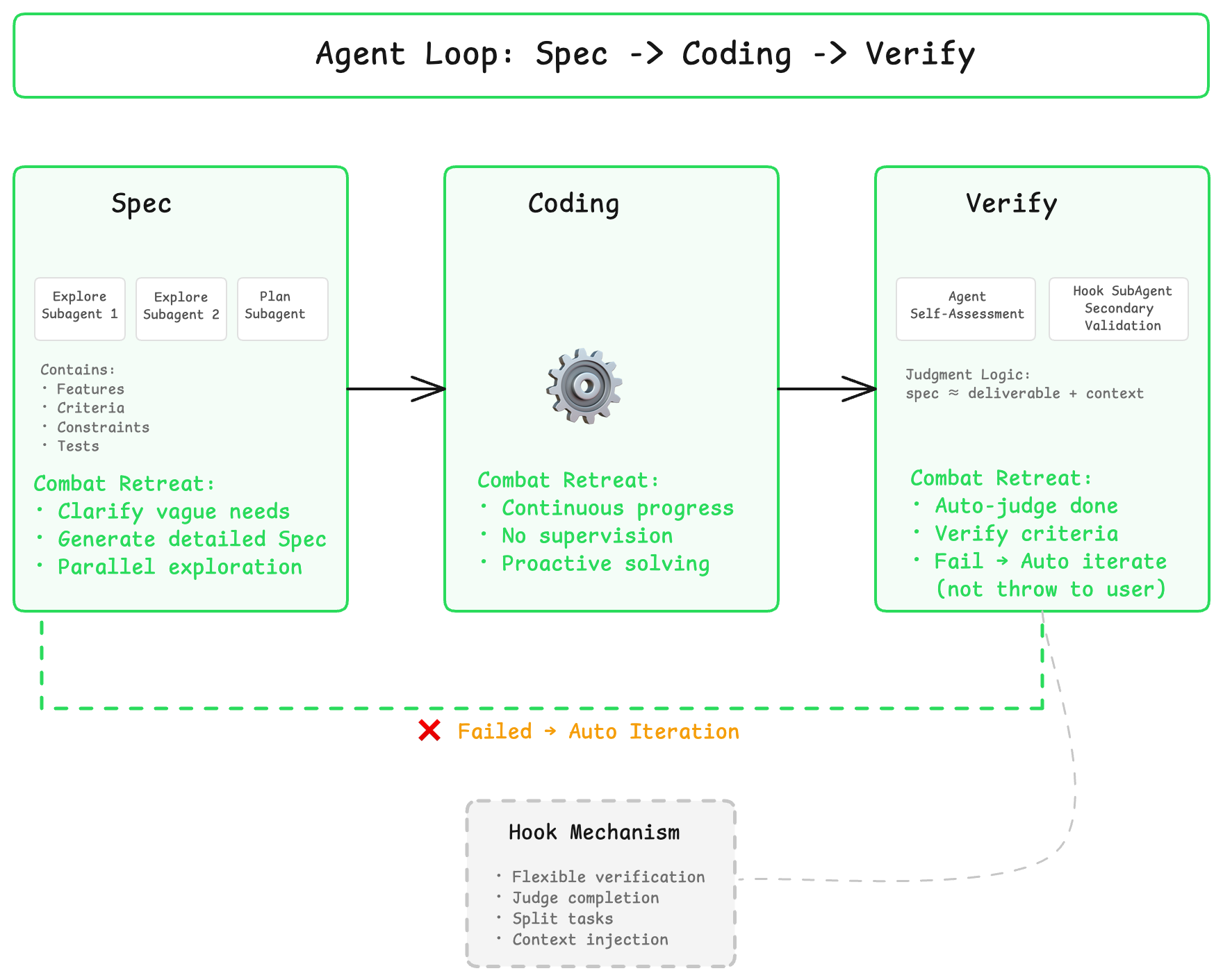
Through the Hook mechanism, these three phases can be flexibly extended and combined. For example, integrate custom testing frameworks or lint rules in the Verify phase, ensuring every delivery meets team engineering standards.
Combating Model "Regress" Tendency
Most current models are trained for ChatBot scenarios. Facing long contexts or complex tasks, they tend to "regress", giving vague answers or asking for more information to delay execution.
Quest's architecture helps models overcome this tendency: injecting necessary context and instructions at appropriate moments, pushing models to complete the full task chain rather than giving up midway or dumping problems back on users.
Auto-Adapt to Complexity, Not Feature Bloat
Quest doesn't just handle code completion. It manages complete engineering tasks. These tasks may involve multiple modules, multiple tech stacks, and require long-running sustained progress.
The design principle: automatically adapt strategy based on task complexity. Users don't need to care about how scheduling works behind the scenes.
Dynamic Skills Loading
When tasks involve specific frameworks or tools, Quest dynamically loads corresponding Skills. Skills encapsulate validated engineering practices, such as:
-
TypeScript configuration best practices
-
React state management patterns
-
Common database indexing pitfalls
-
API design specifications
This isn't making the model reason from scratch every time—it's directly reusing accumulated experience.
Teams can also encapsulate engineering specs into Skills, making Quest work the team's way. Examples:
-
Code style guides
-
Git commit conventions
-
Test coverage requirements
-
Security review checklists
Intelligent Model Routing
When a single model's capabilities don't cover task requirements, Quest automatically orchestrates multiple models to collaborate. Some models excel at reasoning, others at writing, others at handling long contexts.
Intelligent routing selects the most suitable model based on subtask characteristics. To users, it's always just one Quest.
Multi-Agent Architecture
When tasks are complex enough to require parallel progress and modular handling, Quest launches multi-agent architecture: the main Agent handles planning and coordination, subagents execute specific tasks, companion Agents supervise. But we use this capability with restraint. Multi-agent isn't a silver bullet because context transfer has loss, and task decomposition has high barriers. We only enable it when truly necessary.
Designed for Future Models
From day one, Quest has been designed for SOTA models. The architecture doesn't patch for past models. It ensures that as underlying model capabilities impr...
Quest Mode: Task Delegation to Agents
desc: Introducing Quest Mode. Your new AI-assisted coding workflow.
time: August 21, 2025 · 3 min read
category: Product
img: https://img.alicdn.com/imgextra/i4/O1CN0103AFeh1vZhZmtD0wg_!!6000000006187-0-tps-1712-1152.jpg
With the rapid advancement of LLMs—especially following the release of the Claude 4 series—we've seen a dramatic improvement in their ability to handle complex, long-running tasks. More and more developers are now accustomed to describing intricate features, bug fixes, refactoring, or testing tasks in natural language, then letting the AI explore solutions autonomously over time. This new workflow has significantly boosted the efficiency of AI-assisted coding, driven by three key shifts:
-
Clear software design descriptions allow LLMs to fully grasp developer intent and stay focused on the goal, greatly improving code generation quality.
-
Developers can now design logic and fine-tune functionalities using natural language, freeing them from code details.
-
The asynchronous workflow eliminates the need for constant back-and-forth with the AI, enabling a multi-threaded approach that delivers exponential gains in productivity.
We believe these changes mark the beginning of a new paradigm in software development—one that overcomes the scalability limitations of “vibe coding” in complex projects and ushers in the era of natural language programming. In Qoder, we call this approach Quest Mode: a completely new AI-assisted coding workflow.
Spec First
As agents become more capable, the main bottleneck in effective AI task execution has shifted from model performance to the developer’s ability to clearly articulate requirements. As the saying goes: Garbage in, garbage out. A vague goal leads to unpredictable and unreliable results.
That’s why we recommend that developers invest time upfront to clearly define the software logic, describe change details, and establish validation criteria—laying a solid foundation for the agent to deliver accurate, high-quality outcomes.
With Qoder’s powerful architectural understanding and code retrieval capabilities, we can automatically generate a comprehensive spec document based on your intent—accurate, detailed, and ready for quick refinement. This spec becomes the single source of truth for alignment between you and the AI.
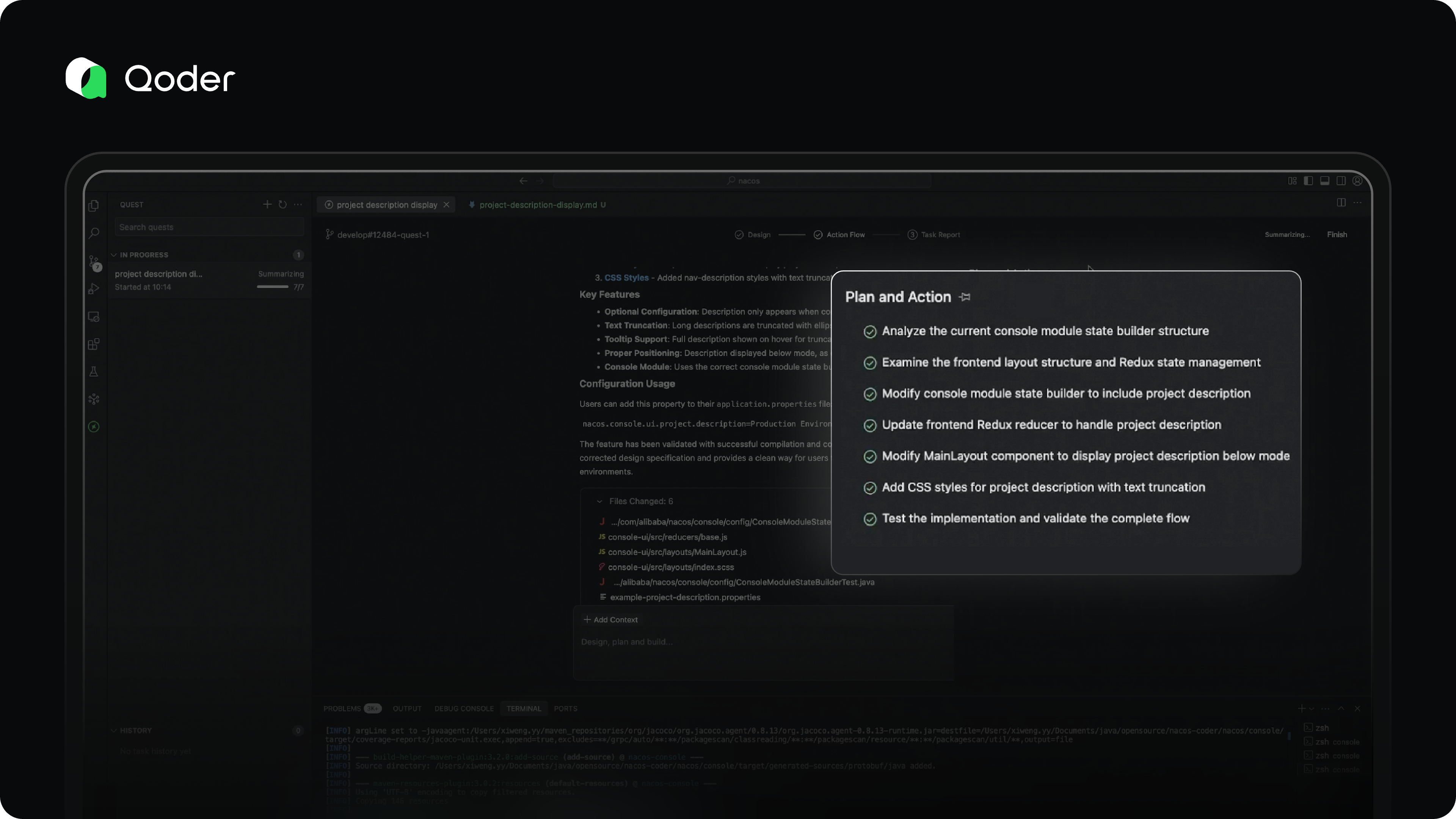
Action Flow
Once the spec is finalized, it's time to let the agent run.
You can monitor its progress through the Action Flow dashboard, which visualizes the agent’s planning and execution steps. In most cases, no active supervision is needed. If the agent encounters ambiguity or a roadblock, it will proactively send an Action Required notification. Otherwise, silence means everything is on track.
Our vision for Action Flow is to enable developers to understand the agent’s progress in under 10 seconds—what it has done, what challenges it faced, and how they were resolved—so you can quickly decide the next steps, all at a glance.
Task Report
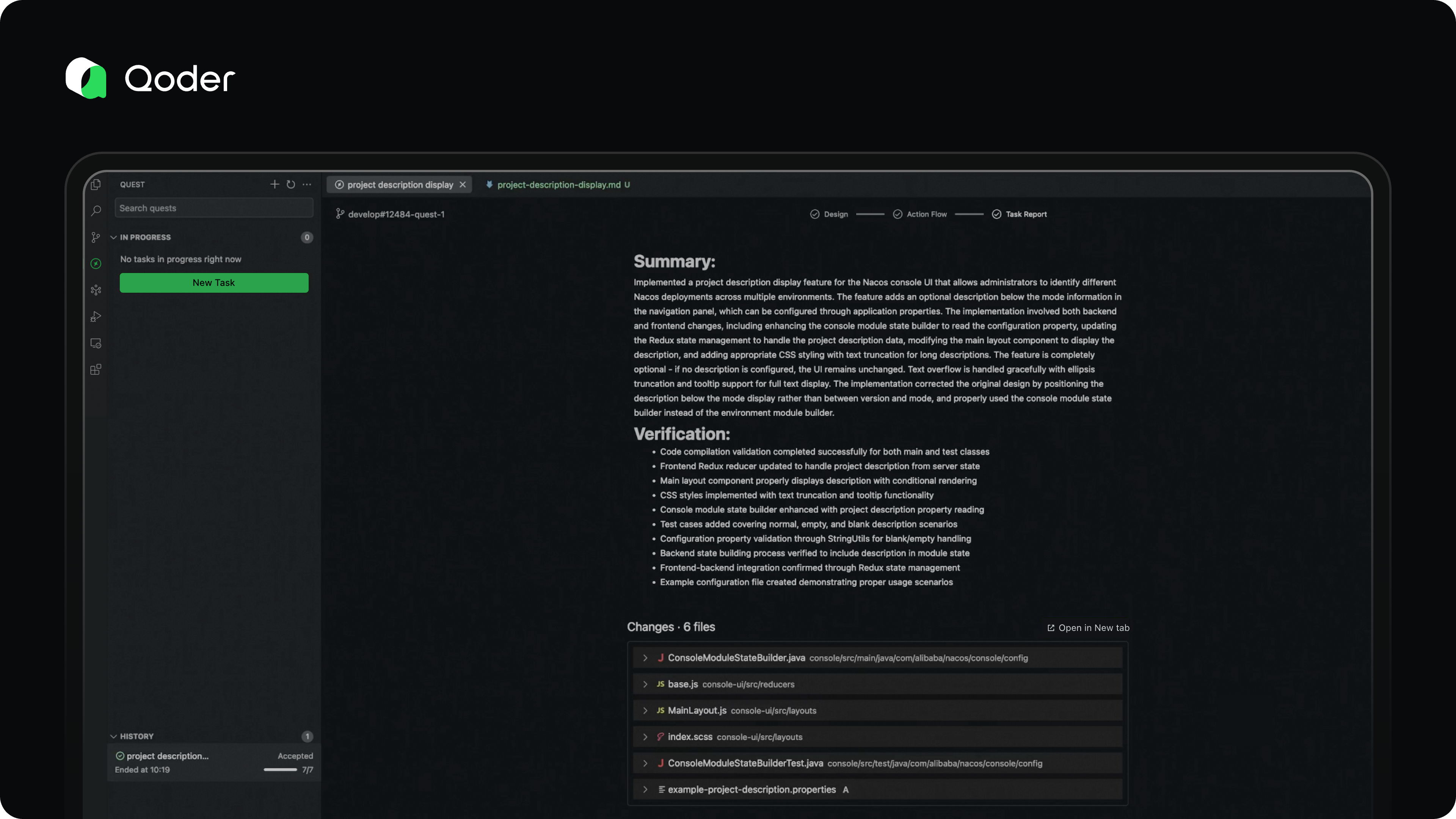
For long-running coding tasks, reviewing dozens or hundreds of code changes can be overwhelming. That’s where comprehensive validation becomes essential.
In Quest Mode, the agent doesn’t just generate code—it validates its own work, iteratively fixes issues, and produces a detailed Task Report for the developer.
This report includes:
-
An overview of the completed coding task
-
Validation steps and results
-
A clear list of code changes
The Task Report helps developers quickly assess the reliability and correctness of the output, enabling confident, efficient decision-making.
What’s Next
We’re continuing to refine Spec-Driven Development as a breakthrough approach to real-world programming efficiency. Specs are the key to ensuring that agent-generated code meets expectations.
Our long-term vision is to delegate programming tasks to autonomous agents that work asynchronously—delivering 10x or greater productivity gains.
Going forward, we’ll focus on:
-
Improving the speed and quality of collaborative spec creation between developers and AI
-
Enabling cloud-based, always-on agent execution, so your AI assistant is available anytime, anywhere
Welcome to the future of software development—where you think deeper, and let AI build better.
Stop feeding your model every tool definition
desc: How we cut 10% of Quest's context cost by not showing the model tools it doesn't need
category: Technology
img: https://img.alicdn.com/imgextra/i3/O1CN01XjwNoT26FyIKVEFRP_!!6000000007633-2-tps-1712-1152.png
time: February 25, 2026 · 5min read
Quest 1.0 is Qoder's autonomous coding agent. It takes a task description, plans a solution, writes the code, and runs it. Users can extend Quest with Skills (specialized knowledge modules loaded on demand), and this post is about an optimization we made to how Skills and MCP tools get loaded into context.
The trigger
Shortly after launching Quest 1.0, a user reported that a task burned through a large amount of credits without delivering satisfactory results.
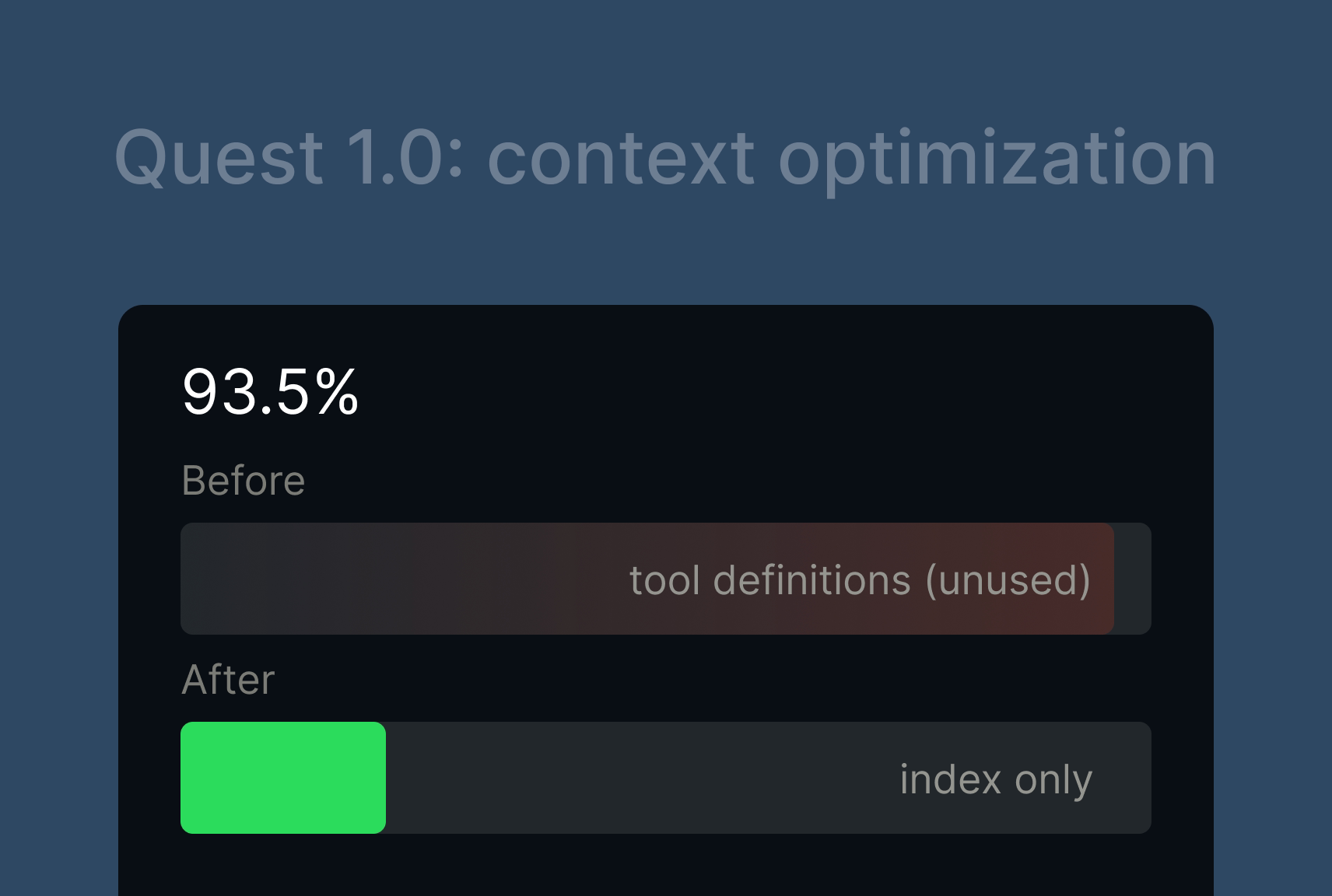
We pulled the token distribution data from that conversation. Out of 120K input tokens, 93.5% were tool definitions. None of those tools were called even once during the entire task.
This was an extreme case. The user had configured multiple MCP Servers loaded with tools. But it exposed a broader problem: context was stuffed with "just in case" definitions that rarely got used.
One of us configured playwright-mcp for frontend automation testing. After the tests were done, it sat there unused. Its tool definitions kept showing up in every subsequent conversation's context, and nobody noticed for weeks.
We ran a controlled experiment: same task, with two MCP Servers mounted (but never actually used during the task) vs. without. The unused tools alone inflated credits consumption by over 10%. The reason: just two MCP Servers contributed nearly a hundred tool definitions, consuming close to 2,000 tokens.
An internal team survey confirmed the pattern: 80% of colleagues had at least one MCP Server configured, but actual usage frequency was under 10%.
The problem was clear: how do you reduce MCP tools' context footprint without removing them entirely?
Finding inspiration in Skills optimization
Before tackling MCP, we had already hit a similar wall with another feature: Skills.
Quest's Skills feature lets users define specialized knowledge and workflows that an Agent can load on demand. But users reported that Skills' automatic invocation rate was disappointing, often requiring a manual /skills command to trigger.
We tested in an environment with 28 Skills: the model's autonomous invocation rate was under 50%.
Why was invocation rate low?
A model invoking a Skill needs to complete three steps:
- Understanding what capability the current task requires (intent recognition)
- Finding the right Skill in the known Skills list (capability matching)
- Determining when to load it and how to use it (timing)
Steps 1 and 3 depend on the model's reasoning ability and will naturally improve with model upgrades. The bottleneck was step 2: how does the model know which Skills are available?
The most straightforward approach was putting all Skills' full definitions into the system prompt. It worked, but the cost was context bloat: full descriptions for 28 Skills easily consumed thousands of tokens, while a single task typically only needed 1-2 of them.
Skill routing index
Our approach: place a lightweight Skills index in the System Reminder instead of full definitions.
The index contains only each Skill's name and a one-line description, totaling a few hundred tokens. The model uses this index for intent matching. If it determines a Skill is needed, it locates and loads the full content through the index.
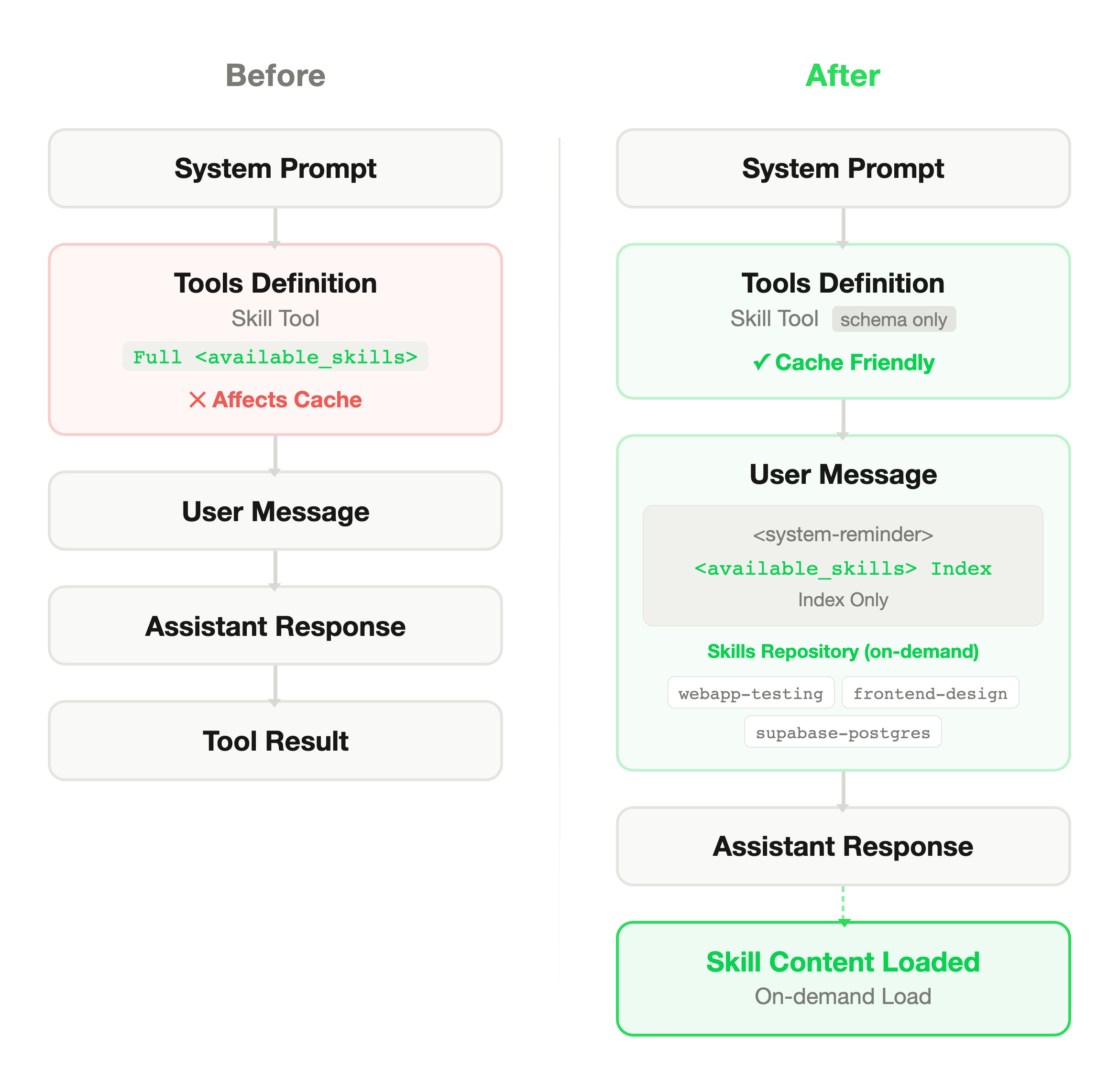
The design had three constraints. The index had to be lightweight (a new context burden would defeat the point). One-line descriptions had to be accurate enough for correct matching. And the injection mechanism had to preserve Prompt Cache hit rates, which meant leaving the Tools Definition structure unchanged and injecting dynamically via System Reminder instead.
This assumes the model is smart enough to judge whether it needs a Skill without seeing the full definition. Tell it "there's a tool called X that does Y," and it can decide whether to load it at the right moment.
Results
Skill invocation rate went from under 50% to above 90%. Total token consumption dropped by roughly 12%.
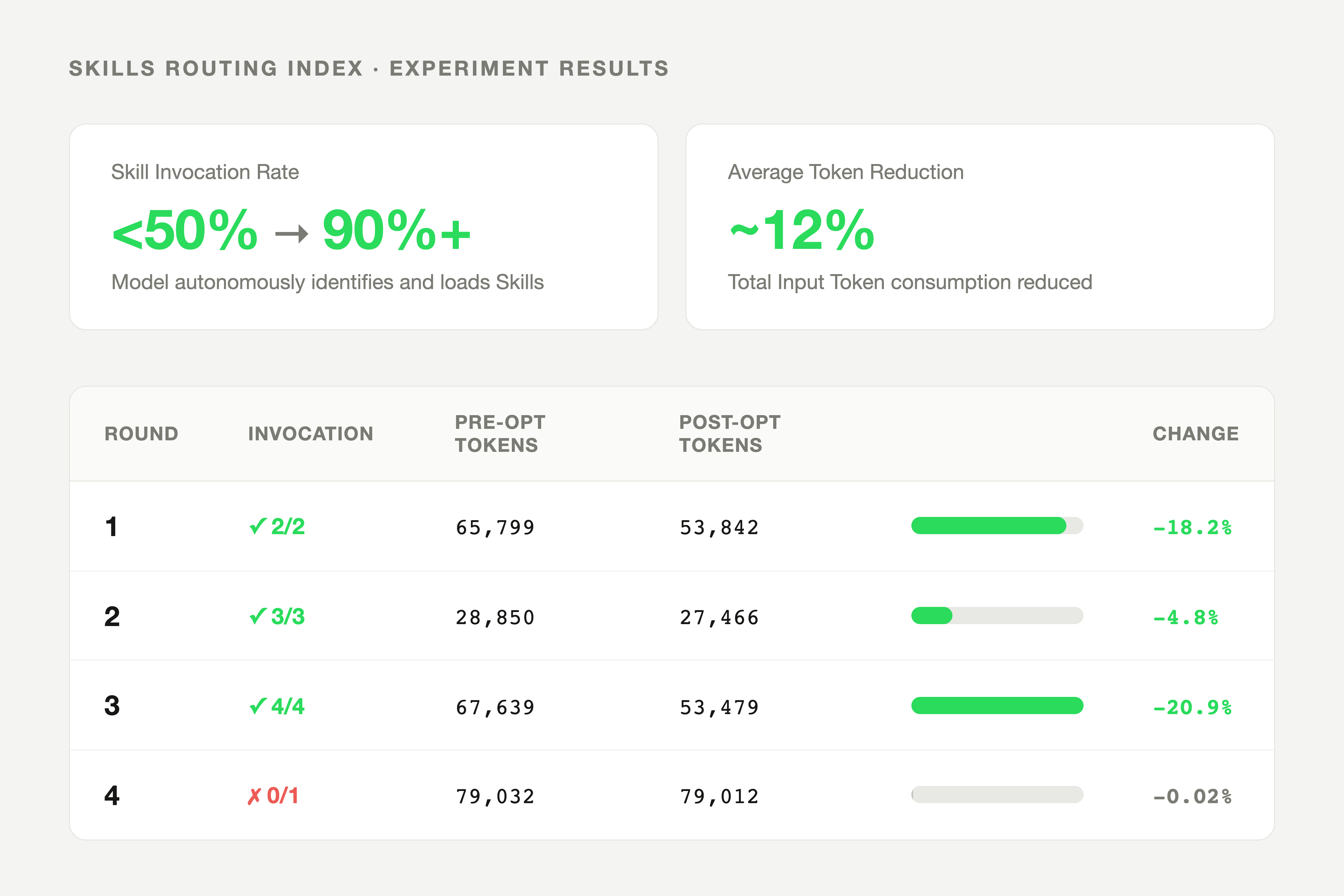
| Round | Invoked / Should Invoke | Pre-optimization Input Tokens | Post-optimization Input Tokens | Reduction |
|---|---|---|---|---|
| 1 | 2/2 | 65,799 | 53,842 | 18.2% |
| 2 | 3/3 | 28,850 | 27,466 | 4.8% |
| 3 | 4/4 | 67,639 | 53,479 | 20.9% |
| 4 | 0/1 | 79,032 | 79,012 | 0.02% |
Round 4's failure is worth noting: the Skill the task required had low similarity to its index description, so the model failed to identify it. Index quality turned out to matter more than we expected. Get the one-line description wrong and on-demand loading never triggers.
Extending to MCP: dynamic loading
The Skills experience validated a pattern: a lightweight index plus on-demand loading can compress context while preserving functionality.
MCP tools face the same problem. Could we apply the same approach?
Technically yes, but MCP adds a layer of complexity. Skills are essentially text instructions with forgiving formatting. MCP tools require precise JSON Schema for correct invocation: parameter names, types, nested structures. A missing field or type mismatch causes the call to fail. So MCP's dynamic loading demands higher "injection precision."

Our design uses two phases.
Phase 1 is discovery: the System Reminder shows only MCP tool summary indexes (name + one-line description), without full Schema. This mirrors the Skills approach.
Phase 2 is injection: when the model determines it needs a specific MCP tool, it calls a meta-tool called LoadMcpTool, which dynamically injects that tool's full JSON Schema into the current context. After injection, the model can invoke the tool through the standard flow.
LoadMcpTool is a lightweight tool whose Schema is always present in the context (consuming only a few dozen tokens). It is the gateway: the model uses it to "pull" other tools' full definitions.
The result: the initial context contains only summary indexes, full Schema is injected when needed without simplification, and the model always invokes tools from complete definitions.
Associative preloading
A practical issue: MCP Servers typically contain a group of related tools. For example, browser-use Server includes click, fill, navigate, screenshot, and over a dozen other tools. If a user's task involves browser operations, the model likely needs several of them. Loading each individually via LoadMcpTool adds multi-round call overhead.
Borrowing from spatial locality in CPU caches, we added an optimization: when the model loads any tool from a Server, it can optionally preload other high-frequency tools from that same Server.
In practice, a browser task that would have triggered several separate LoadMcpTool calls now typically triggers one.
Test results
Test environment: 67 MCP tools. Task: build a website and test it with browser tools.
Initial context fell by 32%, overall cost by 10.4%, and tool call success rate stayed at 100%.
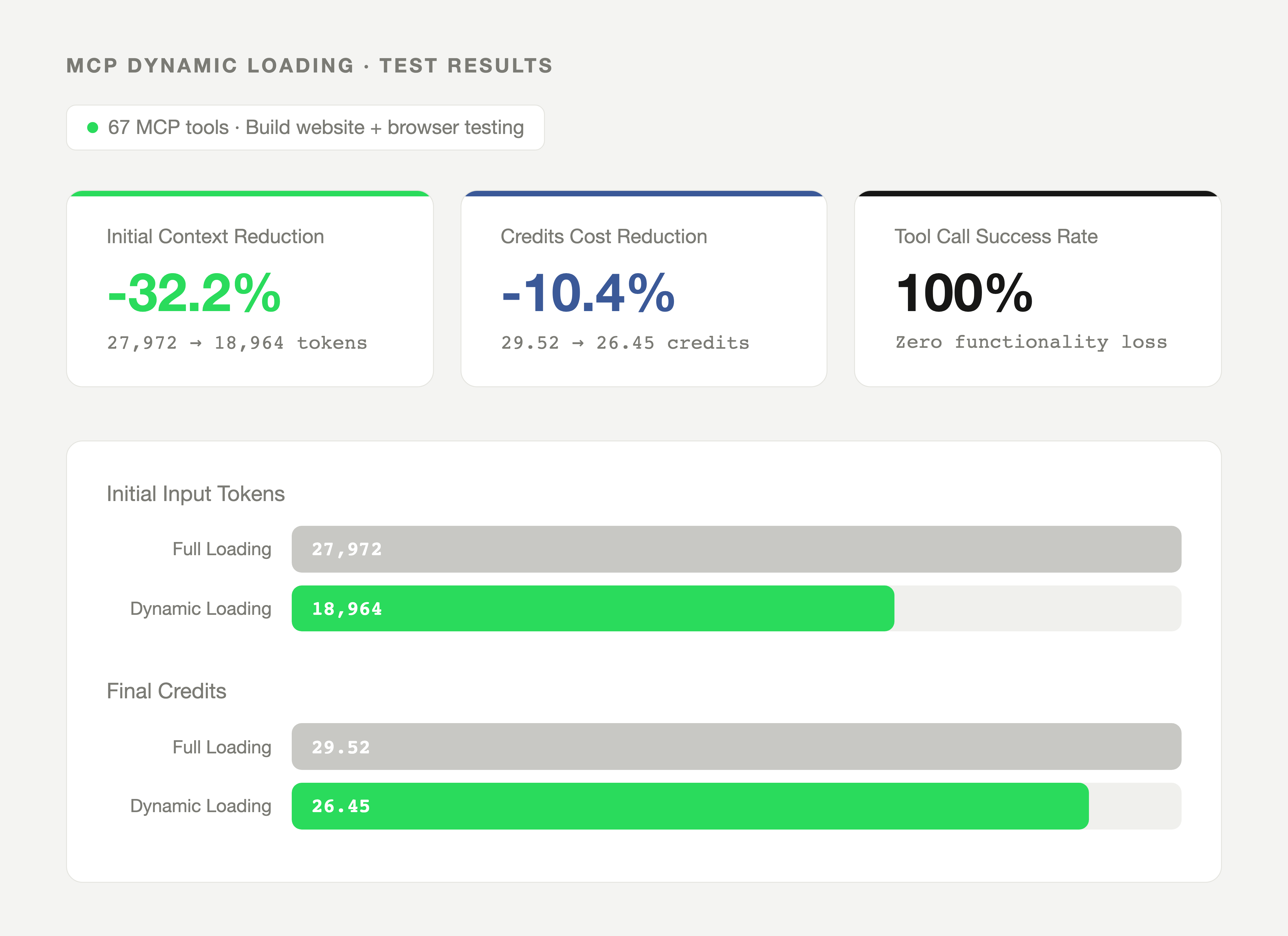
| Metric | Full Loading | Dynamic Loading | Change |
|---|---|---|---|
| Initial Input Tokens | 27,972 | 18,964 | 32.2% |
| Final Credits Consumed | 29.52 | 26.45 | 10.4% |
| MCP Tool Call Success Rate | 100% | 100% | No change |
In retrospect: this is progressive disclosure
After building both optimizations, we stepped back and noticed they were the same solution.
In 1984, IBM researcher John Carroll described Progressive Disclosure: don't show users everything at once. Expose common features first; reveal the rest when they need it. Word's collapsible menus, Notion's / command, iOS's nested settings are all this principle applied to UI.
We'd done the same thing to a context window. A lightweight index up front so the model knows what's available. Full definitions loaded only when needed. The "user" is an AI model and the "interface" is context, but the design problem is identical: feature richness versus cognitive load.
Carroll was solving this in 1984 with command menus. We were solving it forty years later with JSON Schema.
What this means for Qoder Quest users
If you're on Qoder Quest 1.0, this is already live and requires no settings changes. The biggest difference will be visible if you have MCP Servers mounted: tool definitions that ate context every turn now only load when needed. Skills also invoke automatically, so you no longer need to trigger them manually with /skills.
Inspiration for agent builders
These patterns apply beyond Quest. If you're building AI agents:
- Run a token distribution an...
Introducing QoderWork: An AI Assistant That Actually Gets Work Done
desc: QoderWork is a desktop AI assistant that operates directly on your computer
category: Product
img: https://img.alicdn.com/imgextra/i4/O1CN01K21tPZ1NxnTzJ0DfN_!!6000000001637-2-tps-1712-1152.png
time: February 12, 2026 · 3 min read
Most AI assistants live inside a chat window. You ask a question, you get an answer, and then you're back to doing the actual work yourself—opening files, switching between apps, copying and pasting, formatting documents. The AI helped you think, but it didn't help you do.
We built QoderWork to change that.
QoderWork is a desktop AI assistant that operates directly on your computer. It can access your local files, connect to your tools, and execute complete workflows from start to finish. Instead of just answering questions, it sits beside you and helps you get things done.
From Chat to Action
Large language models have proven remarkably capable at understanding and generating text. But for most knowledge workers, the job isn't just about writing—it's about managing files, generating reports, coordinating across tools, and handling the dozens of small tasks that fill a workday.
Traditional AI assistants can help you draft an email. They can't help you open a local spreadsheet, analyze the data, and turn it into a presentation. That gap between "thinking" and "doing" is exactly what QoderWork is designed to bridge.
Our philosophy is simple: AI should work where you work, with your tools, in your way.
What QoderWork Can Do
Work with Your Local Files
QoderWork runs in a local virtual environment with access to folders you authorize. No uploading to the cloud, no copy-pasting back and forth. Tell it what you need, and it works directly in your file system—reading documents, organizing folders, extracting information, generating new files.
Whether it's pulling key clauses from a contract, batch-renaming files, or compiling screenshots into a document, QoderWork handles it. Think of it as a colleague sitting at the desk next to you. Drop a folder on their desk, say "help me sort this out," and it's done.
Generate Professional Documents
This is where QoderWork really shines. Its built-in Skills system produces publication-ready output across common formats: Word documents with proper formatting and structure, Excel spreadsheets with formulas and charts, PowerPoint presentations with thoughtful layouts, and PDFs with full form and page manipulation.
These aren't rough drafts—they're files you can bring to meetings or send to clients. Each format is backed by battle-tested best practices that ensure consistent, professional quality.
Connect Your Tools
Knowledge workers live in a fragmented world of apps—task managers, design tools, team docs, online platforms. Through MCP (Model Context Protocol), QoderWork integrates deeply with the services you already use.
It can check your to-do list, pull design assets, create documents in your team workspace, and orchestrate workflows that span multiple platforms. The real power isn't just automation—QoderWork understands the relationships between your tools and can work across them intelligently. Start with a task, draft the corresponding plan, gather relevant materials, and produce a complete deliverable. All in one flow.
Browse the Web
Sometimes the information you need lives on a webpage. QoderWork includes full browser automation: visiting sites, filling forms, clicking buttons, extracting data, capturing screenshots. Useful for research, testing web applications, scraping structured data, or automating repetitive online tasks.
It runs in its own sandboxed environment—secure and controlled.
Research and Retrieve
Need background for a report? QoderWork can search the web, query academic databases, and compile findings. It handles information gathering so you can focus on analysis and decisions.
Generate Images
When you need a visual, QoderWork can generate images from your description and save them directly to your project folder. Document illustrations, presentation graphics, concept designs—all without switching tools.
How We Think About Security
Giving an AI assistant access to your local files requires careful design. Security isn't a feature we added—it's foundational to how QoderWork works.
Clear permission boundaries. QoderWork only accesses folders you explicitly authorize. It won't wander through your hard drive or read files without your knowledge.
File protection first. When file deletion is needed, QoderWork moves files to a protected recovery area rather than permanently removing them. You always have a way back.
Transparent and traceable. Throughout any task, QoderWork shows you exactly what it's doing through a live progress panel. You see what's happening, what's done, and what's next—no black boxes.
A Real Workflow
Here's what this looks like in practice.
You're a product manager with a review meeting tomorrow. You tell QoderWork: "Help me prepare materials for tomorrow's product review. My project folder has recent user research and competitive analysis. I need a presentation and a detailed report."
QoderWork asks clarifying questions—who's the audience, how many slides, should it include charts? Then it reads your source materials, extracts key insights, and generates a structured PowerPoint deck and a comprehensive Word document. You can watch its progress in real time and adjust direction at any point.
When it's done, the files appear in your folder. Open them and they're ready to use.
Join the Beta
We're opening QoderWork to public beta today because we believe the best products are built with real users solving real problems. This is an early version, and we're eager to learn how you'll use it—and where it falls short.
If you're interested in an AI assistant that goes beyond chat to become a genuine work partner, visit qoder.com/qoderwork to get started.
We can't wait to see what you'll create with it.
QoderWork is now available in public beta on macOS. Windows support coming soon.
Qoder Subscriptions Are Here!
desc: Thanks so much for all your support! Here are our subscription plans.
img: https://img.alicdn.com/imgextra/i4/O1CN013ovXdd1suozbE0qsr_!!6000000005827-2-tps-1712-1152.png
time: September 15, 2025 · 5min read
category: Product
Thank you for your incredible support and engagement with Qoder. Throughout our preview period, we've received a wealth of valuable feedback and encouragement. Your voices have been our guide as we've continuously improved and optimized our features.
We've heard from many of you in the community that you're eager to move beyond the preview's usage limits and use Qoder more freely to accelerate your workflows. To ensure we can sustainably provide a high-quality service for the long term, and after careful consideration, we are excited to introduce our official pricing plans today.
Plans & Pricing
We currently offer two plans to choose from. The paid plan is a monthly subscription, and resource usage in Qoder is measured in Credits. The details of each plan are outlined below.
Your Pro or Pro+ plan quota covers premium model resources equivalent in value to your subscription fee ($20 for Pro and $60 for Pro+) , plus any extra resource bonuses we provide.
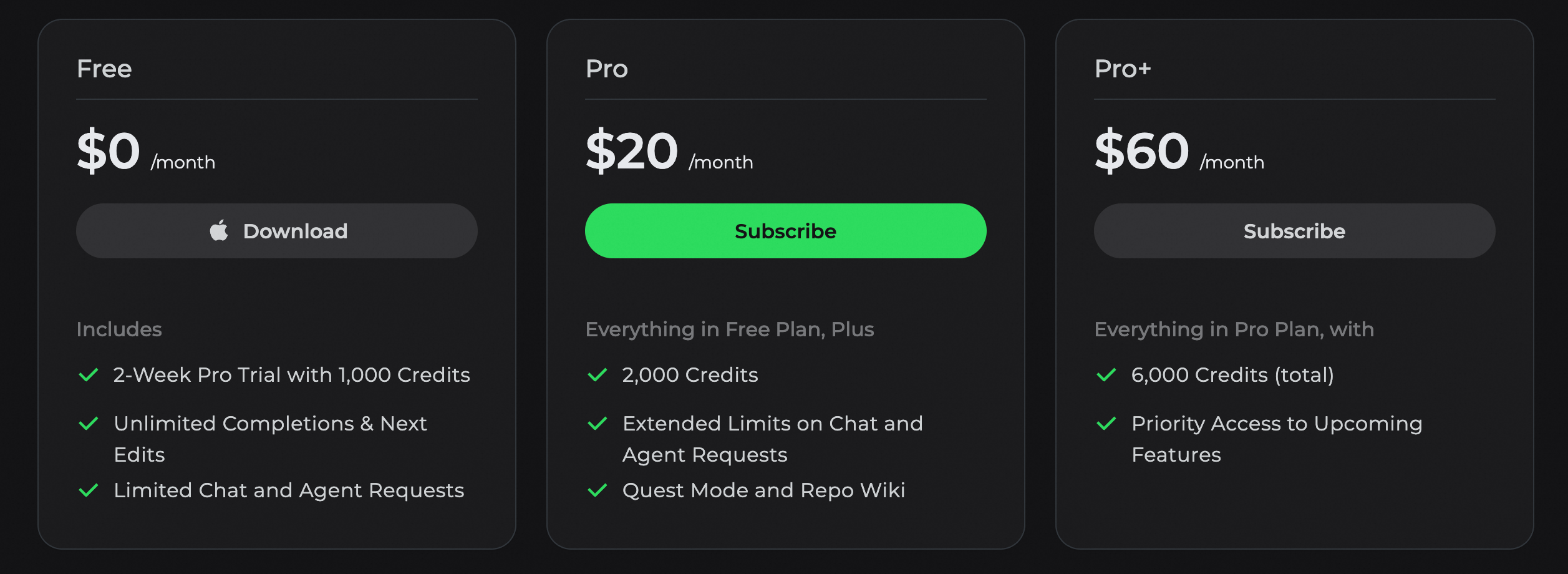
The Pro Plan is ideal for your day-to-day development if you primarily use code completion and light Agent assistance. If you are a heavy user of the Agent for autonomous coding, the Pro+ Plan is designed to better meet your more demanding needs.
We also have a special welcome offer for new users. Upon your first sign-in to Qoder IDE, you'll receive a free 14-day Pro trial and 1,000 credits to explore our Pro Plan features.
For a full breakdown of our plans and pricing, please visit our Pricing page.
Make your Credits go further
Through a series of technical optimizations, we've improved efficiency so you can now complete 130% as many tasks with the same number of Credits.
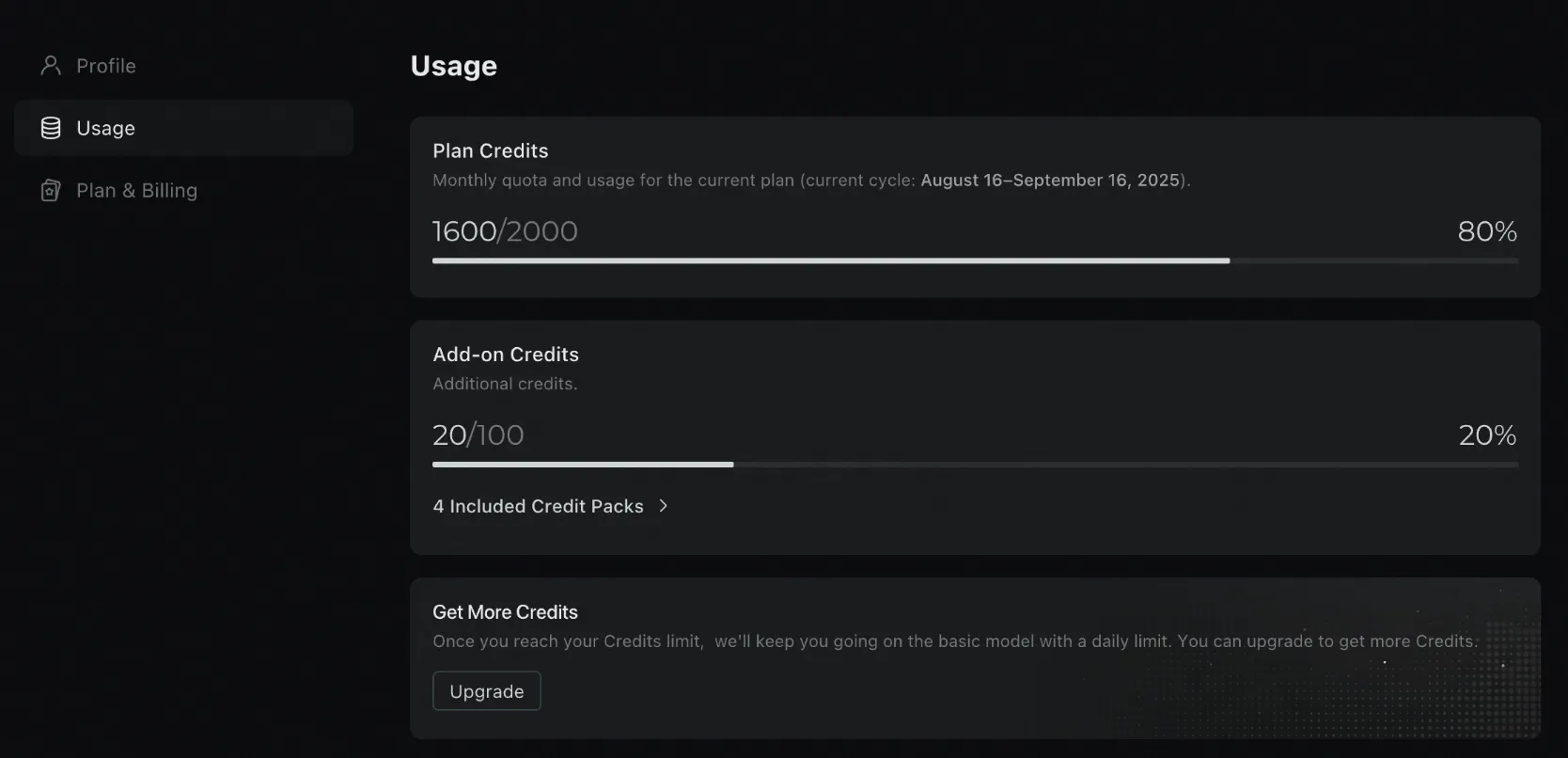
Check your usage at any time
You can view your credits usage for the current subscription period at any time through the Usage page in your personal settings. Different features consume credits at varying rates. See the Credits section for details.
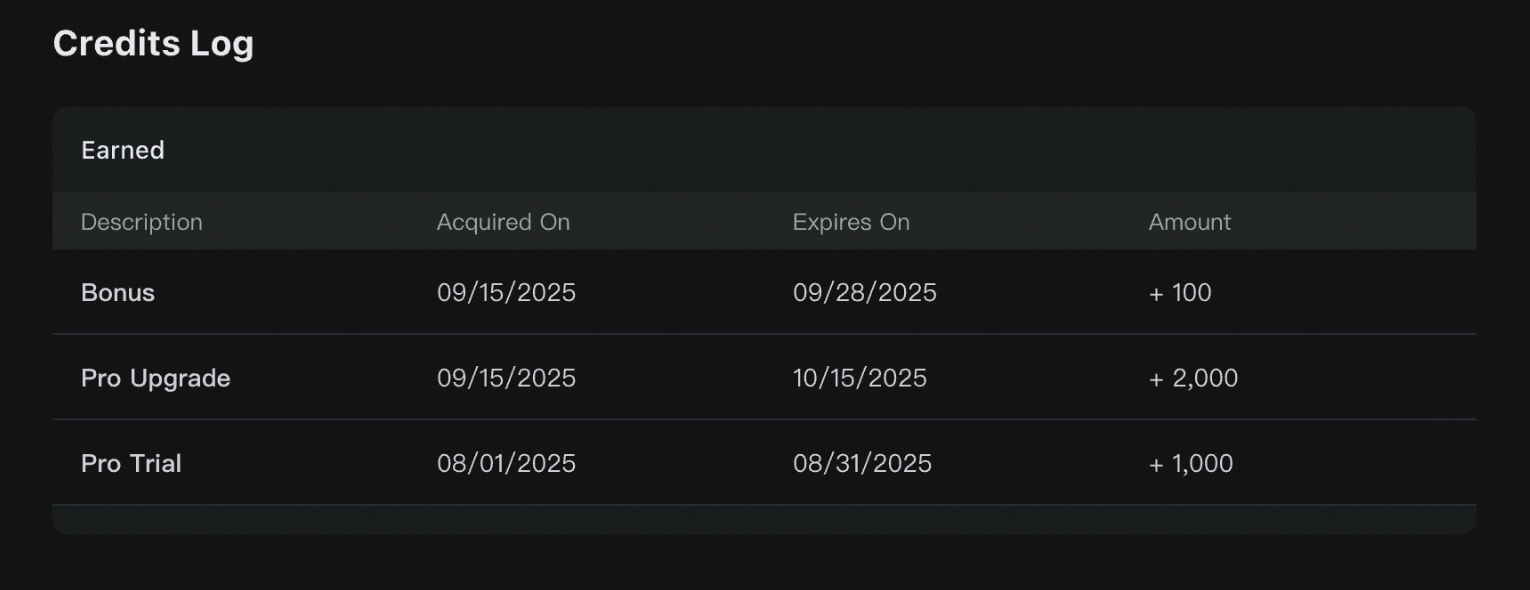
Review your Credits acquisition history
The credits acquisition history provides a comprehensive record of all credits received, including the reason for acquisition, the amount, and the effective and expiration dates. This allows you to easily track your credit sources.
Also, a Credit Usage History feature is launching soon.
Advanced features
Compared to the Free plan, Pro and Pro+ plans support advanced features:
-
Quest Mode: An AI-assisted programming feature designed for task delegation, long-running development tasks. For more information, see Quest Mode.
-
Repo Wiki: Automatically generates structured documentation for your project while continuously tracking code and documentation changes. For more information, see Repo Wiki.
Upgrading your subscription plan
You can upgrade your subscription plan at any time. Any unused credits from your current plan will automatically carry over and won't be lost.
-
Upgrading from Pro Trial: If you upgrade during the trial period, any unused gifted credits will automatically transfer to your account as an add-on pack, maintaining their original expiration date.
-
Upgrading from Pro to Pro+: If you upgrade from Pro to Pro+ mid-subscription, unused credits from your Pro Plan will automatically transfer to your account as an add-on pack, keeping their original expiration date. Your original Pro Plan will immediately become inactive, and your new Pro+ Plan subscription period will begin.
Therefore, you can upgrade at any time without worrying about losing unused credits quota.
Update required: Qoder IDE version 0.2.1 or newer
Please note that Qoder IDE must be updated to version 0.2.1 or higher to function properly. You can either upgrade using the update notification in the top-right corner of the IDE, or download the latest version directly from our downloads page.
FAQ
What happens if I run out of my Credits?
You can upgrade to the Pro or Pro+ plan at any time to get more Credits. If you choose to stay on the Free plan, don't worry—we'll keep you going on the basic model with a daily limit.
What happens if I don't use all my monthly Credits?
Your monthly Credits are refreshed at the start of each billing cycle. Any unused credits from the previous month expire and do not carry over.
Which payment options are available?
We currently accept Visa and Mastercard. More payment methods coming soon.
What happens to accounts created during the preview period?
For accounts that met our trial rules during the preview period, a one-month Pro trial was activated starting from your registration date. Once the trial expires, your account will be automatically downgraded to the Free plan, and any unused Credits will be cleared. You can choose to upgrade to our Pro or Pro+ plans for more resources based on your needs.
Our goal with the free trial is to help everyone easily experience Qoder. To ensure a fair opportunity for all, we will be limiting abuse. Therefore, any Pro trial account created during the preview period that has never been signed into and has not consumed any Credits will be considered inactive. The Credits on these inactive accounts will be uniformly reduced.
For more common questions, please see our FAQ page. If you can't find the answer you're looking for, feel free to contact us at contact@qoder.com.
Qoder Launches Prompt Enhancement Feature
desc: Freeing Developers from the "Prompt Engineering" Burden.
img: https://img.alicdn.com/imgextra/i1/O1CN01QmlmHd24XiOs1BdmN_!!6000000007401-2-tps-1712-1152.png
category: Feature
time: October 22, 2025 · 3min read
In the age of Agentic Coding, developers often face a fundamental challenge: to receive a top-tier answer, you first need a top-tier question. For developers, this means spending significant effort composing and refining prompts for AI. A vague instruction like “Help me write a function” might yield overly simplistic; whereas a detailed, well-structured prompt can unlock robust, production-ready solutions.
Now, Qoder has eliminated this final barrier to developer productivity. The Qoder platform introduces the “One-click Enhancement for Prompts” feature, liberating every developer from the burden of prompt engineering and making Agentic Coding easier and more powerful than ever before.
The Pain Point: When Your Ideas Outpace Your Words
Have you experienced one of these scenarios?
-
Sudden Inspiration, Difficult Expression: You have a complex requirement in mind, but struggle to break it down into steps that the AI can understand.
-
Because the prompt words entered are too simple or not clear enough, the code generated by AI does not meet expectations, leading to repeated trial and error.
-
Knowledge Gaps, Limited Imagination: Uncertain about best practices or secure implementation for a feature, your initial prompts may be flawed or incomplete.
These are precisely the challenges Qoder’s Prompt Enhancement feature is designed to solve.
Solution: One-click Enhancement for Prompts
Qoder’s “One-click Enhancement for Prompts” is a built-in prompt optimization feature. Simply click the “Enhance” button, and Qoder’s backend models instantly interpret and reconstruct your original intent into a structured, precise prompt.
This goes far beyond simple rewriting or synonym expansion. It intelligently upgrades your prompts across several dimensions:
-
Clarifying Requirements: Automatically identifies vague instructions and translates them into actionable, detailed tasks.
Example: Enhancing “Do a sort” to “Write a Python function implementing quicksort for a list of integers, with comprehensive comments, and handling empty lists or duplicates.” -
Contextual Awareness: Leverages current project structure, conversation history, and relevant context as additional input, making the enhanced prompts highly tailored.
-
Comprehensive /Constraints: Fills in commonly overlooked key constraints such as performance considerations, edge cases, error handling, security (e.g., SQL injection prevention), and coding standards (e.g., PEP8).
-
Structured Output: Organizes the enhanced prompt into clear sections like “Objective”, “Inputs/Outputs”, “Constraints”, “Reference Examples”, enabling the AI to parse and execute requests with greater precision.
Demo: Transforming from “Novice” to “Expert” Instantly
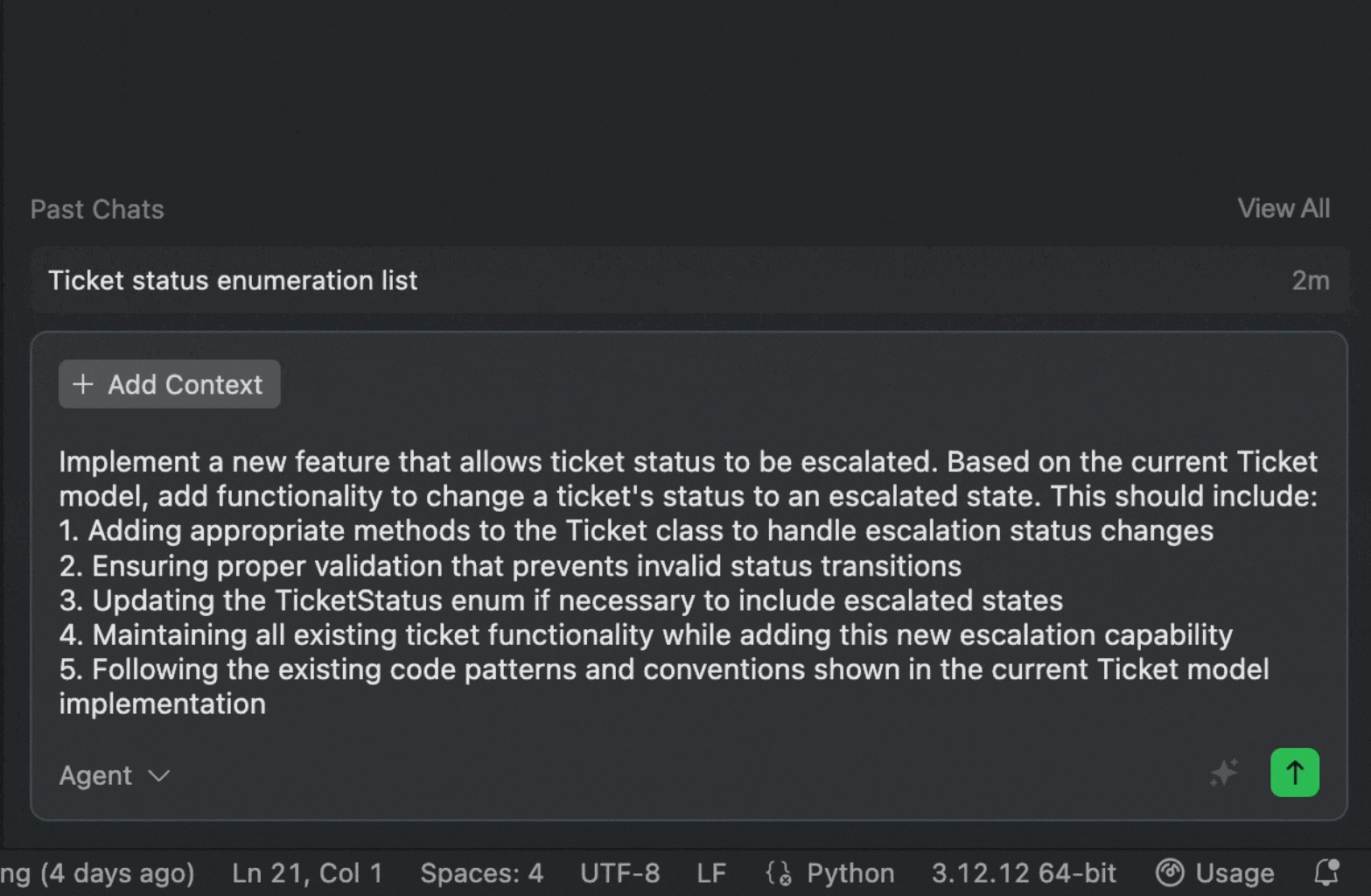
Your initial prompt is:
Add a new feature: ticket status can be changed to escalate
With a single click on “Enhance”, Qoder generates:
[Enhanced Prompt]
Implement a new feature that allows ticket status to be escalated. Based on the current Ticket model, add functionality to change a ticket's status to an escalated state. This should include:
-
Adding appropriate methods to the Ticket class to handle escalation status changes
-
Ensuring proper validation that prevents invalid status transitions
-
Updating the TicketStatus enum if necessary to include escalated states
-
Maintaining all existing ticket functionality while adding this new escalation capability
-
Following the existing code patterns and conventions shown in the current Ticket model implementation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In comparison, the enhanced prompt reads like a complete task specification written by an experienced developer. From this, Qoder Agent can generate ready-to-use, production-grade code.
Tip: Not satisfied with the enhanced prompt? You can easily revert and re-optimize from the bottom-right corner.
Try It Now
With “One-click Enhancement for Prompts,” developers can communicate with AI more effectively. Tool evolution should not increase user burden; instead, it should leverage intelligence to remove friction and empower creativity.
-
Significantly Boost Productivity: Save time spent on refining prompts, allowing you to focus on core logic and architecture.
-
Lower the Learning Curve: Whether you’re a beginner or a seasoned expert, this feature helps you unlock AI’s full potential for higher-quality code.
-
Learn Best Practices: By observing enhanced prompts, you can quickly learn how to clearly translate complex requirements for AI, improving your technical specification and communication skills.
Experience Qoder now—click the magical “Enhance” button and feel the quantum leap in AI-driven coding productivity!
The Next Evolution Toward Intelligent Editing: Qoder NEXT Model and ActionRL Preference Alignment in Practice
desc: From "Code Completion" to "Edit Prediction": Understanding the Capabilities and Advantages of the Qoder NEXT Model
category: Product
img: https://img.alicdn.com/imgextra/i2/O1CN01EUNmOu1x2Nzu5tRuw_!!6000000006385-2-tps-1712-1152.png
time: January 6, 2026
{kind=link}
Introduction: From "Code Completion" to "Edit Suggestion"
Over the past two years, Large Language Models (LLMs) have fundamentally reshaped software development workflows. Paradigms like Agentic Coding now allow developers to rapidly generate repo-level code from high-level directives, significantly accelerating development velocity. However, a growing sentiment in the developer community characterizes this shift as the rise of the "AI Cleanup Engineer": while Agentic Coding can swiftly automate the initial 80% of a task, the remaining 20%—involving logical calibration, boundary handling, cross-module coordination, and engineering refinement—often requires manual human intervention.
Despite this evolution, traditional code completion tools remain confined to the Fill-In-the-Middle (FIM) paradigm. These models typically operate by predicting a contiguous code span at the cursor position based solely on local context, lacking a holistic understanding of editing intent. This single-step, static approach falls short in real-world scenarios—such as multi-line modifications, function refactoring, or cross-file dependency adjustments—and fails to support coherent, structured sequences of development actions.
To address this limitation, we introduce an end-to-end framework built on three pillars:
-
Cold-start training via precise simulation of real-world edit trajectories using Abstract Syntax Trees (ASTs);
-
A data flywheel that captures editing behavior from high-exploration deployments of prototype models; and
-
ActionRL, a novel preference alignment algorithm that ensures deep alignment with developer intent at the level of sequential decision-making.
Breaking Free from FIM: Edit Trajectory Simulation via AST Parsing
Traditional FIM training typically involves randomly masking spans of code and prompting the model to reconstruct them. While effective for simple completion, this method captures only the static probability distribution of code, not the dynamic logic of software modification.
Qoder NEXT moves beyond random masking. Instead, we leverage Abstract Syntax Trees (ASTs) to reverse-engineer realistic edit trajectories, enabling the model to learn how edits unfold—not just what the final code looks like..
Structured Intent Abstraction
In practice, a single developer intent typically triggers a cascade of coordinated changes. Using an AST parser (like Tree-sitter), we mine high-quality repositories to automatically reconstruct these operation chains.
Consider identifier renaming —a canonical example of a structured edit that differs fundamentally from a naive find-and-replace:
-
Trigger Action: Locate the definition of an identifier (variable, function, or class) and simulate a user-initiated rename.
-
Ripple Effect: Use AST-based scope analysis to identify all dependent references.
-
Trajectory Construction: Serialize these changes into a coherent, linear sequence:
[Edit Action 1] -> [Edit Action 2] -> ...
Simulating Complex Real-World Edits
Beyond renaming, Qoder NEXT’s cold-start corpus includes diverse, advanced editing patterns that teach the model complex structural transformations:
-
Signature Change: Adding a parameter to a function definition triggers automatic updates at all call sites—inserting placeholders or inferring compatible local variables.
-
Logic Extraction: A code block is refactored into a new function or variable, and the original segment is replaced with an invocation.
-
Type Refinement: Transitioning from an abstract interface to a concrete implementation.
-
Method Override: When a new method is added to a superclass or interface, the model synthesizes valid overrides in relevant subclasses.
-
Error Refactoring: Code flagged as erroneous by the Language Server Protocol (LSP) is automatically corrected into a logically valid alternative.
-
Automatic Import: Unimported types, functions, or constants trigger the insertion of appropriate import statements, respecting project-specific conventions.
Through this rigorous AST-based simulation, Qoder NEXT learns causally dependent edits during pre-training—laying a foundation for multi-line, semantically aware editing.
Building a Data Flywheel: From Prototype Models to Preference Capture
While static simulation effectively addresses the cold-start problem (the "zero-to-one" phase), real-world development environments exhibit stochasticity and nuance that synthetic data alone cannot replicate. Understanding long-horizon edit trajectories—and, critically, why developers reject certain suggestions—requires authentic user interaction data.
High-Exploration Interaction Design
We integrated the Qoder NEXT prototype into an IDE component that performs continuous inference. As the developer edits, the model predicts the next likely action and proactively surfaces potential follow-up edits. This design yields high-fidelity behavioral logs (collected under strict privacy protocols), categorized into three feedback signals:
-
Explicit Accept: User accepts the full suggestion sequence (via the
Tabkey). -
Partial Edit: User accepts theinitial actions but manually modifies later steps.
-
Explicit Reject: User dismisses the suggestion (using
Esc) or ignores it.
Signal Collection and Preference Modeling
Interaction logs are annotated into structured tuples:
(Context, Response_Accepted 1, Response_Accepted 2, ..., Response_Rejected 1, Response_Rejected 2, ...)
Unlike conventional approaches that overfit to positive examples, Qoder NEXT treats rejection signals as high-value data. For instance, if the model suggests obj.getName() but the user corrects it to obj.getDisplayName(), this reveals a gap in the model’s understanding of domain-specific semantics. Capturing such preference divergences is essential for aligning the model with human intent.
Overcoming Alignment Challenges: The Emergence of ActionRL
Traditional Reinforcement Learning from Human Feedback (RLHF) algorithms suffer from critical flaws when applied to sequential editing. Positive and negative trajectories are often highly entangled, requiring a more granular approach to loss computation.
"Over-Suppression" Induced by Sequence Coupling
In code editing, accepted $y^w$ and rejected $y^l$ trajectories frequently share long, identical prefixes. Consider:
-
Context:
user = User.find(id) -
User’s intent
$y^w$ :user.update(name: "New"); user.save(); print("Done"); -
Model’s prediction
$y^l$ :user.update(name: "New"); user.delete(); print("Done");
Only the second action diverges (.save() versus .delete()); the rest is correct.
● Limitation of Naive Alignment: Treats
● Consequence: The model becomes overly conservative, suppressing valid sub-actions out of fear that a downstream error might invalidate the whole trajectory—a phenomenon we call "Over-Suppression."
ActionRL: Fine-Grained Preference Optimization
To address this, we propose ActionRL, an alignment algorithm designed specifically for sequential editing. Its core innovation: shift the learning objective from ranking full trajectories to optimizing the decision boundary at the first point of divergence.
Locating the Critical Divergence Action
Given a preference group (one accepted trajectory, multiple rejected ones), ActionRL aligns all sequences action-by-action to identify the Behavioral Divergence Point (BDP)—the first step where choices differ. Since the context before the BDP is identical, any performance gap stems solely from the action taken at that point.
Truncated Likelihood Estimation
Instead of computing loss over the entire sequence, ActionRL localizes optimization to the conditional distribution at the BDP. It maximizes the margin between the chosen action $y^w_{t^}$ and rejected alternatives $y^l_{t^}$ , conditioned on the shared history, while detaching gradients for all subsequent tokens. This ensures learning signals target only the critical decision node.
Loss Function Restructuring
Rejected trajectories often contain syntactically valid suffixes after the error. ActionRL eliminates this noise by strictly truncating loss computation at the BDP. This guarantees:
-
Divergence-point penalty: The shared prefix $y_{<t^}$ is neutral (or masked); only the erroneous action $y^l_{t^}$ is penalized.
-
Noise Filtration**:** Actions after $t^*$ —even if valid—are excluded from loss calculation, preventing misleading negative signals.
Experimental Results and Engineering Insights
In practice, Qoder NEXT demonstrates significantly enhanced adaptability. After ActionRL alignment, key metrics show marked improvement:
Model Performance Gains
-
>53% increase in code generation ratio.
-
Strong execution consistency: The model now treats refactoring as an atomic process—once an edit chain begins, it completes it reliably, drastically reducing "half-finished" suggestions.
These technical gains translate directly into user value:
-
65% higher acceptance rates
-
Steady improvement in fine-grained inference accuracy
This confirms Qoder NEXT’s reliability in handli...